3.2 Peptides and Proteins
We now turn to polymers of amino acids, the peptides and proteins. Biologically occurring polypeptides range in size from small, consisting of two or three linked amino acid residues, to very large, consisting of thousands of residues.
Peptides Are Chains of Amino Acids
Two amino acid molecules can be covalently joined through a substituted amide linkage, termed a peptide bond, to yield a dipeptide. Such a linkage is formed by removal of the elements of water (dehydration) — a hydroxyl moiety from the α-carboxyl group of one amino acid and a hydrogen atom the α-amino group of another (Fig. 3-13). The joined amino acids are referred to as residues, the part left over after the elements of water are removed. Peptide bond formation is an example of a condensation reaction, a common class of reactions in living cells. The reverse reaction, bond breakage involving water, is an example of hydrolytic cleavage or hydrolysis. Under standard biochemical conditions, the equilibrium for the reaction shown in Figure 3-13 favors the hydrolysis of the dipeptide into amino acids. To make the condensation reaction thermodynamically more favorable, the carboxyl group must be chemically modified or activated so that the hydroxyl group can be more readily eliminated. A chemical approach to this problem is outlined later in this chapter. The biological approach to peptide bond formation is a major topic of Chapter 27.
 Two amino acid molecules can be covalently joined through a substituted amide linkage, termed a
Two amino acid molecules can be covalently joined through a substituted amide linkage, termed a 
FIGURE 3-13 Formation of a peptide bond by condensation. The α-amino group of one amino acid (with the group) acts as a nucleophile to displace the hydroxyl group of another amino acid (with the group), forming a peptide bond (shaded in light red). Amino groups are good nucleophiles, but the hydroxyl group is a poor leaving group and is not readily displaced. At physiological pH, the reaction shown here does not occur to any appreciable extent.
Three amino acids can be joined by two peptide bonds to form a tripeptide; similarly, four amino acids can be linked to form a tetrapeptide, five to form a pentapeptide, and so forth. When a few amino acids are joined in this fashion, the structure is called an oligopeptide. When many amino acids are joined, the product is called a polypeptide. Proteins may have thousands of amino acid residues. Although the terms “protein” and “polypeptide” are sometimes used interchangeably, molecules referred to as polypeptides generally have molecular weights below 10,000, and those called proteins have higher molecular weights.
Figure 3-14 shows the structure of a pentapeptide. In a peptide, the amino acid residue at the end with a free α-amino group is the amino-terminal (or N-terminal) residue; the residue at the other end, which has a free carboxyl group, is the carboxyl-terminal (C-terminal) residue.
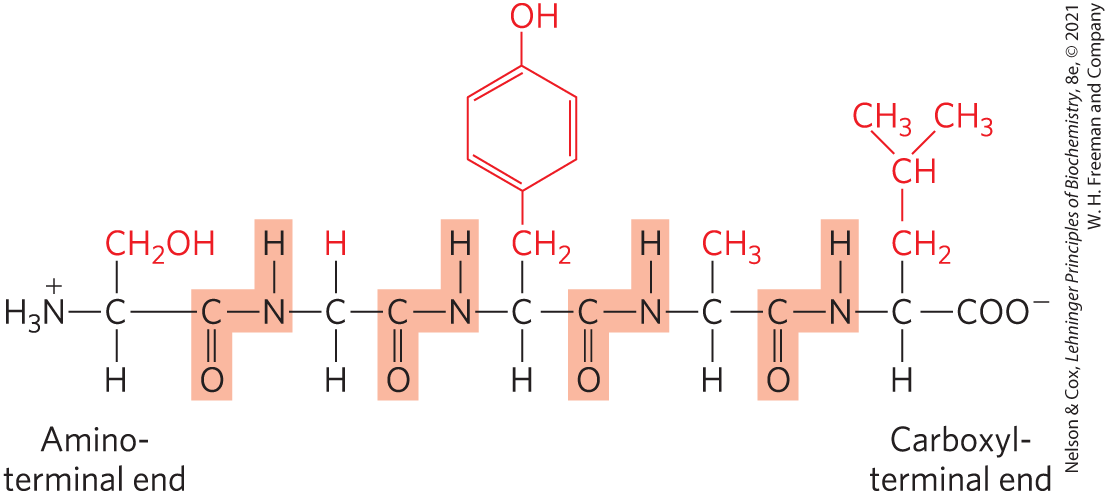
FIGURE 3-14 The pentapeptide serylglycyltyrosylalanylleucine, Ser–Gly–Tyr–Ala–Leu, or SGYAL. Peptides are named beginning with the amino-terminal residue, which by convention is placed at the left. The peptide bonds are shaded in light red; the R groups are in red.
Key convention
When an amino acid sequence of a peptide, a polypeptide, or a protein is displayed, the amino-terminal end is placed on the left and the carboxyl-terminal end is placed on the right. The sequence is read from left to right, beginning with the amino-terminal end.

Although hydrolysis of a peptide bond is an exergonic reaction, it occurs only slowly because it has a high activation energy (p. 25). As a result, the peptide bonds in proteins are quite stable, with an average half-life of about 7 years under most intracellular conditions.
Peptides Can Be Distinguished by Their Ionization Behavior
Peptides contain only one free α-amino group and one free α-carboxyl group, at opposite ends of the chain (Fig. 3-15). These groups ionize as they do in free amino acids. The α-amino and α-carboxyl groups of all nonterminal amino acids are covalently joined in the peptide bonds. They can no longer ionize and thus do not contribute to the total acid-base behavior of peptides. Ionizable R groups in a peptide (Table 3-1) also contribute to the overall acid-base properties of the molecule (Fig. 3-15).
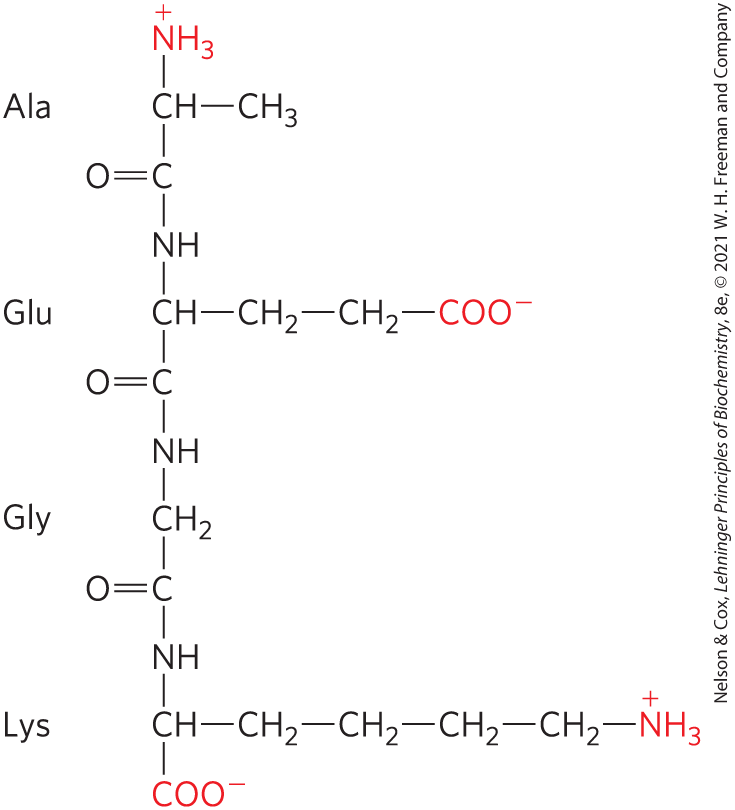
FIGURE 3-15 Alanylglutamylglycyllysine. This tetrapeptide has one free α-amino group, one free α-carboxyl group, and two ionizable R groups. The groups ionized at pH 7.0 are in red.
Like free amino acids, peptides have characteristic titration curves and a characteristic isoelectric pH (pI) at which the net charge is zero and they do not move in an electric field. These properties are exploited in some of the techniques used to separate peptides and proteins, as we describe later in the chapter. When an amino acid becomes a residue in a peptide, its chemical environment is altered, and the value for an ionizable R group can change somewhat. The values for R groups listed in Table 3-1 can be a useful guide to the pH range in which a given group will ionize, but they cannot be strictly applied when an amino acid becomes part of a peptide.
Biologically Active Peptides and Polypeptides Occur in a Vast Range of Sizes and Compositions
No generalizations can be made about the molecular weights of biologically active peptides and proteins in relation to their functions. Naturally occurring peptides range in length from two to many thousands of amino acid residues. Even the smallest peptides can have biologically important effects. Consider the commercially synthesized dipeptide l-aspartyl-l-phenylalanine methyl ester, the artificial sweetener better known as aspartame or NutraSweet.
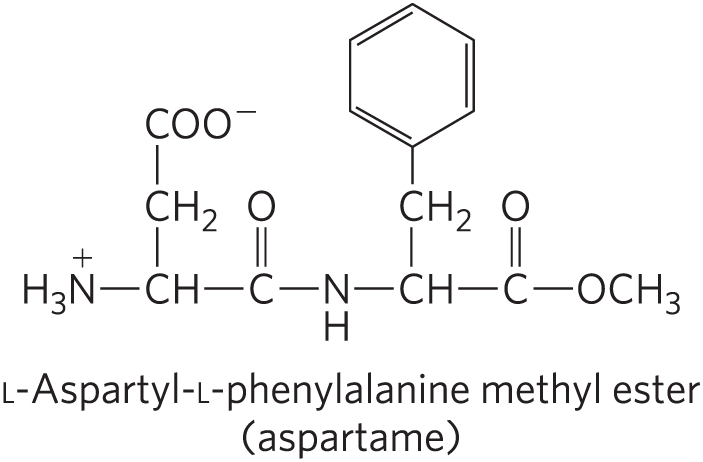
Many small peptides exert their effects at very low concentrations. For example, a number of vertebrate hormones (Chapter 23) are small peptides. These include oxytocin (nine amino acid residues), which is secreted by the posterior pituitary gland and stimulates uterine contractions, and thyrotropin-releasing factor (three residues), which is formed in the hypothalamus and stimulates the release of another hormone, thyrotropin, from the anterior pituitary gland. Some extremely toxic mushroom poisons, such as amanitin, are also small peptides, as are many antibiotics.
How long are the polypeptide chains in proteins? As Table 3-2 shows, lengths vary considerably. Human cytochrome c has 104 amino acid residues linked in a single chain; bovine chymotrypsinogen has 245 residues. At the extreme is titin, a constituent of vertebrate muscle, which has nearly 27,000 amino acid residues and a molecular weight of about 3,000,000. The vast majority of naturally occurring proteins are much smaller than this, containing fewer than 2,000 amino acid residues.
| Protein | Molecular weight | Number of residues | Number of polypeptide chains |
|---|---|---|---|
Cytochrome c (human) |
12,400 |
104 |
1 |
Myoglobin (equine heart) |
16,700 |
153 |
1 |
Chymotrypsin (bovine pancreas) |
25,200 |
241 |
3 |
Hemoglobin (human) |
64,500 |
574 |
4 |
Hexokinase (yeast) |
107,900 |
972 |
2 |
RNA polymerase (E. coli) |
450,000 |
4,158 |
5 |
Glutamine synthetase (E. coli) |
619,000 |
5,628 |
12 |
Titin (human) |
2,993,000 |
26,926 |
1 |
Some proteins consist of a single polypeptide chain, but others, called multisubunit proteins, have two or more polypeptides associated noncovalently (Table 3-2). The individual polypeptide chains in a multisubunit protein may be identical or different. If at least two are identical the protein is said to be oligomeric, and the identical units (consisting of one or more polypeptide chains) are referred to as protomers. Hemoglobin, for example, has four polypeptide subunits: two identical α chains and two identical β chains, all four held together by noncovalent interactions. Each α subunit is paired in an identical way with a β subunit within the structure of this multisubunit protein, so that hemoglobin can be considered either a tetramer of four polypeptide subunits or a dimer of αβ protomers.
A few proteins contain two or more polypeptide chains linked covalently. For example, the two polypeptide chains of insulin are linked by disulfide bonds. In such cases, the individual polypeptides are not considered subunits; instead they are commonly referred to simply as chains.
The amino acid composition of proteins is also highly variable. The 20 common amino acids almost never occur in equal amounts in a protein. Some amino acids may occur only once or not at all in a given type of protein; others may occur in large numbers. Table 3-3 shows the amino acid composition of bovine cytochrome c and chymotrypsinogen, the inactive precursor of the digestive enzyme chymotrypsin. These two proteins, with very different functions, also differ significantly in the relative numbers of each kind of amino acid residue.
| Bovine cytochrome c | Bovine chymotrypsinogen | |||
|---|---|---|---|---|
| Amino acid | Number of residues per molecule | Percentage of totala | Number of residues per molecule | Percentage of totala |
Ala |
6 |
6 |
22 |
9 |
Arg |
2 |
2 |
4 |
1.6 |
Asn |
5 |
5 |
14 |
5.7 |
Asp |
3 |
3 |
9 |
3.7 |
Cys |
2 |
2 |
10 |
4 |
Gln |
3 |
3 |
10 |
4 |
Glu |
9 |
9 |
5 |
2 |
Gly |
14 |
13 |
23 |
9.4 |
His |
3 |
3 |
2 |
0.8 |
Ile |
6 |
6 |
10 |
4 |
Leu |
6 |
6 |
19 |
7.8 |
Lys |
18 |
17 |
14 |
5.7 |
Met |
2 |
2 |
2 |
0.8 |
Phe |
4 |
4 |
6 |
2.4 |
Pro |
4 |
4 |
9 |
3.7 |
Ser |
1 |
1 |
28 |
11.4 |
Thr |
8 |
8 |
23 |
9.4 |
Trp |
1 |
1 |
8 |
3.3 |
Tyr |
4 |
4 |
4 |
1.6 |
Val |
3 |
3 |
23 |
9.4 |
Total |
104 |
102a |
245 |
99.7a |
|
Note: In some common analyses, such as acid hydrolysis, Asp and Asn are not readily distinguished from each other and are together designated Asx (or B). Similarly, when Glu and Gln cannot be distinguished, they are together designated Glx (or Z). In addition, Trp is destroyed by acid hydrolysis. Additional procedures must be employed to obtain an accurate assessment of complete amino acid content. aPercentages do not total to 100%, due to rounding. |
||||
We can estimate the number of amino acid residues in a simple protein containing no other chemical constituents by dividing its molecular weight by 110. Although the average molecular weight of the 20 common amino acids is about 138, the smaller amino acids predominate in most proteins. If we take into account the proportions in which the various amino acids occur in an average protein (Table 3-1; the averages are determined by surveying the amino acid compositions of more than 1,000 different proteins), the average molecular weight of protein amino acids is nearer to 128. Because a molecule of water is removed to create each peptide bond, the average molecular weight of an amino acid residue in a protein is about 128 − 18 = 110.
Some Proteins Contain Chemical Groups Other Than Amino Acids
Many proteins — for example, the enzymes ribonuclease A and chymotrypsin — contain only amino acid residues and no other chemical constituents. However, some proteins contain permanently associated chemical components in addition to amino acids; these are called conjugated proteins. The non–amino acid part of a conjugated protein is usually called its prosthetic group. Conjugated proteins are classified on the basis of the chemical nature of their prosthetic groups (Table 3-4); for example, lipoproteins contain lipids, glycoproteins contain sugar groups, and metalloproteins contain a specific metal. Some proteins contain more than one prosthetic group. Usually the prosthetic group plays an important role in the protein’s biological function.
| Class | Prosthetic group | Example |
|---|---|---|
Lipoproteins |
Lipids |
-Lipoprotein of blood (Fig. 17-2) |
Glycoproteins |
Carbohydrates |
Immunoglobulin G (Fig. 5-20) |
Phosphoproteins |
Phosphate groups |
Glycogen phosphorylase (Fig. 6-39) |
Hemoproteins |
Heme (iron porphyrin) |
|
Flavoproteins |
Flavin nucleotides |
Succinate dehydrogenase (Fig. 19-9) |
Metalloproteins |
Iron Zinc Calcium Molybdenum Copper |
Ferritin (Box 16-1) Alcohol dehydrogenase (Fig. 14-12) Calmodulin (Fig. 12-17) Dinitrogenase (Fig. 22-3) Complex IV (Fig. 19-12) |
SUMMARY 3.2 Peptides and Proteins
- Amino acids can be joined covalently through peptide bonds to form peptides and proteins. Cells generally contain thousands of different proteins, each with a different biological activity.
- The ionization behavior of peptides reflects their ionizable side chains as well as the terminal α-amino and α-carboxyl groups.
- Proteins can be very long polypeptide chains of 100 to several thousand amino acid residues. However, some naturally occurring peptides have only a few amino acid residues. Some proteins are composed of several noncovalently associated polypeptide chains, called subunits.
- Simple proteins yield only amino acids on hydrolysis; conjugated proteins contain in addition some other component, such as a metal or organic prosthetic group.
 Amino acids can be joined covalently through peptide bonds to form peptides and proteins. Cells generally contain thousands of different proteins, each with a different biological activity.
Amino acids can be joined covalently through peptide bonds to form peptides and proteins. Cells generally contain thousands of different proteins, each with a different biological activity.