3.1 Amino Acids
Proteins are polymers of amino acids, with each amino acid residue joined to its neighbor by a specific type of covalent bond. (The term “residue” reflects the loss of the elements of water when one amino acid is joined to another.) Proteins can be broken down (hydrolyzed) to their constituent amino acids by a variety of methods, and the earliest studies of proteins naturally focused on the free amino acids derived from them. Twenty different amino acids are commonly found in proteins. The first to be discovered was asparagine, in 1806. The last of the 20 to be found, threonine, was not identified until 1938. All the amino acids have trivial or common names, in some cases derived from the source from which they were first isolated. Asparagine was first found in asparagus, and glutamate in wheat gluten; tyrosine was first isolated from cheese (its name is derived from the Greek tyros, “cheese”); glycine (Greek glykos, “sweet”) was so named because of its sweet taste.
Learning the names, structures, and chemical properties of the 20 common amino acids found in proteins is one of the key memorization trials of every beginning biochemistry student. The necessity rapidly becomes apparent in succeeding chapters. It is impossible to discuss protein structure, protein function, ligand-binding sites, enzyme active sites, and most other biochemical topics without this foundation. The amino acids are part of the biochemistry vocabulary.
Amino Acids Share Common Structural Features
All 20 of the common amino acids are α-amino acids. They have a carboxyl group and an amino group bonded to the same carbon atom (the α carbon) (Fig. 3-2). They differ from each other in their side chains, or R groups, which vary in structure, size, and electric charge, and which influence the solubility of the amino acids in water. In addition to these 20 amino acids, there are many less common ones. Some are residues modified after a protein has been synthesized, others are amino acids present in living organisms but not as constituents of proteins, and two are special cases found in just a few proteins. The common amino acids of proteins have been assigned three-letter abbreviations and one-letter symbols (see Table 3-1), which are used as shorthand to indicate the composition and sequence of amino acids polymerized in proteins.
 All 20 of the common amino acids are α-amino acids. They have a carboxyl group and an amino group bonded to the same carbon atom (the α carbon) (
All 20 of the common amino acids are α-amino acids. They have a carboxyl group and an amino group bonded to the same carbon atom (the α carbon) (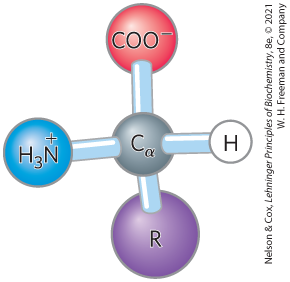
FIGURE 3-2 General structure of an amino acid. This structure is common to all but one of the α-amino acids. (Proline, a cyclic amino acid, is the exception.) The R group, or side chain (purple), attached to the α carbon (gray) is different in each amino acid.
Key convention
The three-letter code is easily understood, the abbreviations generally consisting of the first three letters of the amino acid name. The one-letter code was devised by Margaret Oakley Dayhoff, considered by many to be the founder of the field of bioinformatics. The one-letter code reflects an attempt to reduce the size of the data files (in an era of limited computer memory) used to describe amino acid sequences. It was designed to be easily memorized, and understanding its origin can help students do just that. For six amino acids (CHIMSV), the first letter of the amino acid name is unique and thus is used as the symbol. For five others (AGLPT), the first letter of the name is not unique but is assigned to the amino acid that is most common in proteins (for example, leucine is more common than lysine). For another four, the letter used is phonetically suggestive (RFYW: aRginine, Fenylalanine, tYrosine, tWiptophan). The rest were harder to assign. Four (DNEQ) were assigned letters found within or suggested by their names (asparDic, asparagiNe, glutamEke, Q-tamine). That left lysine. Only a few letters were left, and K was chosen because it was the closest to L.


Margaret Oakley Dayhoff, 1925–1983
For all the common amino acids except glycine, the α carbon is bonded to four different groups: a carboxyl group, an amino group, an R group, and a hydrogen atom (Fig. 3-2; in glycine, the R group is another hydrogen atom). The α-carbon atom is thus a chiral center (p. 61). Because of the tetrahedral arrangement of the bonding orbitals around the α-carbon atom, the four different groups can occupy two unique spatial arrangements, and thus amino acids have two possible stereoisomers. Since they are nonsuperposable mirror images of each other (Fig. 3-3), the two forms represent a class of stereoisomers called enantiomers (see Fig. 1-21). All molecules with a chiral center are also optically active — that is, they rotate the plane of plane-polarized light (see Box 1-2).
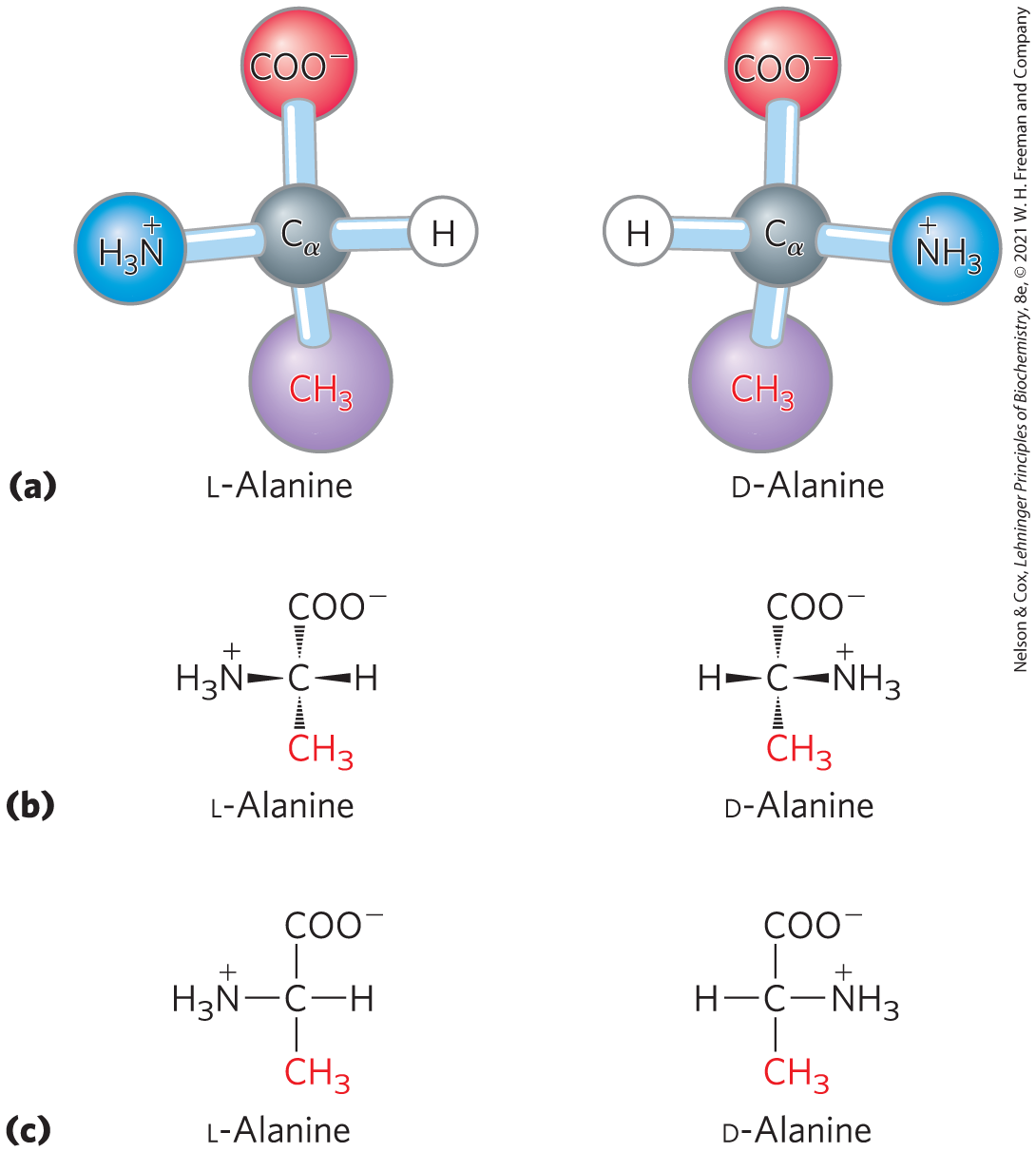
FIGURE 3-3 Stereoisomerism in α-amino acids. (a) The two stereoisomers of alanine, l- and d-alanine, are nonsuperposable mirror images of each other (enantiomers). (b, c) Two different conventions for showing the configurations in space of stereoisomers. In perspective formulas (b), the solid wedge-shaped bonds project out of the plane of the paper, the dashed bonds behind it. In projection formulas (c), the horizontal bonds are assumed to project out of the plane of the paper, the vertical bonds behind. However, projection formulas are often used casually and are not always intended to portray a specific stereochemical configuration. See Figure 3-4 for an explanation of the d, l-system for specifying absolute configuration.
Key convention
Two conventions are used to identify the carbons in an amino acid — a practice that can be confusing. The additional carbons in an R group are commonly designated β, γ, δ, ε, and so forth, proceeding out from the α carbon. For most other organic molecules, carbon atoms are simply numbered from one end, giving highest priority (C-1) to the carbon with the substituent containing the atom of highest atomic number. Within this latter convention, the carboxyl carbon of an amino acid would be C-1 and the α carbon would be C-2.
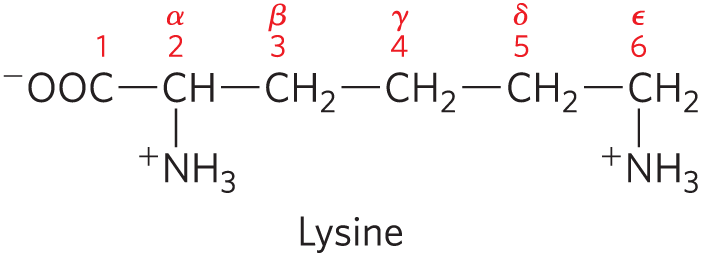
In cases such as amino acids with heterocyclic R groups (e.g., histidine), where the Greek lettering system is ambiguous, the numbering system is used. For branched amino acid side chains, equivalent carbons are given numbers after the Greek letters. Leucine thus has δ1 and δ2 carbons (see the structure in Fig. 3-5).
Special nomenclature has been developed to specify the absolute configuration of the four substituents of asymmetric carbon atoms. The absolute configurations of simple sugars and amino acids are specified by the d, l system (Fig. 3-4), based on the absolute configuration of the three-carbon sugar glyceraldehyde, a convention proposed by Emil Fischer in 1891. (Fischer knew what groups surrounded the asymmetric carbon of glyceraldehyde but had to guess at their absolute configuration; he guessed right, as was later confirmed by x-ray diffraction analysis.) For all chiral compounds, stereoisomers having a configuration related to that of l-glyceraldehyde are designated l, and stereoisomers related to d-glyceraldehyde are designated d. The functional groups of l-alanine are matched with those of l-glyceraldehyde by aligning those that can be interconverted by simple, one-step chemical reactions. Thus the carboxyl group of l-alanine occupies the same position about the chiral carbon as does the aldehyde group of l-glyceraldehyde, because an aldehyde is readily converted to a carboxyl group via a one-step oxidation. Historically, the similar l and d designations were used for levorotatory (rotating plane-polarized light to the left) and dextrorotatory (rotating light to the right). However, not all l-amino acids are levorotatory, and the convention shown in Figure 3-4 was needed to avoid potential ambiguities about absolute configuration. By Fischer’s convention, l and d refer only to the absolute configuration of the four substituents around the chiral carbon, not to optical properties of the molecule.

FIGURE 3-4 Steric relationship of the stereoisomers of alanine to the absolute configuration of l- and d-glyceraldehyde. In these perspective formulas, the carbons are lined up vertically, with the chiral atom in the center. The carbons in these molecules are numbered beginning with the terminal aldehyde or carboxyl carbon (red), 1 to 3 from top to bottom as shown. When presented in this way, the R group of the amino acid (in this case the methyl group of alanine) is always below the α carbon. l-Amino acids are those with the α-amino group on the left, and d-amino acids have the α-amino group on the right.
Another system of specifying configuration around a chiral center is the RS system, which is used in the systematic nomenclature of organic chemistry and describes more precisely the configuration of molecules with more than one chiral center (p. 17).
The Amino Acid Residues in Proteins Are l Stereoisomers
Nearly all biological compounds with a chiral center occur naturally in only one stereoisomeric form, either d or l. The amino acid residues in protein molecules are almost all l stereoisomers, with less than 1% being found in the d-configuration. The rare d-amino acid residues generally have a precise structural purpose, and they are introduced to a protein by enzyme-catalyzed reactions that occur after the proteins are synthesized on a ribosome.
It is remarkable that virtually all amino acid residues in proteins are l stereoisomers. When chiral compounds are formed by ordinary chemical reactions, the result is a racemic mixture of d and l isomers, which are difficult for a chemist to distinguish and separate. But to a living system, d and l isomers are as different as the right hand and the left. The formation of stable, repeating substructures in proteins (Chapter 4) requires that their constituent amino acids be of one stereochemical series. Cells are able to specifically synthesize the l isomers of amino acids because the active sites of enzymes are asymmetric, causing the reactions they catalyze to be stereospecific.
Amino Acids Can Be Classified by R Group
Knowledge of the chemical properties of the common amino acids is central to an understanding of biochemistry. The topic can be simplified by grouping the amino acids into five main classes based on the properties of their R groups (Table 3-1), particularly their polarity, or tendency to interact with water at biological pH (near pH 7.0). The polarity of the R groups varies widely, from nonpolar and hydrophobic (water-insoluble) to highly polar and hydrophilic (water-soluble). A few amino acids — especially glycine, histidine, and cysteine — are somewhat difficult to characterize or do not fit perfectly in any one group. They are assigned to particular groupings based on considered judgments rather than absolutes.
| values | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Amino acid | Abbreviation/symbol | a | (—COOH) | () | (R group) | pI | Hydropathy indexb | Occurrence in proteins (%)c | ||
| Nonpolar, aliphatic R groups | ||||||||||
Glycine |
Gly G |
75 |
2.34 |
9.60 |
5.97 |
−0.4 |
7.2 |
7.3 |
7.3 |
|
Alanine |
Ala A |
89 |
2.34 |
9.69 |
6.01 |
1.8 |
7.8 |
9.4 |
7.2 |
|
Proline |
Pro P |
115 |
1.99 |
10.96 |
6.48 |
−1.6d |
5.2 |
4.4 |
4.2 |
|
Valine |
Val V |
117 |
2.32 |
9.62 |
5.97 |
4.2 |
6.6 |
7.1 |
8.2 |
|
Leucine |
Leu L |
131 |
2.36 |
9.60 |
5.98 |
3.8 |
9.1 |
10.6 |
9.9 |
|
Isoleucine |
Ile I |
131 |
2.36 |
9.68 |
6.02 |
4.5 |
5.3 |
6.0 |
7.6 |
|
Methionine |
Met M |
149 |
2.28 |
9.21 |
5.74 |
1.9 |
2.3 |
2.2 |
2.2 |
|
| Aromatic R groups | ||||||||||
Phenylalanine |
Phe F |
165 |
1.83 |
9.13 |
5.48 |
2.8 |
3.9 |
4.0 |
4.5 |
|
Tyrosine |
Tyr Y |
181 |
2.20 |
9.11 |
10.07 |
5.66 |
−1.3 |
3.2 |
3.0 |
3.9 |
Tryptophan |
Trp W |
204 |
2.38 |
9.39 |
5.89 |
−0.9 |
1.4 |
1.3 |
1.1 |
|
| Polar, uncharged R groups | ||||||||||
Serine |
Ser S |
105 |
2.21 |
9.15 |
5.68 |
−0.8 |
6.8 |
6.1 |
5.7 |
|
Threonine |
Thr T |
119 |
2.11 |
9.62 |
5.87 |
−0.7 |
5.9 |
5.4 |
4.5 |
|
Cysteinee |
Cys C |
121 |
1.96 |
10.28 |
8.18 |
5.07 |
2.5 |
1.9 |
1.2 |
0.8 |
Asparagine |
Asn N |
132 |
2.02 |
8.80 |
5.41 |
−3.5 |
4.3 |
3.7 |
3.4 |
|
Glutamine |
Gln Q |
146 |
2.17 |
9.13 |
5.65 |
−3.5 |
4.2 |
4.5 |
2.0 |
|
| Positively charged R groups | ||||||||||
Lysine |
Lys K |
146 |
2.18 |
8.95 |
10.53 |
9.74 |
−3.9 |
5.9 |
4.7 |
6.8 |
Histidine |
His H |
155 |
1.82 |
9.17 |
6.00 |
7.59 |
−3.2 |
2.3 |
2.4 |
1.6 |
Arginine |
Arg R |
174 |
2.17 |
9.04 |
12.48 |
10.76 |
−4.5 |
5.1 |
5.6 |
5.9 |
| Negatively charged R groups | ||||||||||
Aspartate |
Asp D |
133 |
1.88 |
9.60 |
3.65 |
2.77 |
−3.5 |
5.3 |
5.1 |
5.0 |
Glutamate |
Glu E |
147 |
2.19 |
9.67 |
4.25 |
3.22 |
−3.5 |
6.3 |
6.0 |
8.2 |
|
||||||||||
The structures of the 20 common amino acids are shown in Figure 3-5, and some of their properties are listed in Table 3-1. Within each class there are gradations of polarity, size, and shape of the R groups.
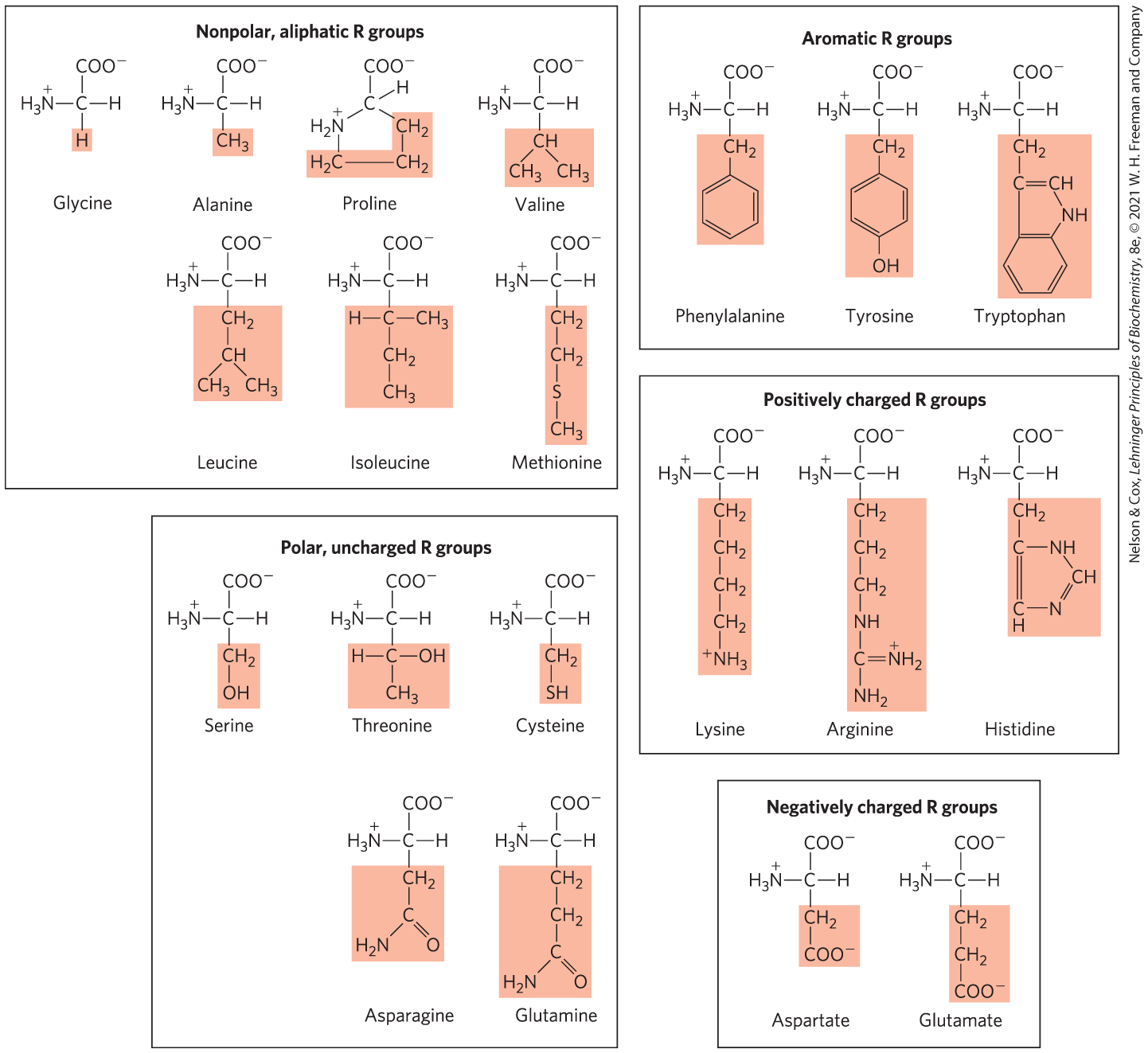
FIGURE 3-5 The 20 common amino acids of proteins. The structural formulas show the state of ionization that would predominate at pH 7.0. The unshaded portions are those that are common to all the amino acids; the shaded portions are the R groups. Although the R group of histidine is shown uncharged, its (see Table 3-1) is such that a small but significant fraction of these groups are positively charged at pH 7.0. The protonated form of histidine is shown above the graph in Figure 3-12b.
Nonpolar, Aliphatic R Groups The R groups in this class of amino acids are nonpolar and hydrophobic. The side chains of alanine, valine, leucine, and isoleucine tend to cluster together within proteins, stabilizing protein structure through the hydrophobic effect. Glycine has the simplest structure. Although it is most easily grouped with the nonpolar amino acids, its very small side chain makes no real contribution to interactions driven by the hydrophobic effect. Methionine, one of the two sulfur-containing amino acids, has a slightly nonpolar thioether group in its side chain. Proline has an aliphatic side chain with a distinctive cyclic structure. The secondary amino (imino) group of proline residues is held in a rigid conformation that reduces the structural flexibility of polypeptide regions containing proline.
Aromatic R Groups Phenylalanine, tyrosine, and tryptophan, with their aromatic side chains, are relatively nonpolar (hydrophobic). All can contribute to the hydrophobic effect. The hydroxyl group of tyrosine can form hydrogen bonds, and it is an important functional group in some enzymes. Tyrosine and tryptophan are significantly more polar than phenylalanine because of the tyrosine hydroxyl group and the nitrogen of the tryptophan indole ring.
Tryptophan and tyrosine, and to a much lesser extent phenylalanine, absorb ultraviolet light (Fig. 3-6; see also Box 3-1). This accounts for the characteristic strong absorbance of light by most proteins at a wavelength of 280 nm, a property exploited by researchers in the characterization of proteins.
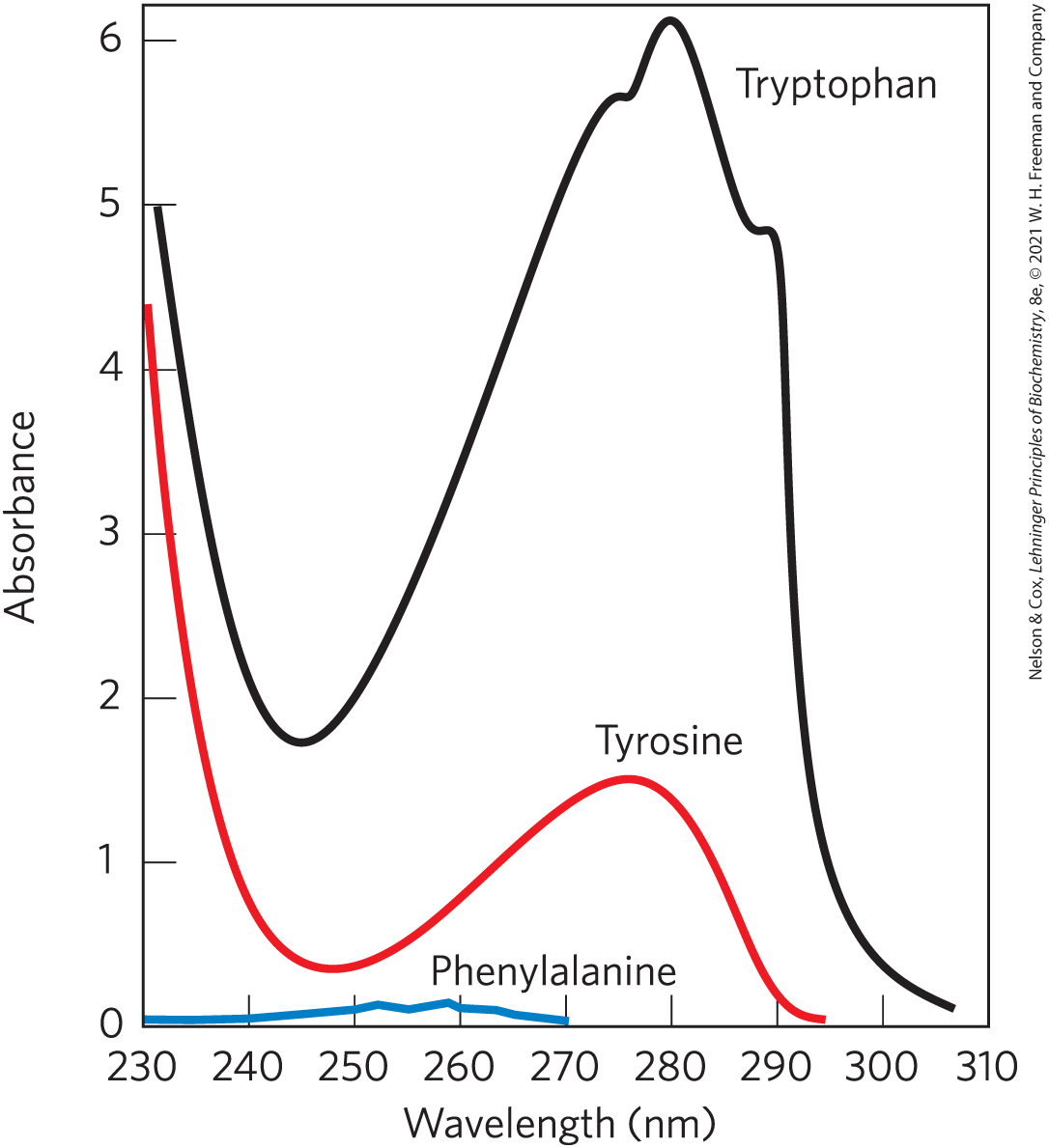
FIGURE 3-6 Absorption of ultraviolet light by aromatic amino acids. Comparison of the light absorption spectra of the aromatic amino acids tryptophan, tyrosine, and phenylalanine at pH 6.0. The amino acids are present in equimolar amounts under identical conditions. The measured absorbance of tryptophan is more than four times that of tyrosine at a wavelength of 280 nm. Note that the maximum light absorption for both tryptophan and tyrosine occurs near 280 nm. Light absorption by phenylalanine generally contributes little to the spectroscopic properties of proteins.
Polar, Uncharged R Groups The R groups of these amino acids are more soluble in water, or more hydrophilic, than those of the nonpolar amino acids because they contain functional groups that form hydrogen bonds with water. This class of amino acids includes serine, threonine, cysteine, asparagine, and glutamine. The polarity of serine and threonine is contributed by their hydroxyl groups, and the polarity of asparagine and glutamine is contributed by their amide groups. Cysteine is an outlier here because its polarity, contributed by its sulfhydryl group, is quite modest. Cysteine is a weak acid and can make weak hydrogen bonds with oxygen or nitrogen.
Asparagine and glutamine are the amides of two other amino acids also found in proteins — aspartate and glutamate, respectively — to which asparagine and glutamine are easily hydrolyzed by acid or base. Cysteine is readily oxidized to form a covalently linked dimeric amino acid called cystine, in which two cysteine molecules or residues are joined by a disulfide bond (Fig. 3-7). The disulfide-linked residues are strongly hydrophobic (nonpolar). Disulfide bonds play a special role in the structures of many proteins by forming covalent links between parts of a polypeptide molecule or between two different polypeptide chains.
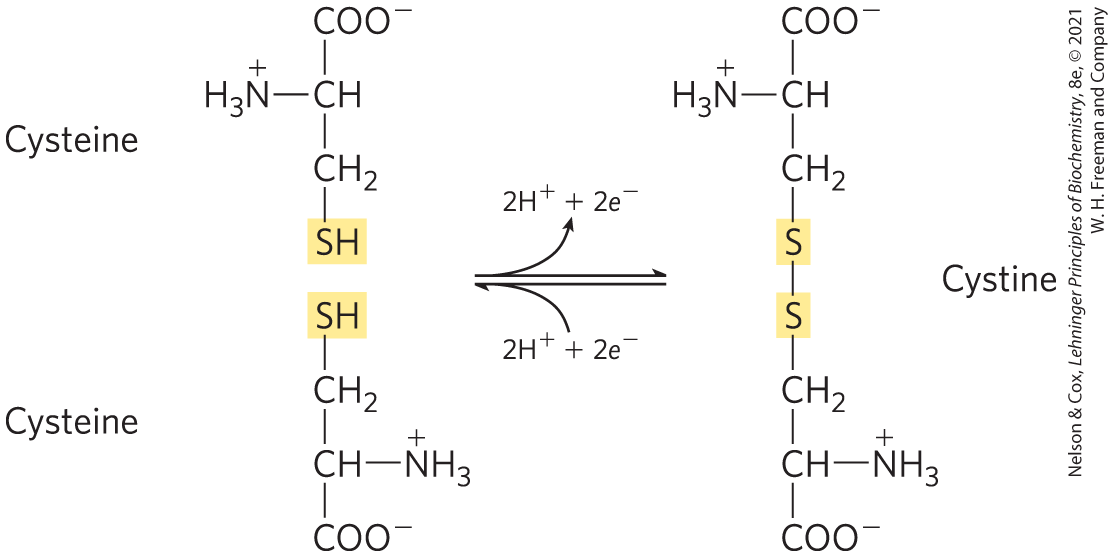
FIGURE 3-7 Reversible formation of a disulfide bond by the oxidation of two molecules of cysteine. Disulfide bonds between Cys residues stabilize the structures of many proteins.
Positively Charged (Basic) R Groups The most hydrophilic R groups are those that are either positively charged or negatively charged. The amino acids in which the R groups have significant positive charge at pH 7.0 are lysine, which has a second primary amino group at the ε position on its aliphatic chain; arginine, which has a positively charged guanidinium group; and histidine, which has an aromatic imidazole group. As the only common amino acid having an ionizable side chain with near neutrality, histidine may be positively charged (protonated form) or uncharged at pH 7.0. His residues facilitate many enzyme-catalyzed reactions by serving as proton donors/acceptors.
Negatively Charged (Acidic) R Groups The two amino acids having R groups with a net negative charge at pH 7.0 are aspartate and glutamate, each of which has a second carboxyl group.
Uncommon Amino Acids Also Have Important Functions
In addition to the 20 common amino acids, proteins may contain residues created by modification of common residues already incorporated into a polypeptide — that is, through postsynthetic modification (Fig. 3-8a). Among these uncommon amino acids are 4-hydroxyproline, a derivative of proline found in the fibrous protein collagen, and γ-carboxyglutamate, found in the blood-clotting protein prothrombin and in certain other proteins that bind as part of their biological function. More complex is desmosine, a derivative of four Lys residues, which is found in the fibrous protein elastin.
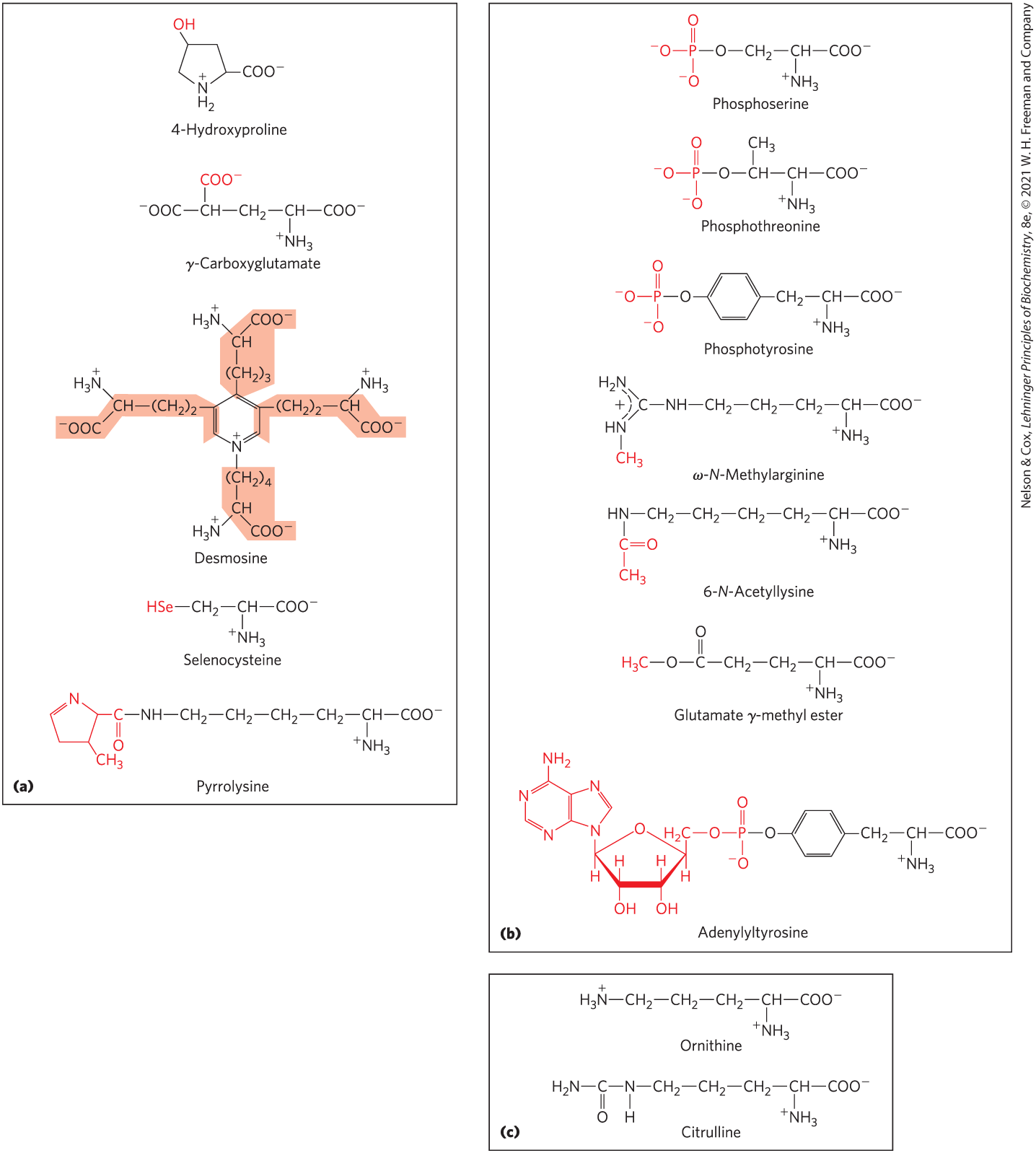
FIGURE 3-8 Uncommon amino acids. (a) Some uncommon amino acids found in proteins. Most are derived from common amino acids. (Note the use of either numbers or Greek letters in the names of these structures to identify the altered carbon atoms.) Extra functional groups added by modification reactions are shown in red. Desmosine is formed from four Lys residues (the carbon backbones are shaded in light red). Selenocysteine and pyrrolysine are exceptions: these amino acids are added during normal protein synthesis through a highly specialized expansion of the standard genetic code. Both are found in very small numbers of proteins. (b) Reversible amino acid modifications involved in regulation of protein activity. Phosphorylation is the most common type of regulatory modification. (c) Ornithine and citrulline, which are not found in proteins, are intermediates in the biosynthesis of arginine and in the urea cycle.
Selenocysteine and pyrrolysine are special cases. These rare amino acid residues are not created through a postsynthetic modification. Instead, they are introduced during protein synthesis through an unusual adaptation of the genetic code, which we describe in Chapter 27. Selenocysteine contains selenium rather than the sulfur of cysteine. Actually derived from serine, selenocysteine is a constituent of just a few known proteins. Pyrrolysine is found in a few proteins in several methanogenic (methane-producing) archaea and in one known bacterium; it plays a role in methane biosynthesis.
Some amino acid residues in a protein may be modified transiently to alter the protein’s function. The addition of phosphoryl, methyl, acetyl, adenylyl, ADP-ribosyl, or other groups to particular amino acid residues can increase or decrease a protein’s activity (Fig. 3-8b). Phosphorylation is a particularly common regulatory modification. Covalent modification as a protein regulatory strategy is discussed in more detail in Chapter 6.
Some 300 additional amino acids have been found in cells. They have a variety of functions, but not all are constituents of proteins. Ornithine and citrulline (Fig. 3-8c) deserve special note because they are key intermediates (metabolites) in the biosynthesis of arginine (Chapter 22) and in the urea cycle (Chapter 18).
Amino Acids Can Act as Acids and Bases
The amino and carboxyl groups of amino acids, along with the ionizable R groups of some amino acids, function as weak acids and bases. When an amino acid lacking an ionizable R group is dissolved in water at neutral pH, the α-amino and carboxyl groups create a dipolar ion, or zwitterion (German for “hybrid ion”), which can act as either an acid or a base (Fig. 3-9). Substances having this dual (acid-base) nature are amphoteric and are often called ampholytes (from “amphoteric electrolytes”). A simple monoamino monocarboxylic α-amino acid, such as alanine, is a diprotic acid when fully protonated; it has two groups, the group and the group, that can yield protons:
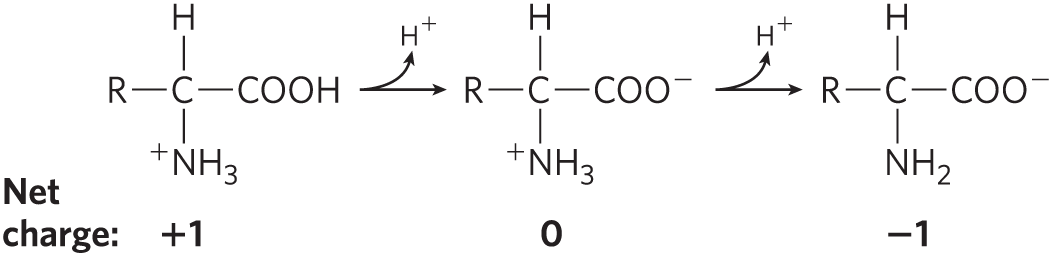
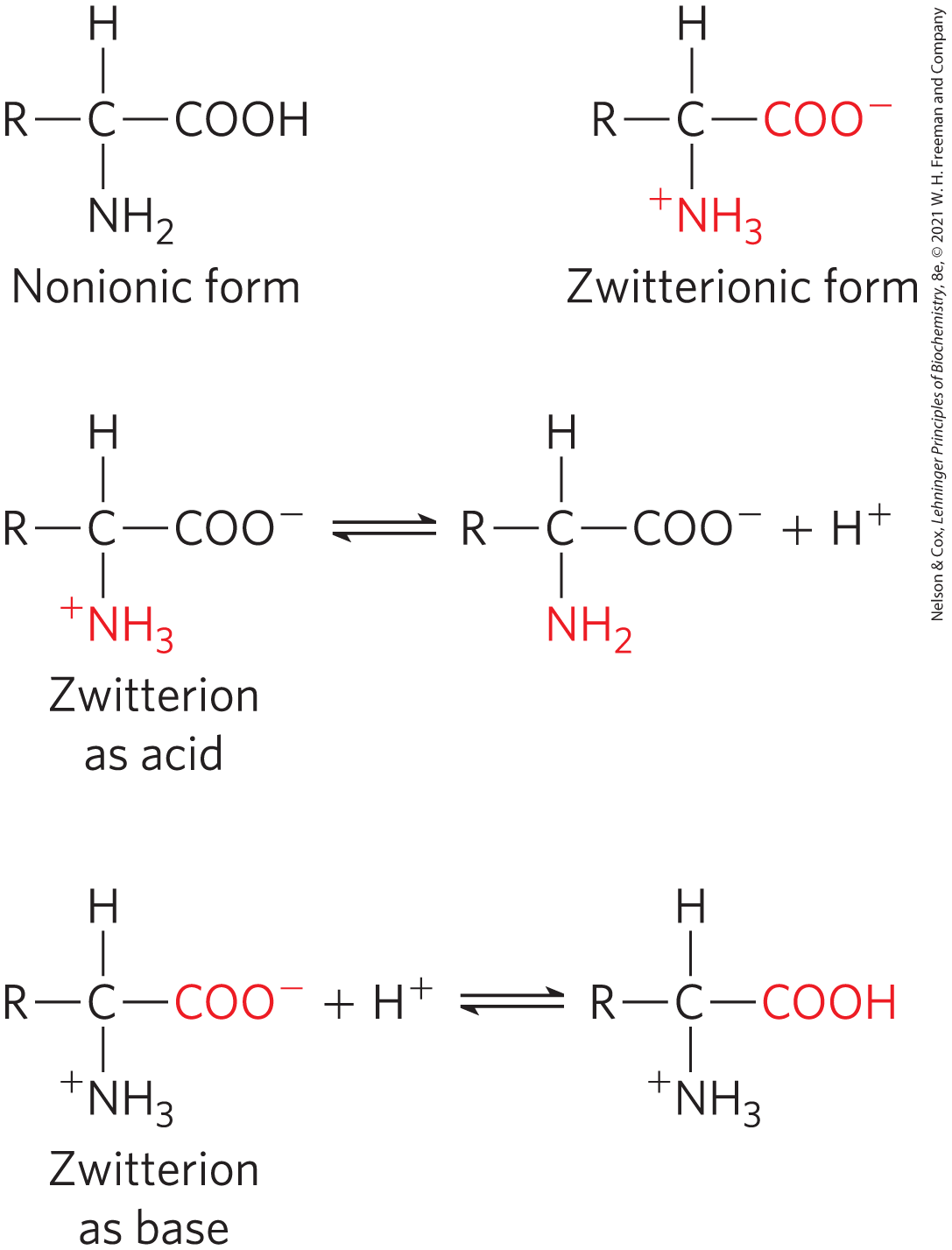
FIGURE 3-9 Nonionic and zwitterionic forms of amino acids. The nonionic form does not occur in significant amounts in aqueous solutions. The zwitterion predominates at neutral pH. A zwitterion can act as either an acid (proton donor) or a base (proton acceptor).
Acid-base titration involves the gradual addition or removal of protons (Chapter 2). Figure 3-10 shows the titration curve of the diprotic form of glycine. The two ionizable groups of glycine, the carboxyl group and the amino group, are titrated with a strong base such as NaOH. The plot has two distinct stages, corresponding to deprotonation of two different groups on glycine. Each of the two stages resembles in shape the titration curve of a monoprotic acid, such as acetic acid (see Fig. 2-16), and can be analyzed in the same way. At very low pH, the predominant ionic species of glycine is the fully protonated form, .
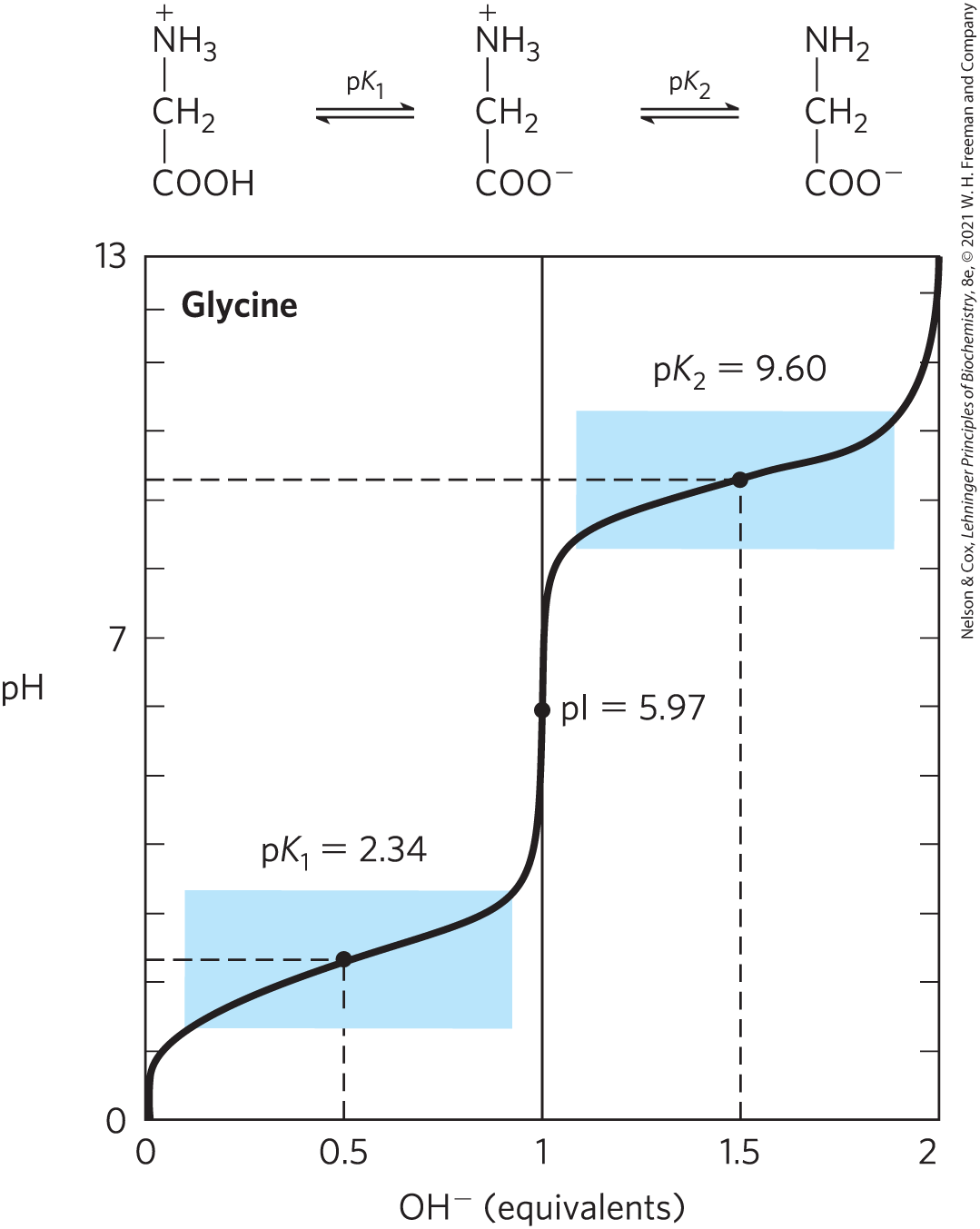
FIGURE 3-10 Titration of amino acids. The titration curve of 0.1 M glycine at . The ionic species predominating at key points in the titration are shown above the graph. The shaded boxes, centered at about and indicate the regions of greatest buffering power. Note that 1 equivalent of NaOH added. The pI occurs at the arithmetic mean between the two values, and it corresponds to the inflection point in the titration.
In the first stage of the titration, the group of glycine (with its lower ) loses its proton. At the midpoint of this stage, equimolar concentrations of the proton-donor and the proton-acceptor species are present. As in the titration of any weak acid, a point of inflection is reached at this midpoint where the pH is equal to the of the protonated group that is being titrated (see Fig. 2-17). For glycine, the pH at the midpoint is 2.34; thus its group has a (labeled in Fig. 3-10) of 2.34. (Recall from Chapter 2 that pH and are simply convenient notations for proton concentration and the equilibrium constant for ionization, respectively. The is a measure of the tendency of a group to give up a proton, with that tendency decreasing 10-fold as the increases by one unit.) As the titration of glycine proceeds, another point of inflection is reached at pH 5.97; at this point, removal of the first proton is essentially complete and removal of the second has just begun. At this pH, glycine is present largely as the dipolar ion (zwitterion) . We shall return to the significance of this inflection point in the titration curve (labeled pI in Fig. 3-10) shortly.
The second stage of the titration corresponds to the removal of a proton from the group of glycine. The pH at the midpoint of this stage is 9.60, equal to the (labeled in Fig. 3-10) for the group. The titration is essentially complete at a pH of about 12, at which point the predominant form of glycine is .
From the titration curve of glycine we can derive several important pieces of information. First, it gives a quantitative measure of the of each of the two ionizing groups: 2.34 for the group and 9.60 for the group. Note that the carboxyl group of glycine is over 100 times more acidic (more easily ionized) than the carboxyl group of acetic acid, which, as we saw in Chapter 2, has a of 4.76 — about average for a carboxyl group attached to an otherwise unsubstituted aliphatic hydrocarbon. The perturbed of glycine is caused primarily by the nearby positively charged amino group on the α-carbon atom, an electronegative group that tends to pull electrons toward it (a process called electron withdrawal), as described in Figure 3-11. The opposite charges on the resulting zwitterion are also somewhat stabilizing. Similarly, the of the amino group in glycine is perturbed downward relative to the average of an amino group. This effect is due largely to electron withdrawal by the electronegative oxygen atoms in the carboxyl groups, increasing the tendency of the amino group to give up a proton. Hence, the α-amino group has a that is lower than that of an aliphatic amine such as methylamine (Fig. 3-11). In short, the of any functional group is greatly affected by its chemical environment, a phenomenon sometimes exploited in the active sites of enzymes to promote exquisitely adapted reaction mechanisms that depend on the perturbed values of proton donor/acceptor groups of specific residues.
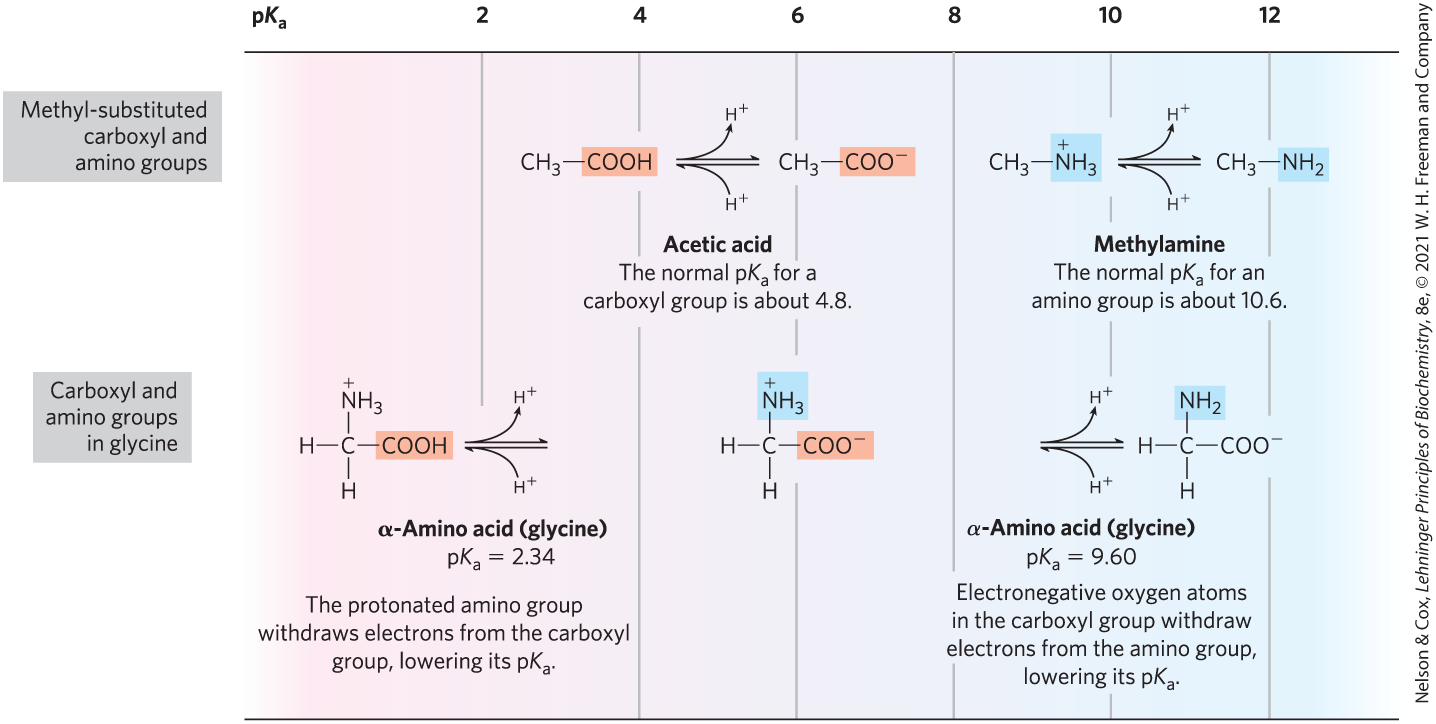
FIGURE 3-11 Effect of the chemical environment on . The values for the ionizable groups in glycine are lower than those for simple, methyl-substituted amino and carboxyl groups. These downward perturbations of are due to intramolecular interactions. Similar effects can be caused by chemical groups that happen to be positioned nearby — for example, in the active site of an enzyme.
The second piece of information provided by the titration curve of glycine is that this amino acid has two regions of buffering power. One of these is the relatively flat portion of the curve, extending for approximately 1 pH unit on either side of the first of 2.34, indicating that glycine is a good buffer near this pH. The other buffering zone is centered around pH 9.60. (Note that glycine is not a good buffer at the pH of intracellular fluid or blood, about 7.4.) Within the buffering ranges of glycine, the Henderson-Hasselbalch equation (p. 60) can be used to calculate the proportions of proton-donor and proton-acceptor species of glycine required to make a buffer at a given pH.
A final important piece of information derived from the titration curve of an amino acid is the relationship between its net charge and the pH of the solution. At pH 5.97, the point of inflection between the two stages in its titration curve, glycine is present predominantly as its dipolar form, fully ionized but with no net electric charge (Fig. 3-10). The characteristic pH at which the net electric charge is zero is called the isoelectric point or isoelectric pH, designated pI. For glycine, which has no ionizable group in its side chain, the isoelectric point is simply the arithmetic mean of the two values:
As is evident in Figure 3-10, glycine has a net negative charge at any pH above its pI and thus will move toward the positive electrode (the anode) when placed in an electric field. At any pH below its pI, glycine has a net positive charge and will move toward the negative electrode (the cathode). The farther the pH of a glycine solution is from its isoelectric point, the greater the net electric charge of the population of glycine molecules. At pH 1.0, for example, glycine exists almost entirely as the form with a net positive charge of 1.0. At pH 2.34, where there is an equal mixture of and the average or net positive charge is 0.5. The sign and the magnitude of the net charge of any amino acid at any pH can be predicted in the same way.
Amino Acids Differ in Their Acid-Base Properties
The shared properties of many amino acids permit some simplifying generalizations about their acid-base behaviors. First, all amino acids with a single α-amino group, a single α-carboxyl group, and an R group that does not ionize have titration curves resembling that of glycine (Fig. 3-10). These amino acids have very similar, although not identical, values: of the group in the range of 1.8 to 2.4, and of the group in the range of 8.8 to 11.0 (Table 3-1). The differences in these values reflect the chemical environments imposed by their R groups.
Second, amino acids with an ionizable R group have more complex titration curves, with three stages corresponding to the three possible ionization steps; thus, they have three values. The additional stage for the titration of the ionizable R group merges to some extent with that for the titration of the α-carboxyl group, the titration of the α-amino group, or both. The titration curves for two amino acids of this type, glutamate and histidine, are shown in Figure 3-12. The isoelectric points reflect the nature of the ionizing R groups that are present. For example, glutamate has a pI of 3.22, considerably lower than that of glycine. This is due to the presence of two carboxyl groups, which, at the average of their values (3.22), contribute a net charge of −1 that balances the +1 contributed by the amino group. Similarly, the pI of histidine, with two groups that are positively charged when protonated, is 7.59 (the average of the values of the amino and imidazole groups), much higher than that of glycine.
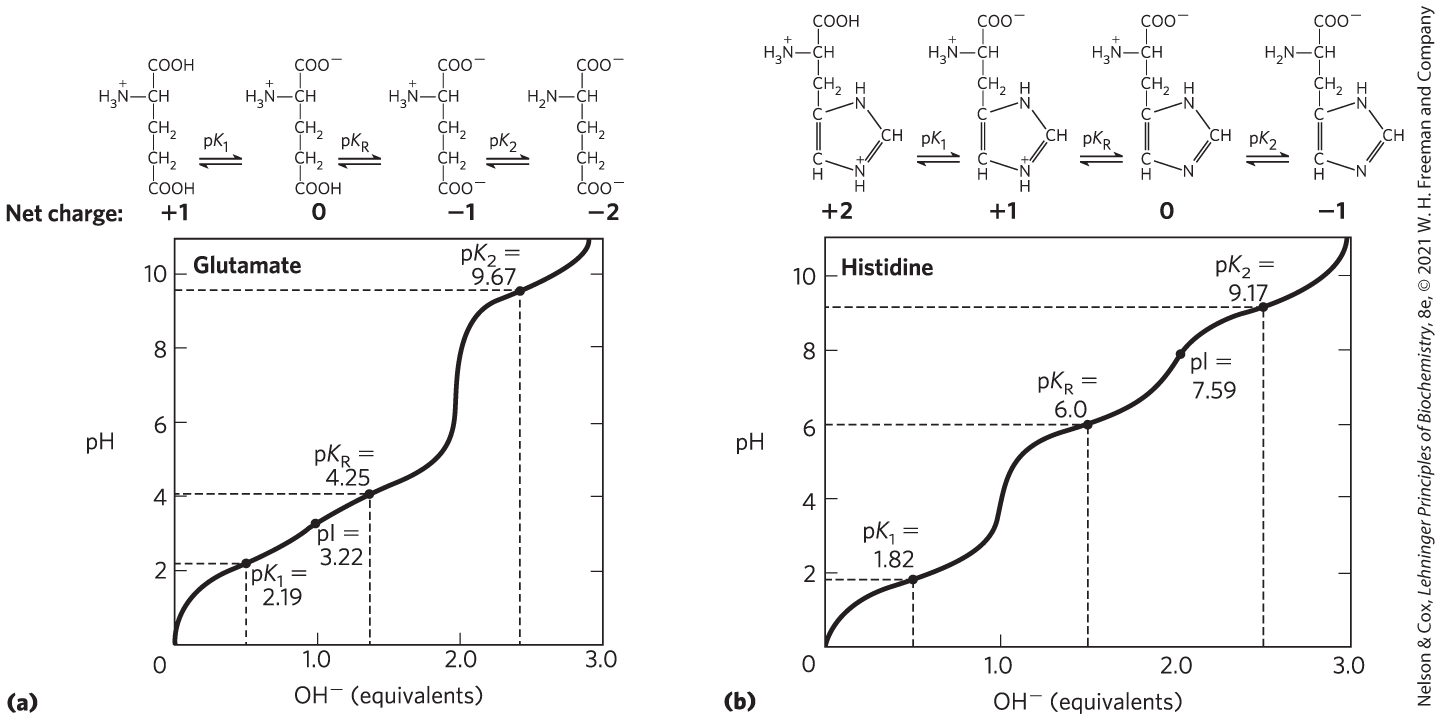
FIGURE 3-12 Titration curves for (a) glutamate and (b) histidine. The of the R group is designated here as . In both cases, the presence of three ionizable groups renders the titration curve more complex. Note that for glutamate, the pI is approximately the arithmetic mean of the of the two groups that are negatively charged. There is a net charge of 0 (the pI) when these two groups contribute a net charge of −1 (one protonated, the other not) to exactly balance the +1 charge of the protonated α-amino group. Similarly, the pI for histidine is approximately the arithmetic mean of the of the two groups that are positively charged when protonated.
Finally, in an aqueous environment, only histidine has an R group providing significant buffering power near the neutral pH usually found in the intracellular and extracellular fluids of most animals and bacteria (Table 3-1).
SUMMARY 3.1 Amino Acids
- The 20 amino acids commonly found as residues in proteins contain an α-carboxyl group, an α-amino group, and a distinctive R group substituted on the α-carbon atom. The α-carbon atom of all amino acids except glycine is asymmetric, and thus amino acids can exist in at least two stereoisomeric forms.
- Only the l stereoisomers of amino acids, with a configuration related to the absolute configuration of the reference molecule l-glyceraldehyde, are found in proteins.
- Amino acids can be classified into five types on the basis of the polarity and charge (at pH 7) of their R groups.
- Other, less common amino acids also occur, either as constituents of proteins (usually through modification of common amino acid residues after protein synthesis) or as free metabolites.
- Amino acids vary in their acid-base properties and have characteristic titration curves. Monoamino monocarboxylic amino acids (with nonionizable R groups) are diprotic acids at low pH and exist in several different ionic forms as the pH is increased.
- Amino acids with ionizable R groups have additional ionic species, depending on the pH of the medium and the of the R group.
 The 20 amino acids commonly found as residues in proteins contain an α-carboxyl group, an α-amino group, and a distinctive R group substituted on the α-carbon atom. The α-carbon atom of all amino acids except glycine is asymmetric, and thus amino acids can exist in at least two stereoisomeric forms.
The 20 amino acids commonly found as residues in proteins contain an α-carboxyl group, an α-amino group, and a distinctive R group substituted on the α-carbon atom. The α-carbon atom of all amino acids except glycine is asymmetric, and thus amino acids can exist in at least two stereoisomeric forms.