Chapter 27 PROTEIN METABOLISM

Almost every biological process requires one or more proteins. A typical cell requires thousands of different proteins at any given moment. These proteins must be synthesized in response to the cell’s current needs, modified to alter their activity or fate, transported (targeted) to their appropriate cellular locations, and degraded when no longer needed. Dozens of separate processes contribute to cellular proteostasis, the steady-state complement of proteins that enable the life of a cell at any given moment.
Many of the fundamental components and mechanisms used by the protein biosynthetic machinery are remarkably well conserved in all life-forms, from bacteria to higher eukaryotes, indicating that they were present in the last universal common ancestor (LUCA) of all extant organisms. Whereas the chapter focuses on protein biosynthesis, all aspects of proteostasis are considered. The principles that guide our approach are interrelated, reflecting all of these realities and more.
Information is expensive. This principle, noted in earlier chapters, is particularly well illustrated by protein synthesis. Protein synthesis consumes more cellular resources than any other process in most cells. The 15,000 ribosomes, 100,000 molecules of protein synthesis–related protein factors and enzymes, and 200,000 tRNA molecules in a typical bacterial cell can account for more than 35% of the cell’s dry weight. Overall, almost 300 different macromolecules cooperate to synthesize polypeptides. Protein synthesis can account for up to 90% of the chemical energy used by a cell for all biosynthetic reactions. Why? The enzymatic synthesis of an amide bond should require little energetic input. However, the sequence of amino acids in a protein is a form of biological information. Synthesis of each amide (peptide) bond between two particular amino acids is ensured by the investment of more than four nucleoside triphosphates (NTPs).
The genetic code is nearly universal and arose early in evolution. This is one of the many characteristics of living systems that ties all of them to a common ancestor. Even the rare exceptions to code universality reinforce this rule.
The genetic code functions via linker molecules. The tRNAs are the crucial adaptor, matching amino acids with DNA codons.
Proteins are synthesized by RNAs. The study of protein synthesis offers another important reward: a look at a world of RNA catalysts that may have existed in an RNA world before the dawn of life “as we know it.” Proteins are synthesized by a gigantic RNA enzyme.
Protein metabolism is regulated at many levels. The resource investment in protein synthesis ensures that many layers of regulation work together to determine which proteins are synthesized at any given moment. However, proteins often function only in particular cellular locations and at particular times. Mechanisms for spatial and temporal regulation — protein targeting, activation, and eventual degradation — exhibit complexities that can approach those of the biosynthetic processes.
 Information is expensive. This principle, noted in earlier chapters, is particularly well illustrated by protein synthesis. Protein synthesis consumes more cellular resources than any other process in most cells. The 15,000 ribosomes, 100,000 molecules of protein synthesis–related protein factors and enzymes, and 200,000 tRNA molecules in a typical bacterial cell can account for more than 35% of the cell’s dry weight. Overall, almost 300 different macromolecules cooperate to synthesize polypeptides. Protein synthesis can account for up to 90% of the chemical energy used by a cell for all biosynthetic reactions. Why? The enzymatic synthesis of an amide bond should require little energetic input. However, the sequence of amino acids in a protein is a form of biological information. Synthesis of each amide (peptide) bond between two particular amino acids is ensured by the investment of more than four nucleoside triphosphates (NTPs).
Information is expensive. This principle, noted in earlier chapters, is particularly well illustrated by protein synthesis. Protein synthesis consumes more cellular resources than any other process in most cells. The 15,000 ribosomes, 100,000 molecules of protein synthesis–related protein factors and enzymes, and 200,000 tRNA molecules in a typical bacterial cell can account for more than 35% of the cell’s dry weight. Overall, almost 300 different macromolecules cooperate to synthesize polypeptides. Protein synthesis can account for up to 90% of the chemical energy used by a cell for all biosynthetic reactions. Why? The enzymatic synthesis of an amide bond should require little energetic input. However, the sequence of amino acids in a protein is a form of biological information. Synthesis of each amide (peptide) bond between two particular amino acids is ensured by the investment of more than four nucleoside triphosphates (NTPs). The genetic code is nearly universal and arose early in evolution. This is one of the many characteristics of living systems that ties all of them to a common ancestor. Even the rare exceptions to code universality reinforce this rule.
The genetic code is nearly universal and arose early in evolution. This is one of the many characteristics of living systems that ties all of them to a common ancestor. Even the rare exceptions to code universality reinforce this rule. The genetic code functions via linker molecules. The tRNAs are the crucial adaptor, matching amino acids with DNA codons.
The genetic code functions via linker molecules. The tRNAs are the crucial adaptor, matching amino acids with DNA codons. Proteins are synthesized by RNAs. The study of protein synthesis offers another important reward: a look at a world of RNA catalysts that may have existed in an RNA world before the dawn of life “as we know it.” Proteins are synthesized by a gigantic RNA enzyme.
Proteins are synthesized by RNAs. The study of protein synthesis offers another important reward: a look at a world of RNA catalysts that may have existed in an RNA world before the dawn of life “as we know it.” Proteins are synthesized by a gigantic RNA enzyme. Protein metabolism is regulated at many levels. The resource investment in protein synthesis ensures that many layers of regulation work together to determine which proteins are synthesized at any given moment. However, proteins often function only in particular cellular locations and at particular times. Mechanisms for spatial and temporal regulation — protein targeting, activation, and eventual degradation — exhibit complexities that can approach those of the biosynthetic processes.
Protein metabolism is regulated at many levels. The resource investment in protein synthesis ensures that many layers of regulation work together to determine which proteins are synthesized at any given moment. However, proteins often function only in particular cellular locations and at particular times. Mechanisms for spatial and temporal regulation — protein targeting, activation, and eventual degradation — exhibit complexities that can approach those of the biosynthetic processes.Several major advances set the stage for our present knowledge of protein biosynthesis (Fig. 27-1). First, in the early 1950s, Paul Zamecnik and Elizabeth Keller discovered the ribonucleoprotein particles in which protein synthesis occurs. These particles, visible in animal tissues by electron microscopy, were later named ribosomes. Soon after, Francis Crick considered how the genetic information encoded in the 4-letter language of nucleic acids could be translated into the 20-letter language of proteins. In 1955, Crick postulated that a small nucleic acid could serve the role of an adaptor, with one part of the adaptor molecule binding a specific amino acid and another part recognizing the nucleotide sequence encoding that amino acid in an mRNA (Fig. 27-2). Crick’s adaptor hypothesis was soon verified when Mahlon Hoagland and Zamecnik discovered tRNA. The structure of alanyl-tRNA was reported by Robert Holley in 1964. The tRNA adaptor “translates” the nucleotide sequence of an mRNA into the amino acid sequence of a polypeptide. The overall process of mRNA-guided protein synthesis is often referred to simply as translation. Hoagland, Zamecnik, and Elizabeth Keller also discovered that amino acids were “activated” for protein synthesis when incubated with ATP and the cytosolic fraction of liver cells. The amino acids became attached to a heat-stable soluble RNA — the tRNA — to form aminoacyl-tRNAs. The enzymes that catalyze this process are the aminoacyl-tRNA synthetases.

FIGURE 27-1 Timeline for the elucidation of protein biosynthetic pathways. Some key contributions are highlighted. However, our current understanding of the genetic code and protein biosynthetic pathways comes as the result of international endeavors involving hundreds of laboratories. [Top left to bottom left: data from PDB ID 4TRA, E. Westhof et al., Acta Crystallogr. A 44:112, 1988; Top right to bottom right: Joseph F. Gennaro Jr./Science Source; data from PDB ID 4V7R, A. Ben-Shem et al., Science 330:1203, 2010.]
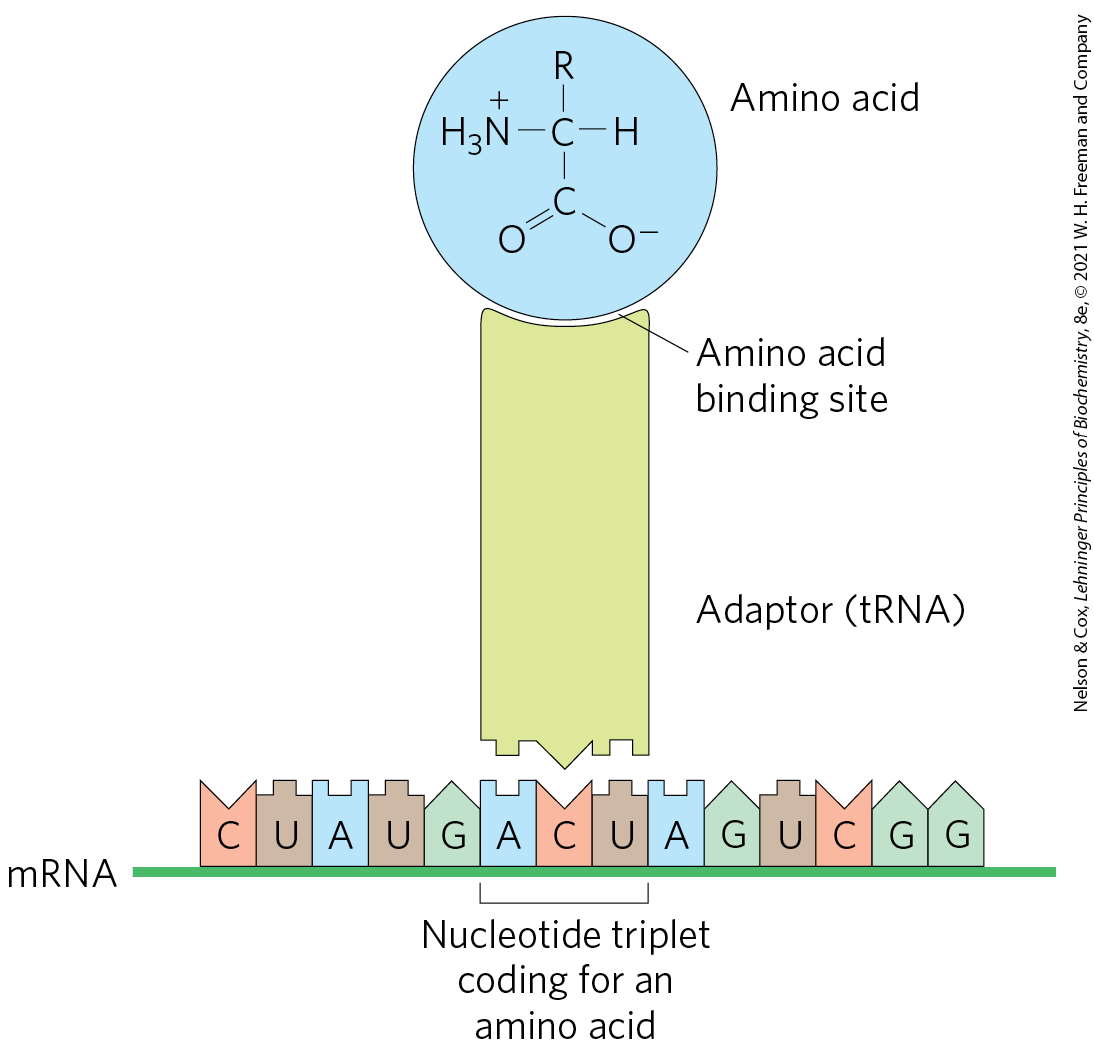
FIGURE 27-2 Crick’s adaptor hypothesis. Francis Crick proposed that one end of a small nucleotide adaptor could bind a specific amino acid and the other end could recognize a nucleotide sequence in the mRNA. Today we know that the amino acid is covalently bound at the end of a tRNA molecule and that a specific nucleotide triplet elsewhere in the tRNA interacts with a particular triplet codon in mRNA through hydrogen bonding of complementary bases.
These developments soon led to recognition of the major stages of protein synthesis and ultimately to elucidation of the genetic code that specifies each amino acid. In subsequent decades, ribosomes were purified and their protein and rRNA components were dissected. Elucidation of the three-dimensional structures of ribosomes was completed by 2000, confirming a hypothesis first put forward by Harry Noller two decades earlier: it is the rRNA, rather than ribosomal proteins, that catalyzes peptide bond formation.