7.3 Glycoconjugates: Proteoglycans, Glycoproteins, and Glycolipids
In addition to their important roles as fuel stores (starch, glycogen, dextran) and as structural materials (cellulose, chitin, peptidoglycans), polysaccharides and oligosaccharides are information carriers. Some provide communication between cells and their extracellular surroundings; others label proteins for transport to and localization in specific organelles, or for destruction when the protein is malformed or superfluous; and others serve as recognition sites for extracellular signal molecules (growth factors, for example) or extracellular parasites (bacteria or viruses). On almost every eukaryotic cell, specific oligosaccharide chains attached to components of the plasma membrane form a carbohydrate layer (the glycocalyx), several nanometers thick, that serves as an information-rich surface that the cell shows to its surroundings. These oligosaccharides are central players in cell-cell recognition and adhesion, cell migration during development, blood clotting, the immune response, wound healing, and other cellular processes. In most of these cases, the informational carbohydrate is covalently joined to a protein or a lipid to form a glycoconjugate, which is the biologically active molecule (Fig. 7-20).
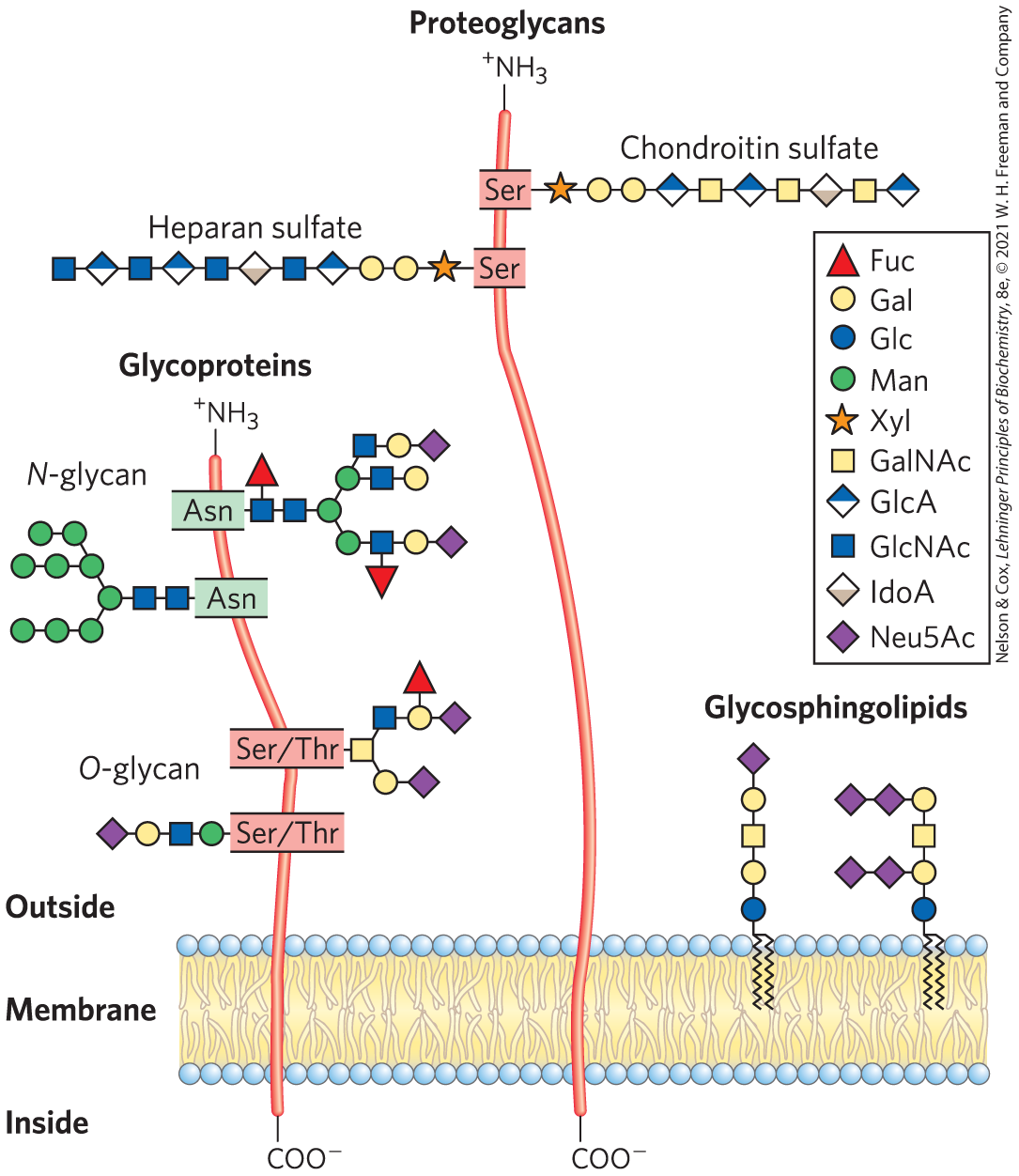
FIGURE 7-20 Glycoconjugates. The structures of some typical proteoglycans, glycoproteins, and glycosphingolipids described in the text.
Proteoglycans are macromolecules of the cell surface or ECM in which one or more sulfated glycosaminoglycan chains are joined covalently to a membrane protein or a secreted protein. The glycosaminoglycan chain can bind to extracellular proteins through electrostatic interactions between the protein and the negatively charged sugar moieties on the proteoglycan. Proteoglycans are major components of all extracellular matrices.
Glycoproteins have one or several oligosaccharides of varying complexity joined covalently to a protein. They are usually found on the outer face of the plasma membrane (as part of the glycocalyx), in the ECM, and in the blood. Inside cells, they are found in specific organelles such as Golgi complexes (where the oligosaccharide moieties are added to the proteins), secretory granules, and lysosomes. The oligosaccharide portions of glycoproteins are very heterogeneous and, like glycosaminoglycans, are rich in information, forming highly specific sites for recognition and high-affinity binding by carbohydrate-binding proteins called lectins. Some cytosolic and nuclear proteins can be glycosylated as well.
 The oligosaccharide portions of glycoproteins are very heterogeneous and, like glycosaminoglycans, are rich in information, forming highly specific sites for recognition and high-affinity binding by carbohydrate-binding proteins called lectins. Some cytosolic and nuclear proteins can be glycosylated as well.
The oligosaccharide portions of glycoproteins are very heterogeneous and, like glycosaminoglycans, are rich in information, forming highly specific sites for recognition and high-affinity binding by carbohydrate-binding proteins called lectins. Some cytosolic and nuclear proteins can be glycosylated as well.Glycolipids are plasma membrane components in which the hydrophilic head groups are oligosaccharides. Glycosphingolipids are a class of glycolipids with a specific backbone structure that will be considered in more detail in Chapter 10. They have complex oligosaccharide components that act as specific sites for recognition by lectins, as they do in glycoproteins. Neurons are rich in glycosphingolipids, which act in nerve conduction and myelin formation. Glycosphingolipids also play a role in signal transduction in cells.
Proteoglycans Are Glycosaminoglycan-Containing Macromolecules of the Cell Surface and Extracellular Matrix
Mammalian cells can produce dozens of types of proteoglycans. Many are secreted into the ECM, where they act as tissue organizers and influence cellular activities, such as growth factor activation and adhesion. The basic proteoglycan unit consists of a “core protein” with covalently attached glycosaminoglycan(s). The point of attachment is a Ser residue, to which the glycosaminoglycan is joined through a tetrasaccharide linker (Fig. 7-21).
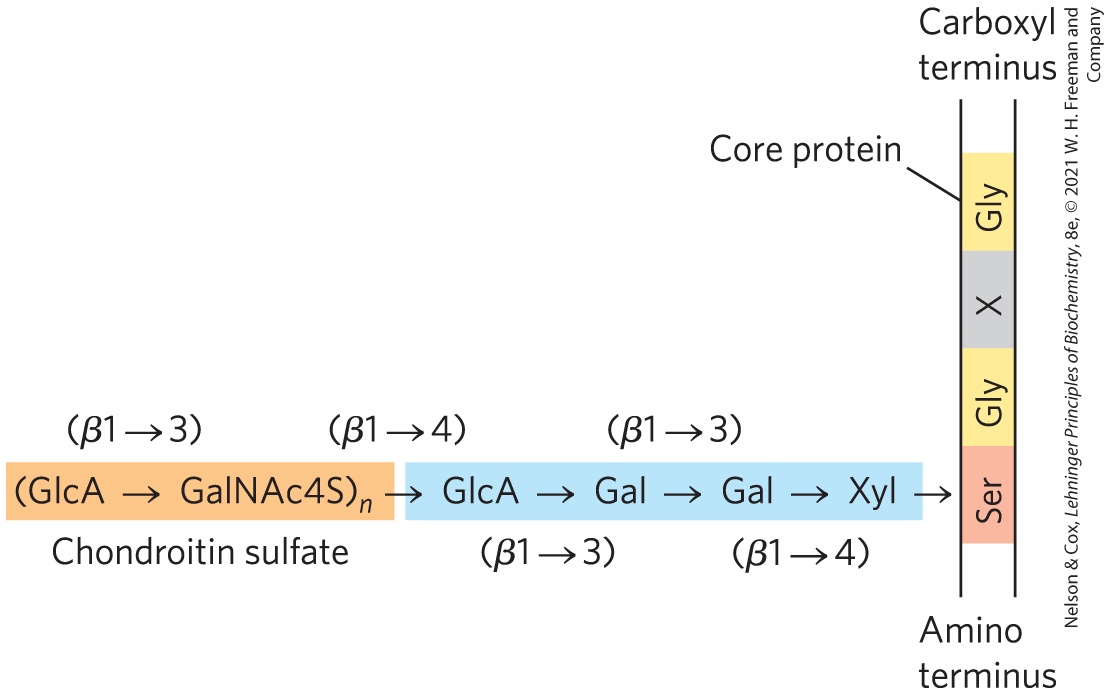
FIGURE 7-21 Proteoglycan structure, showing the tetrasaccharide bridge. A typical tetrasaccharide linker (blue) connects a glycosaminoglycan — in this case, chondroitin sulfate (orange) — to a Ser residue in the core protein. The xylose residue at the reducing end of the linker is joined by its anomeric carbon to the hydroxyl of the Ser residue.
Some proteoglycans are integral membrane proteins (see Fig. 11-9). For example, the basal lamina, a specialized layer of the ECM that separates two organized groups of cells, contains a family of core proteins ( 20,000 to 40,000), each with several covalently attached heparan sulfate chains. There are two major families of membrane heparan sulfate proteoglycans. Syndecans have a single transmembrane domain and an extracellular domain bearing three to five chains of heparan sulfate and, in some cases, chondroitin sulfate (Fig. 7-22a). Glypicans are attached to the membrane by a GPI anchor, a glycosylated derivative of the membrane lipid phosphatidylinositol (see Fig. 11-16). Both syndecans and glypicans can be shed into the extracellular space. A protease in the ECM that cuts proteins close to the membrane surface releases syndecan ectodomains (domains outside the plasma membrane), and a phospholipase that breaks the connection to the GPI anchor releases glypicans. These mechanisms provide a way for a cell to change its surface features quickly. Shedding is highly regulated and is activated in proliferating cells, such as cancer cells. Proteoglycan shedding is involved in cell-cell recognition and adhesion, and in the proliferation and differentiation of cells. Numerous chondroitin sulfate and dermatan sulfate proteoglycans also exist, some as membrane-bound entities, others as secreted products in the ECM.
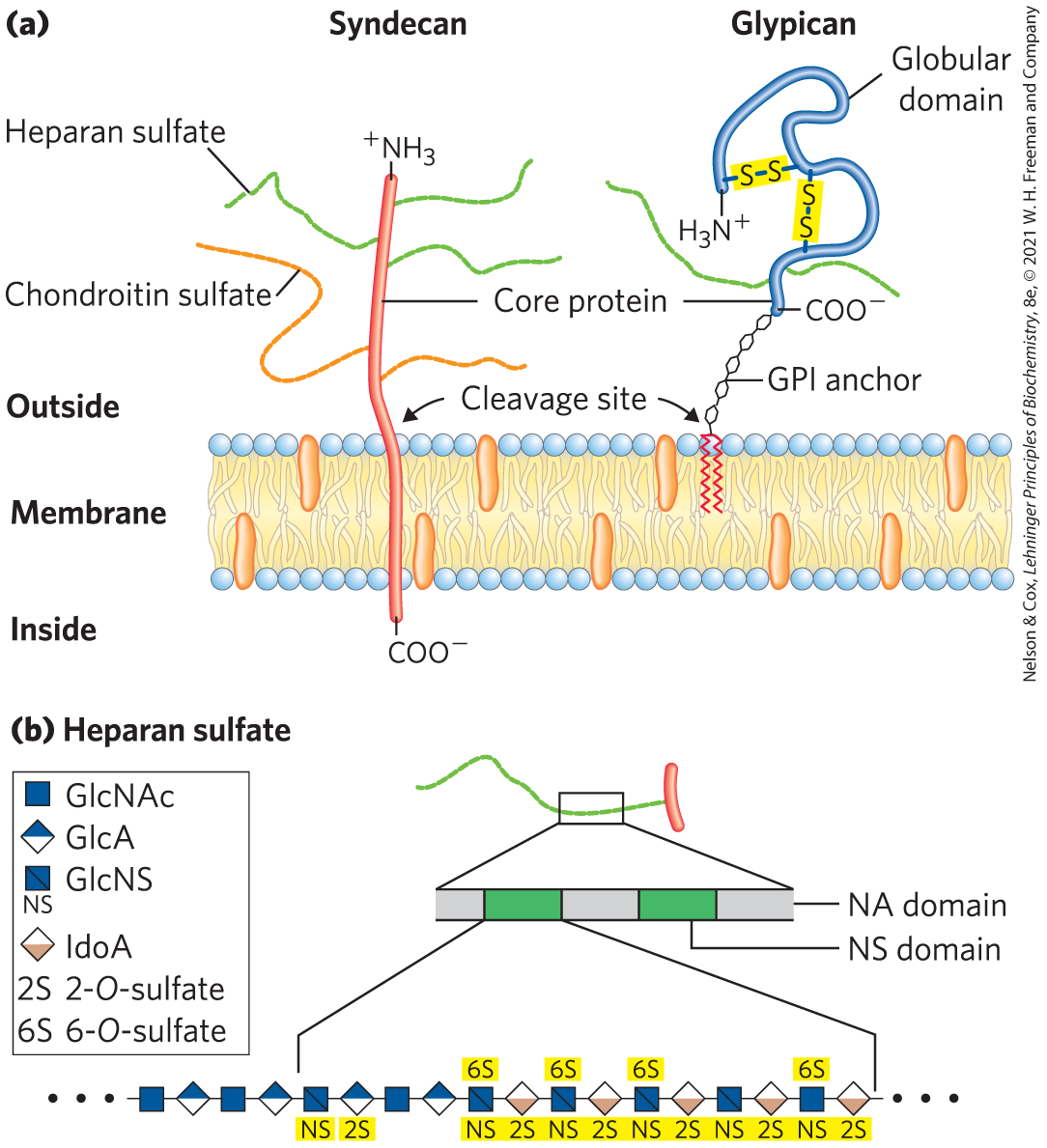
FIGURE 7-22 Two families of membrane proteoglycans. (a) Syndecans and glypicans can be shed from the membrane by enzymatic cleavage near the outer membrane surface. (b) Along a heparan sulfate chain, regions rich in sulfated sugars, the NS domains (green), alternate with regions with chiefly unmodified residues of GlcNAc and GlcA, the NA domains (gray). One of the NS domains is shown in more detail, revealing a high density of modified residues: GlcNS (N-sulfoglucosamine) and both GlcA and IdoA, with a sulfate ester at C-2. [(a) Information from U. Häcker et al., Nature Rev. Mol. Cell Biol. 6:530, 2005. (b) Information from J. Turnbull et al., Trends Cell Biol. 11:75, 2001.]
The glycosaminoglycan chains in proteoglycans can bind to a variety of extracellular ligands and thereby modulate the ligands’ interaction with specific receptors of the cell surface. Detailed studies of heparan sulfate demonstrate a domain structure that is not random; some domains (typically three to eight disaccharide units long) differ from neighboring domains in sequence and in ability to bind to specific proteins. Highly sulfated domains (called NS domains) alternate with domains having unmodified GlcNAc and GlcA residues (N-acetylated, or NA, domains) (Fig. 7-22b). The exact pattern of sulfation in the NS domain depends on the particular proteoglycan; given the number of possible modifications of the GlcNAc–IdoA (iduronic acid) dimer, at least 32 different disaccharide units are possible. Furthermore, the same core protein can display different heparan sulfate structures when synthesized in different cell types.
Heparan sulfate molecules with precisely organized NS domains bind specifically to extracellular proteins and signaling molecules to alter their activities. The change in activity may result from a conformational change in the protein that is induced by the binding (Fig. 7-23a), or it may be due to the ability of adjacent domains of heparan sulfate to bind to two different proteins, bringing them into close proximity and enhancing protein-protein interactions (Fig. 7-23b). A third general mechanism of action is the binding of extracellular signal molecules (growth factors, for example) to heparan sulfate, which increases their local concentrations and enhances their interaction with growth factor receptors on the cell surface; in this case, the heparan sulfate acts as a coreceptor (Fig. 7-23c). For example, fibroblast growth factor (FGF), an extracellular protein signal that stimulates cell division, first binds to heparan sulfate moieties of syndecan molecules in the target cell’s plasma membrane. Syndecan presents FGF to the FGF plasma membrane receptor, and only then can FGF interact productively with its receptor to trigger cell division. Finally, in another type of mechanism, the NS domains interact — electrostatically and otherwise — with a variety of soluble molecules outside the cell, maintaining high local concentrations at the cell surface (Fig. 7-23d).
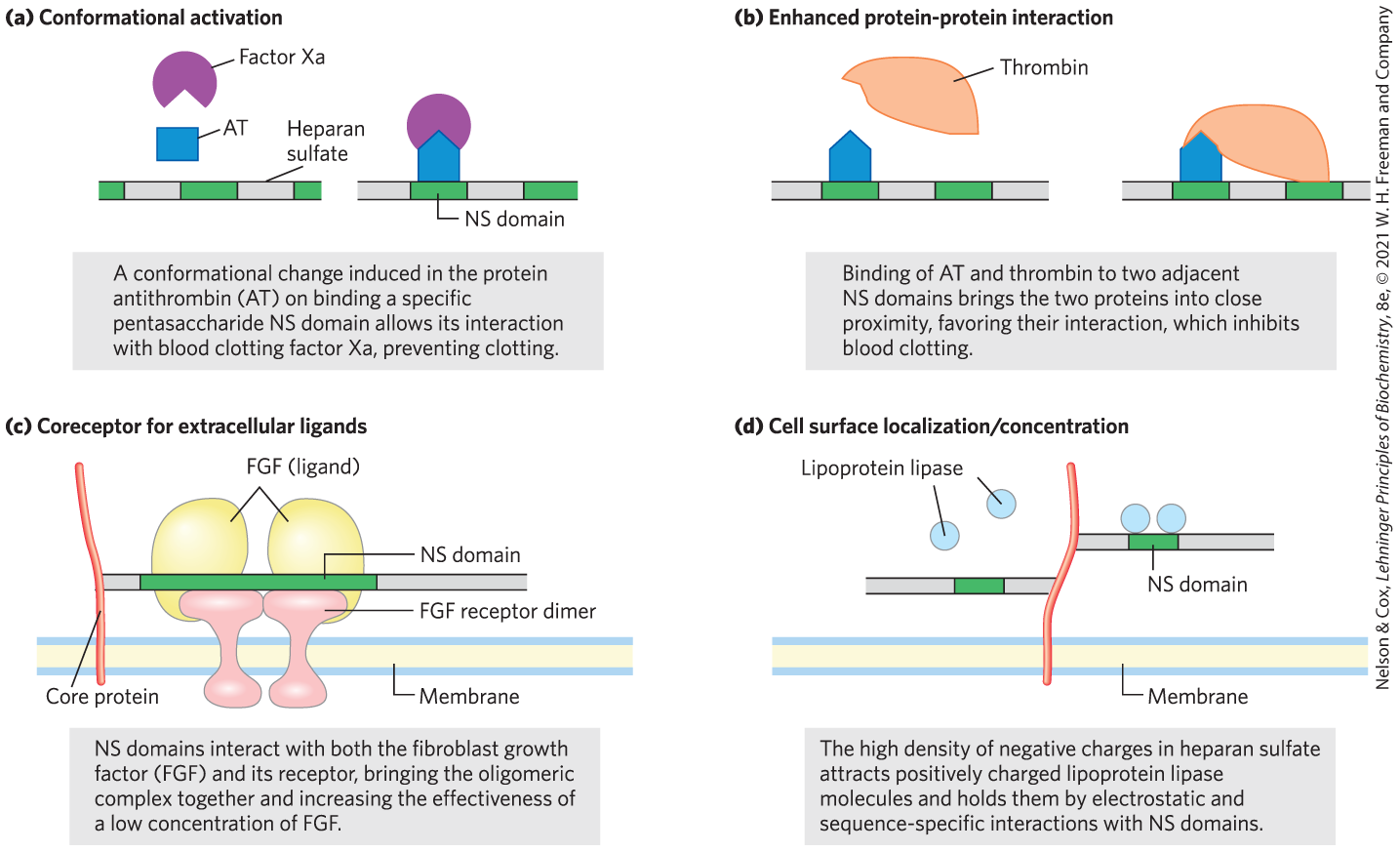
FIGURE 7-23 Four types of protein interactions with NS domains of heparan sulfate. [Information from J. Turnbull et al., Trends Cell Biol. 11:75, 2001.]
The protease thrombin, essential to blood coagulation (see Fig. 6-44), is inhibited by another blood protein, antithrombin, which prevents premature blood clotting. Antithrombin does not bind to or inhibit thrombin in the absence of heparan sulfate. In the presence of heparan sulfate or heparin, the binding affinity of thrombin for antithrombin increases 2,000-fold, and thrombin is strongly inhibited. When thrombin and antithrombin are crystallized in the presence of a short (16 residue) segment of heparan sulfate, the negatively charged heparan sulfate mimic is seen to bridge positively charged regions of the two proteins, causing an allosteric change that inhibits thrombin’s protease activity (Fig. 7-24). The binding sites for heparan sulfate and heparin in both proteins are rich in Arg and Lys residues; the amino acids’ positive charges interact electrostatically with the sulfates of the glycosaminoglycans. Antithrombin also inhibits two other blood coagulation proteins (factors IXa and Xa) in a heparan sulfate–dependent process.
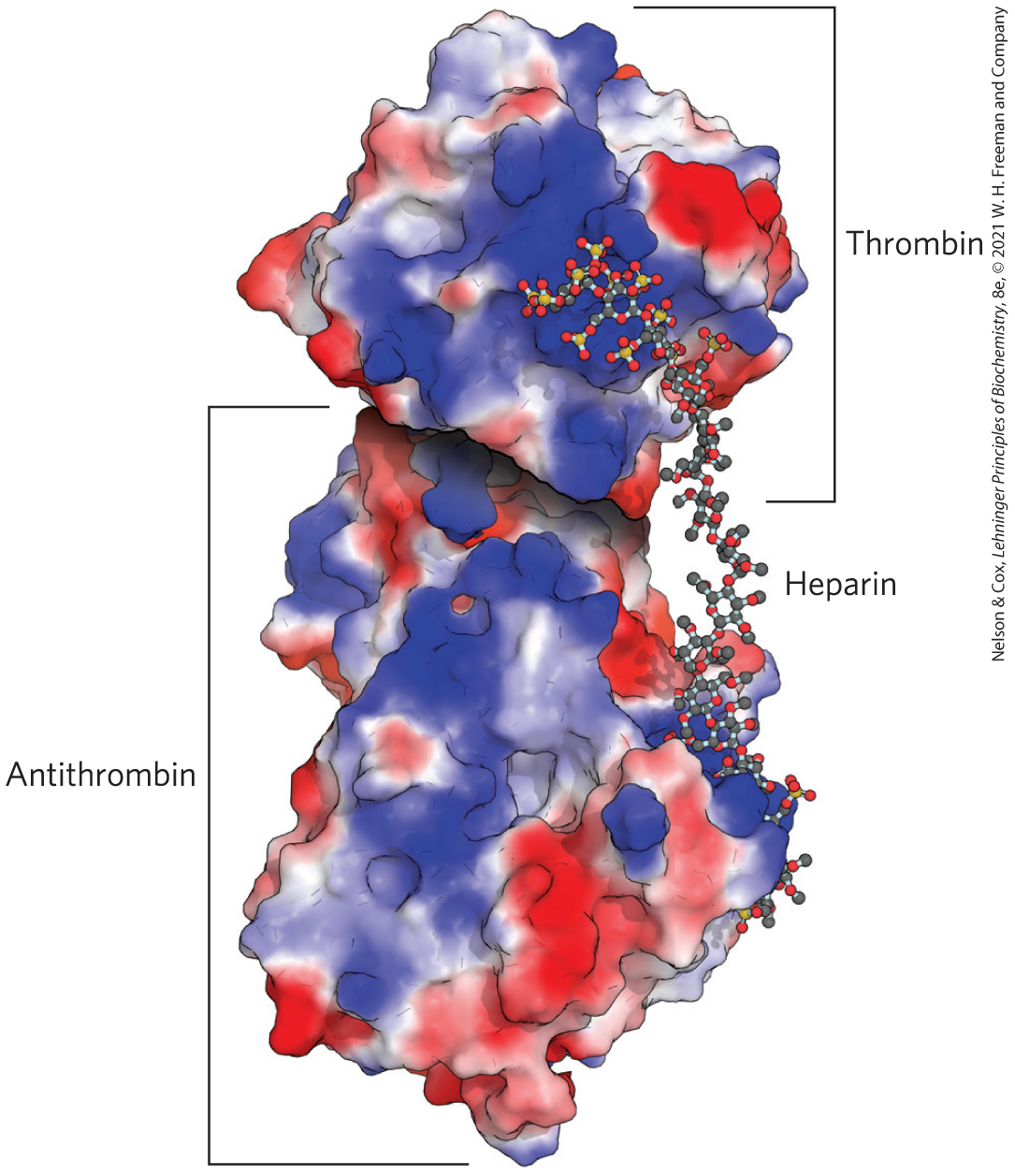
FIGURE 7-24 Molecular basis for heparan sulfate enhancement of the binding of thrombin to antithrombin. In this crystal structure of thrombin, antithrombin, and a 16 residue heparan sulfate–like polymer, all crystallized together, the binding sites for heparan sulfate in both proteins are rich in Arg and Lys residues. These positively charged regions, shown in blue in this electrostatic representation of the proteins, allow strong electrostatic interaction with multiple negatively charged sulfates and carboxylates of the heparan sulfate. Consequently, the affinity of antithrombin for thrombin is three orders of magnitude greater in the presence of heparan sulfate than in its absence. [Data from PDB ID 1TB6, W. Li et al., Nat. Struct. Mol. Biol. 11:857, 2004.]
The importance of correctly synthesizing sulfated domains in heparan sulfate is demonstrated in mutant (“knockout”) mice lacking the enzyme that sulfates the C-2 hydroxyl of iduronate (IdoA). These animals are born without kidneys and with severe developmental abnormalities of the skeleton and eyes. Other studies demonstrate that membrane proteoglycans are important in the liver for clearing lipoproteins from the blood. Finally, there is growing evidence that proteoglycans containing heparan sulfate and chondroitin sulfate provide directional cues for axon outgrowth, influencing the path taken by developing axons in the nervous system.
The functional importance of proteoglycans and the glycosaminoglycans associated with them can also be seen in the effects of mutations that block the synthesis or degradation of these polymers in humans (Box 7-3).
Some proteoglycans can form proteoglycan aggregates, enormous supramolecular assemblies of many core proteins all bound to a single molecule of hyaluronan (also called hyaluronate). Aggrecan core protein has multiple chains of chondroitin sulfate and keratan sulfate, joined to Ser residues in the core protein through trisaccharide linkers, to give an aggrecan monomer of . When a hundred or more of these “decorated” core proteins bind a single, extended molecule of hyaluronan (Fig. 7-25), the resulting proteoglycan aggregate and its associated water of hydration occupy a volume about equal to that of a bacterial cell! Aggrecan interacts strongly with collagen in the ECM of cartilage, contributing to the development, tensile strength, and resilience of this connective tissue.
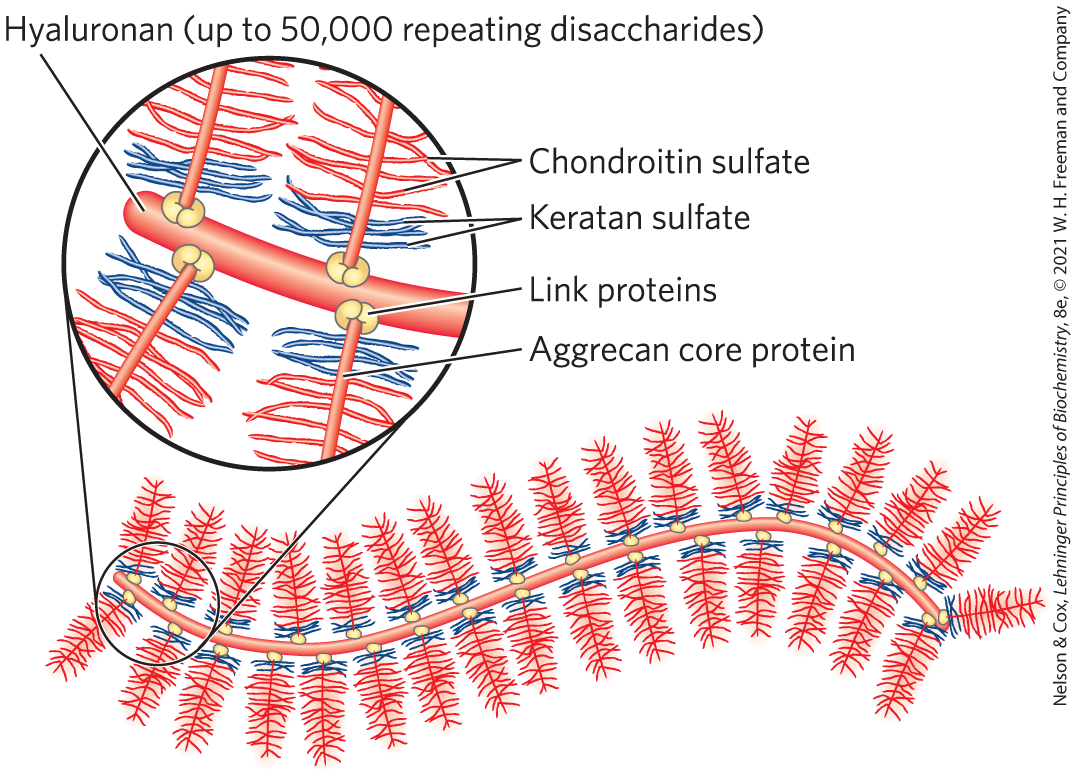
FIGURE 7-25 Proteoglycan aggregate of the extracellular matrix. Schematic drawing of a proteoglycan with many aggrecan molecules. One very long molecule of hyaluronan is associated noncovalently with about 100 molecules of the core protein aggrecan. Each aggrecan molecule contains many covalently bound chondroitin sulfate and keratan sulfate chains. Link proteins at the junction between each core protein and the hyaluronan backbone mediate the core protein–hyaluronan interaction.
Interwoven with these enormous extracellular proteoglycans are fibrous matrix proteins such as collagen, elastin, and fibronectin, forming a cross-linked meshwork that gives the whole ECM strength and resilience. Some of these proteins are multiadhesive, a single protein having binding sites for several different matrix molecules. Fibronectin, for example, has separate domains that bind fibrin, heparan sulfate, and collagen. Fibronectin and a number of other proteins in the extracellular matrix contain the conserved RGD sequence (Arg–Gly–Asp), through which they bind to a family of proteins called integrins. Integrins mediate signaling between the cell interior and the network of molecules in the ECM. The overall picture of cell-matrix interactions that emerges (Fig. 7-26) shows an array of interactions between cellular and extracellular molecules. These interactions serve not merely to anchor cells to the ECM, providing the strength and elasticity of skin and joints. They also provide paths that direct the migration of cells in developing tissue and serve to convey information in both directions across the plasma membrane.
 They also provide paths that direct the migration of cells in developing tissue and serve to convey information in both directions across the plasma membrane.
They also provide paths that direct the migration of cells in developing tissue and serve to convey information in both directions across the plasma membrane.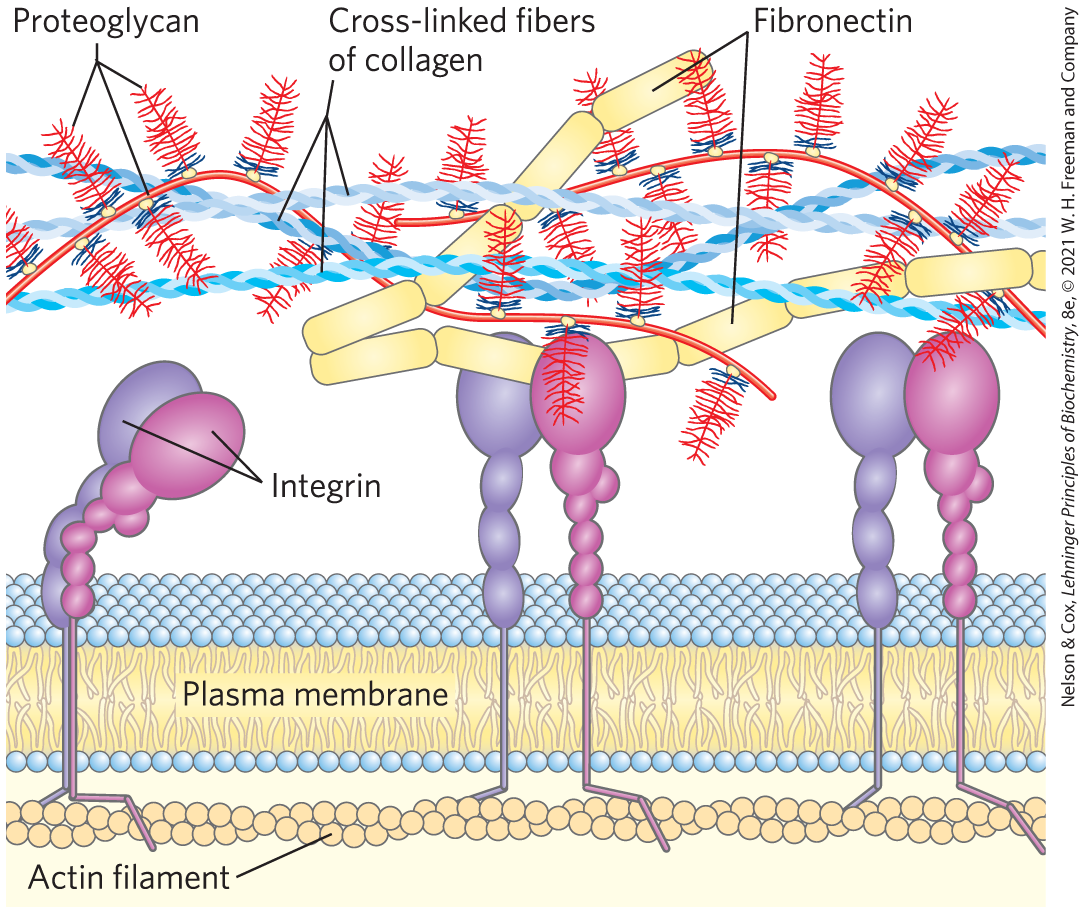
FIGURE 7-26 Interactions between cells and the extracellular matrix. The association between cells and the proteoglycan of the extracellular matrix is mediated by a membrane protein (integrin) and by an extracellular protein (fibronectin, with its RGD motif) with binding sites for both integrin and the proteoglycan. Note the close association of collagen fibers with the fibronectin and proteoglycan.
Glycoproteins Have Covalently Attached Oligosaccharides
Glycoproteins are carbohydrate-protein conjugates in which the glycans are branched and are much smaller and more structurally diverse than the huge glycosaminoglycans of proteoglycans. The carbohydrate is attached at its anomeric carbon through a glycosidic link to the —OH of a Ser or Thr residue (O-linked), or through an N-glycosyl link to the amide nitrogen of an Asn residue (N-linked) (Fig. 7-27). N-glycosyl bonds join the anomeric carbon of a sugar to a nitrogen atom in glycoproteins and nucleotides (see Fig. 8-1). Some glycoproteins have a single oligosaccharide chain, but many have more than one; the carbohydrate may constitute from 1% to 70% of the glycoprotein by mass. About half of all proteins of mammals are glycosylated.
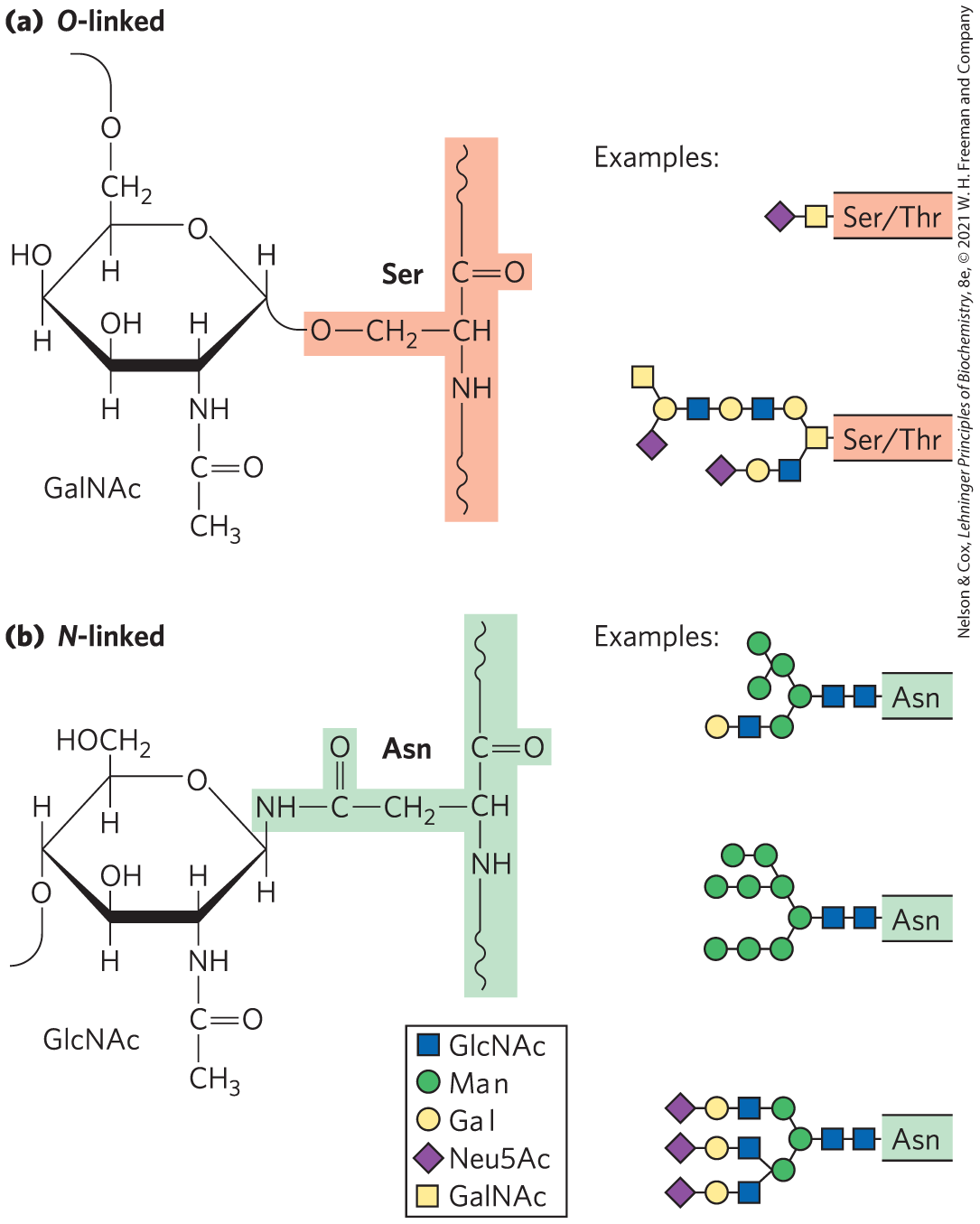
FIGURE 7-27 Oligosaccharide linkages in glycoproteins. (a) O-linked oligosaccharides have a glycosidic bond to the hydroxyl group of Ser or Thr residues (light red), illustrated here with GalNAc as the sugar at the reducing end of the oligosaccharide. One simple chain and one complex chain are shown. (b) N-linked oligosaccharides have an N-glycosyl bond to the amide nitrogen of an Asn residue (green), illustrated here with GlcNAc as the terminal sugar. Three common types of oligosaccharide chains that are N-linked in glycoproteins are shown. A complete description of oligosaccharide structure requires specification of the position and stereochemistry (α or β) of each glycosidic linkage.
As we shall see in Chapter 11, the external surface of the plasma membrane has many membrane glycoproteins with arrays of covalently attached oligosaccharides of varying complexity. Mucins are secreted or membrane glycoproteins that can contain large numbers of O-linked oligosaccharide chains. Mucins are present in most secretions; they are what gives mucus its characteristic slipperiness. Many of the proteins secreted by eukaryotic cells are glycoproteins, including most of the proteins of blood. For example, immunoglobulins (antibodies) and certain hormones, such as follicle-stimulating hormone, luteinizing hormone, and thyroid-stimulating hormone, are glycoproteins. Some of the proteins secreted by the pancreas are glycosylated, as are most of the proteins contained in lysosomes. Many milk proteins, including the major whey protein α-lactalbumin, are glycosylated.
Glycomics is the systematic characterization of all carbohydrate components of a given cell or tissue, including those attached to proteins and to lipids. For glycoproteins, this also means determining which proteins are glycosylated and where in the amino acid sequence each oligosaccharide is attached. This is a challenging undertaking, but worthwhile because of the potential insights it offers into normal patterns of glycosylation and the ways in which they are altered during development or in genetic diseases or cancer. Current methods of characterizing the entire carbohydrate complement of cells depend heavily on sophisticated application of nuclear magnetic resonance and mass spectrometry.
The structures of a large number of O- and N-linked oligosaccharides from a variety of glycoproteins are known; Figures 7-20 and 7-27 show a few typical examples. In Chapter 27, we consider the mechanisms by which specific proteins acquire specific oligosaccharide moieties.
What are the biological advantages of adding oligosaccharides to proteins? The very hydrophilic carbohydrate clusters alter the polarity and solubility of the proteins with which they are conjugated. Oligosaccharide chains that are attached to newly synthesized proteins in the endoplasmic reticulum (ER) and elaborated in the Golgi complex serve as destination labels and also act in protein quality control, targeting misfolded proteins for degradation (see Figs. 27-38, 27-39). When numerous negatively charged oligosaccharide chains are clustered in a single region of a protein, the charge repulsion among them favors the formation of an extended, rodlike structure in that region. The bulkiness and negative charge of oligosaccharide chains also protect some proteins from attack by proteolytic enzymes.
Beyond these global physical effects on protein structure, there are also more specific biological effects of oligosaccharide chains in glycoproteins (Section 7.4). The importance of normal protein glycosylation is clear from at least 40 different genetic disorders of glycosylation having been found in humans, all causing severely defective physical or mental development; some of these disorders are fatal.
Glycolipids and Lipopolysaccharides Are Membrane Components
Glycoproteins are not the only cellular components that bear complex oligosaccharide chains; some lipids, too, have covalently bound oligosaccharides. Gangliosides are membrane lipids of eukaryotic cells in which the polar head group, the part of the lipid that forms the outer surface of the membrane, is a complex oligosaccharide containing a sialic acid (Fig. 7-9) and other monosaccharide residues. Some of the oligosaccharide moieties of gangliosides, such as those that determine human blood groups (see Fig. 10-13), are identical with those found in certain glycoproteins, which therefore also contribute to blood group type. Like the oligosaccharide moieties of glycoproteins, those of membrane lipids are generally, perhaps always, found on the outer face of the plasma membrane.
Lipopolysaccharides are the dominant surface feature of the outer membrane of gram-negative bacteria such as Escherichia coli and Salmonella typhimurium. These molecules are prime targets of the antibodies produced by the vertebrate immune system in response to bacterial infection and are therefore important determinants of the serotype of bacterial strains. (Serotypes are strains that are distinguished on the basis of antigenic properties.) The lipopolysaccharides of S. typhimurium contain six fatty acids bound to two glucosamine residues, one of which is the point of attachment for a complex oligosaccharide (Fig. 7-28). E. coli has similar but unique lipopolysaccharides. The lipid A portion of the lipopolysaccharides of some bacteria is called endotoxin; its toxicity to humans and other animals is responsible for the dangerously lowered blood pressure that occurs in toxic shock syndrome resulting from gram-negative bacterial infections.
 Lipopolysaccharides are the dominant surface feature of the outer membrane of gram-negative bacteria such as Escherichia coli and Salmonella typhimurium. These molecules are prime targets of the antibodies produced by the vertebrate immune system in response to bacterial infection and are therefore important determinants of the serotype of bacterial strains. (Serotypes are strains that are distinguished on the basis of antigenic properties.) The lipopolysaccharides of S. typhimurium contain six fatty acids bound to two glucosamine residues, one of which is the point of attachment for a complex oligosaccharide (
Lipopolysaccharides are the dominant surface feature of the outer membrane of gram-negative bacteria such as Escherichia coli and Salmonella typhimurium. These molecules are prime targets of the antibodies produced by the vertebrate immune system in response to bacterial infection and are therefore important determinants of the serotype of bacterial strains. (Serotypes are strains that are distinguished on the basis of antigenic properties.) The lipopolysaccharides of S. typhimurium contain six fatty acids bound to two glucosamine residues, one of which is the point of attachment for a complex oligosaccharide (
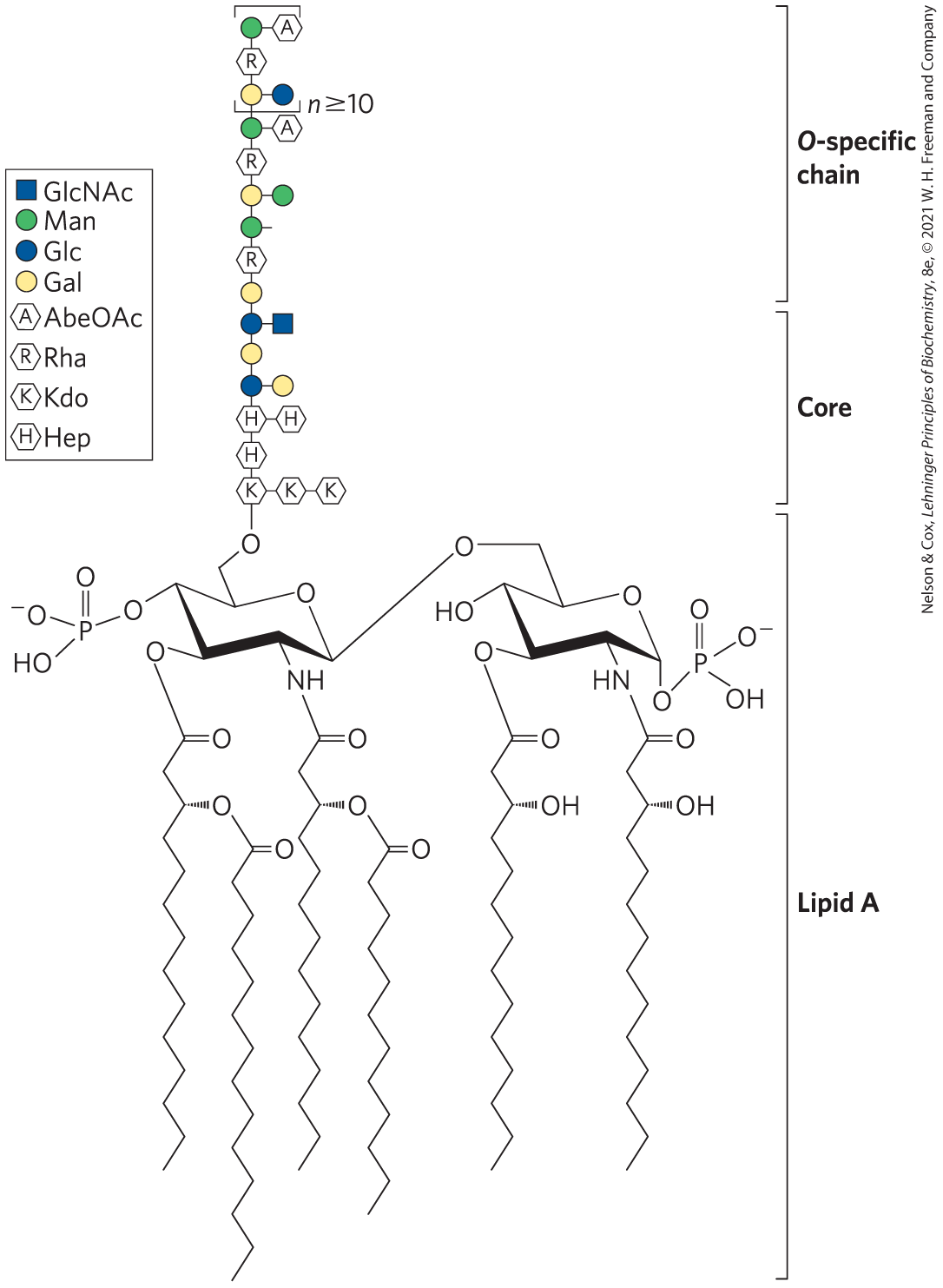
FIGURE 7-28 Bacterial lipopolysaccharides. Schematic diagram of the lipopolysaccharide of the outer membrane of S. typhimurium. Kdo is 3-deoxy-d-manno-octulosonic acid (previously called ketodeoxyoctonic acid); Hep is l-glycero-d-manno-heptose; AbeOAc is abequose (a 3,6-dideoxyhexose) acetylated on one of its hydroxyls. Different bacterial species have subtly different lipopolysaccharide structures, but they have in common a lipid A region, composed of six fatty acid residues and two phosphorylated glucosamines, a core oligosaccharide, and an “O-specific” chain, which is the principal determinant of the serotype (immunological reactivity) of the bacterium. The outer membranes of the gram-negative bacteria S. typhimurium and E. coli contain so many lipopolysaccharide molecules that the cell surface is almost completely covered with O-specific chains.
SUMMARY 7.3 Glycoconjugates: Proteoglycans, Glycoproteins, and Glycolipids
- Proteoglycans are huge molecules in which one or more large glycans, called sulfated glycosaminoglycans (heparan sulfate, chondroitin sulfate, dermatan sulfate, or keratan sulfate), are covalently attached to a core protein. Bound to the outside of the plasma membrane through a peptide or lipid, proteoglycans provide points of adhesion, recognition, and information transfer between cells, or between a cell and the extracellular matrix. In the extracellular matrix, enormous proteoglycan aggregates form, bound to a long hyaluronan molecule.
- Glycoproteins contain oligosaccharides covalently linked to Asn, Ser, or Thr residues. The oligosaccharides are typically branched and smaller than glycosaminoglycans. Many cell surface or extracellular proteins are glycoproteins, as are most secreted proteins. The covalently attached oligosaccharides influence the folding and stability of the proteins, provide critical information about the targeting of newly synthesized proteins, and allow specific recognition by other proteins.
- Glycolipids and glycosphingolipids in plants and animals and lipopolysaccharides in bacteria are components of the cell envelope, with covalently attached oligosaccharide chains exposed on the cell’s outer surface.
 Proteoglycans are huge molecules in which one or more large glycans, called sulfated glycosaminoglycans (heparan sulfate, chondroitin sulfate, dermatan sulfate, or keratan sulfate), are covalently attached to a core protein. Bound to the outside of the plasma membrane through a peptide or lipid, proteoglycans provide points of adhesion, recognition, and information transfer between cells, or between a cell and the extracellular matrix. In the extracellular matrix, enormous proteoglycan aggregates form, bound to a long hyaluronan molecule.
Proteoglycans are huge molecules in which one or more large glycans, called sulfated glycosaminoglycans (heparan sulfate, chondroitin sulfate, dermatan sulfate, or keratan sulfate), are covalently attached to a core protein. Bound to the outside of the plasma membrane through a peptide or lipid, proteoglycans provide points of adhesion, recognition, and information transfer between cells, or between a cell and the extracellular matrix. In the extracellular matrix, enormous proteoglycan aggregates form, bound to a long hyaluronan molecule.