The amino acid sequence of every protein in a cell, and the nucleotide sequence of every RNA, is specified by a nucleotide sequence in the cell’s DNA. A segment of a DNA molecule that contains the information required for the synthesis of a functional biological product, whether protein or RNA, is referred to as a gene. A cell typically has many thousands of genes, and DNA molecules, not surprisingly, tend to be very large. The storage of biological information and the transmission of that information from one generation to the next are the only known functions of DNA.
RNAs have a broader range of functions, and several classes are found in cells. Ribosomal RNAs (rRNAs) are components of ribosomes, the complexes that carry out the synthesis of proteins. Messenger RNAs (mRNAs) are intermediaries, carrying information for the synthesis of a protein from one or a few genes to a ribosome. Transfer RNAs (tRNAs) are adapter molecules that faithfully translate the information in mRNA into a specific sequence of amino acids. In addition to these major classes, there are many RNAs (noncoding or ncRNAs) with a wide variety of special functions, described in depth in Part III.
Nucleotides and Nucleic Acids Have Characteristic Bases and Pentoses
A nucleotide has three characteristic components: (1) a nitrogenous (nitrogen-containing) base, (2) a pentose, and (3) one or more phosphates (Fig. 8-1). The molecule without a phosphate group is called a nucleoside. The nitrogenous bases are derivatives of two parent compounds, pyrimidine and purine. The bases and pentoses of the common nucleotides are heterocyclic compounds.
FIGURE 8-1 Structure of nucleotides. (a) General structure showing the numbering convention for the pentose ring. This is a ribonucleotide. In deoxyribonucleotides the —OH group on the carbon (in red) is replaced with —H. (b) The parent compounds of the pyrimidine and purine bases of nucleotides and nucleic acids, showing the numbering conventions.
Key Convention
The carbon atoms and nitrogen atoms in the parent structures are conventionally numbered to facilitate the naming and identification of the many derivative compounds. The convention for the pentose ring follows rules outlined in Chapter 7, but in the pentoses of nucleotides and nucleosides the carbon numbers are given a prime () designation to distinguish them from the numbered atoms of the nitrogenous bases.
The base of a nucleotide is joined covalently (at N-1 of pyrimidines and N-9 of purines) in an N-β-glycosyl bond to the carbon of the pentose, and the phosphate is esterified to the carbon. The N-β-glycosyl bond is formed by removal of the elements of water (a hydroxyl group from the pentose and hydrogen from the base), as in O-glycosidic bond formation.
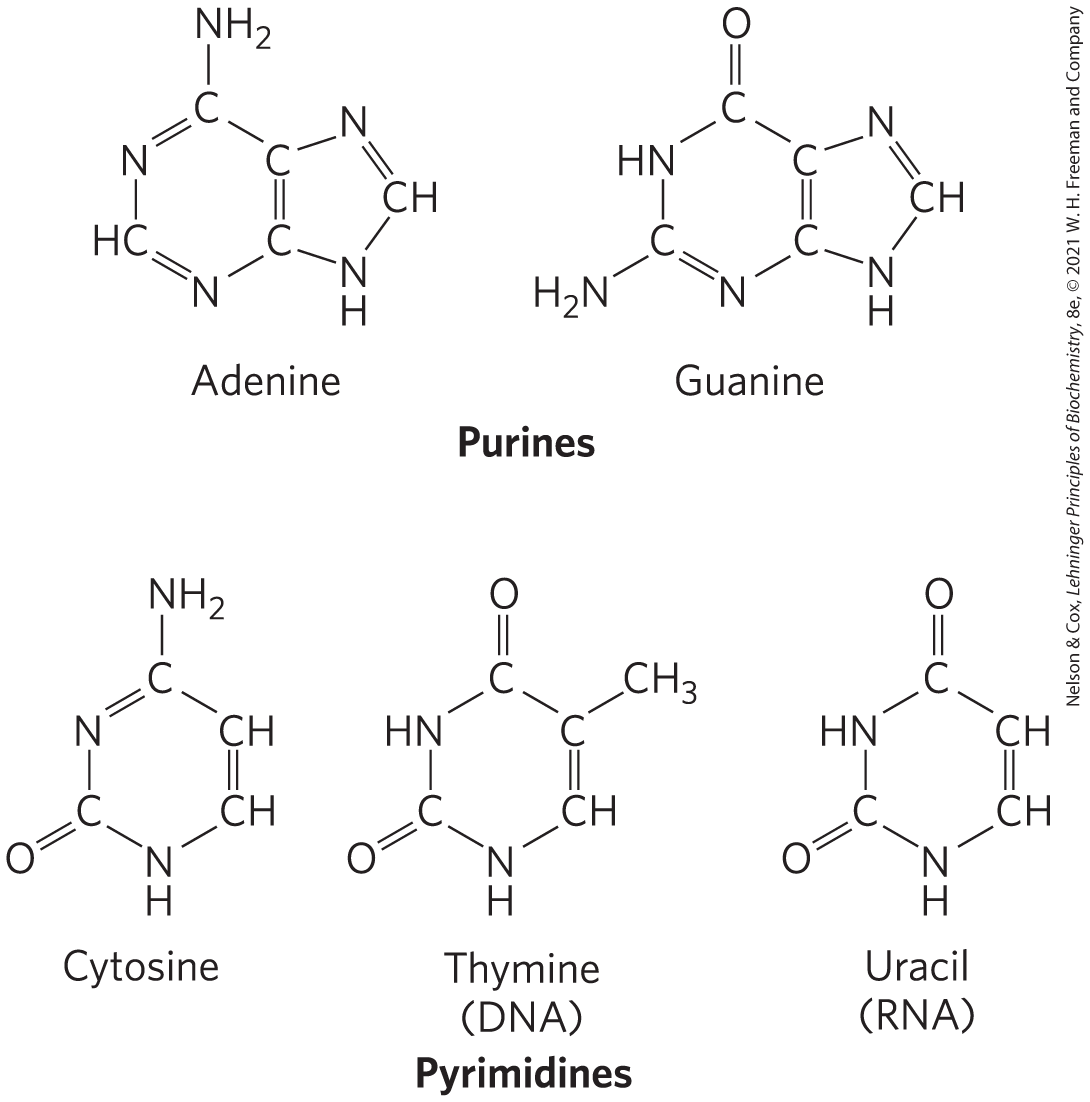
Both DNA and RNA contain two major purine bases, adenine (A) and guanine (G), and two major pyrimidines. In both DNA and RNA, one of the pyrimidines is cytosine (C), but the second common pyrimidine is not the same in both: it is thymine (T) in DNA and uracil (U) in RNA. Only occasionally does thymine occur in RNA or uracil in DNA. The structures of the five major bases are shown in Figure 8-2, and the nomenclature of their corresponding nucleotides and nucleosides is summarized in Table 8-1.
FIGURE 8-2 Major purine and pyrimidine bases of nucleic acids. Some of the common names of these bases reflect the circumstances of their discovery. Guanine, for example, was first isolated from guano (bird manure), and thymine was first isolated from thymus tissue.
TABLE 8-1 Nucleotide and Nucleic Acid Nomenclature
Base
Nucleoside
Nucleotide
Nucleic acid
Purines
Adenine
Adenosine
Deoxyadenosine
Adenylate
Deoxyadenylate
RNA
DNA
Guanine
Guanosine
Deoxyguanosine
Guanylate
Deoxyguanylate
RNA
DNA
Pyrimidines
Cytosine
Cytidine
Deoxycytidine
Cytidylate
Deoxycytidylate
RNA
DNA
Thymine
Thymidine or deoxythymidine
Thymidylate or deoxythymidylate
DNA
Uracil
Uridine
Uridylate
RNA
Note: “Nucleoside” and “nucleotide” are generic terms that include both ribo- and deoxyribo- forms. Also, ribonucleosides and ribonucleotides are here designated simply as nucleosides and nucleotides (e.g., riboadenosine as adenosine), and deoxyribonucleosides and deoxyribonucleotides as deoxynucleosides and deoxynucleotides (e.g., deoxyriboadenosine as deoxyadenosine). Both forms of naming are acceptable, but the shortened names are more commonly used. Thymine is an exception; “ribothymidine” is used to describe its unusual occurrence in RNA.
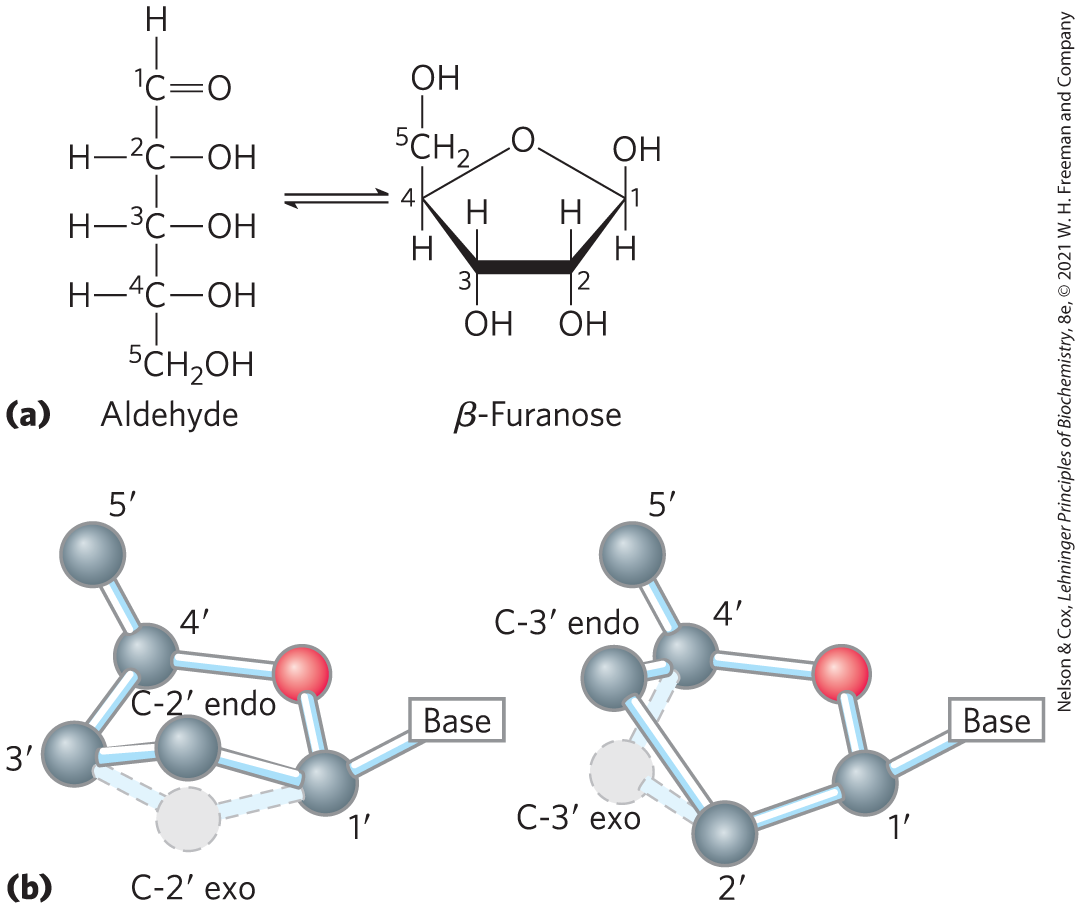
Nucleic acids have two kinds of pentoses. The recurring deoxyribonucleotide units of DNA contain -deoxy-d-ribose, and the ribonucleotide units of RNA contain d-ribose. In nucleotides, both types of pentoses are in their β-furanose (closed five-membered ring) form (Fig. 8-3a). As Figure 8-3b shows, the pentose ring is not planar but occurs in one of a variety of conformations generally described as “puckered.”
FIGURE 8-3 Conformations of ribose. (a) In solution, the straight-chain (aldehyde) and ring (β-furanose) forms of free ribose are in equilibrium. RNA contains only the ring form, β-d-ribofuranose. Deoxyribose undergoes a similar interconversion in solution, but in DNA it exists solely as β--deoxy-d-ribofuranose. (b) Ribofuranose rings in nucleotides can exist in four different puckered conformations. In all cases, four of the five atoms are nearly in a single plane. The fifth atom (C- or C-) is on either the same (endo) side or the opposite (exo) side of the plane relative to the C- atom.
Key Convention
Although DNA and RNA seem to have two distinguishing features — different pentoses and the presence of uracil in RNA and thymine in DNA — it is the pentoses that uniquely define the identity of a nucleic acid. If the nucleic acid contains -deoxy-d-ribose, it is DNA by definition, even if it contains uracil. Similarly, if the nucleic acid contains d-ribose, it is RNA, regardless of its base composition. The presence of uracil or thymine is not a defining characteristic.
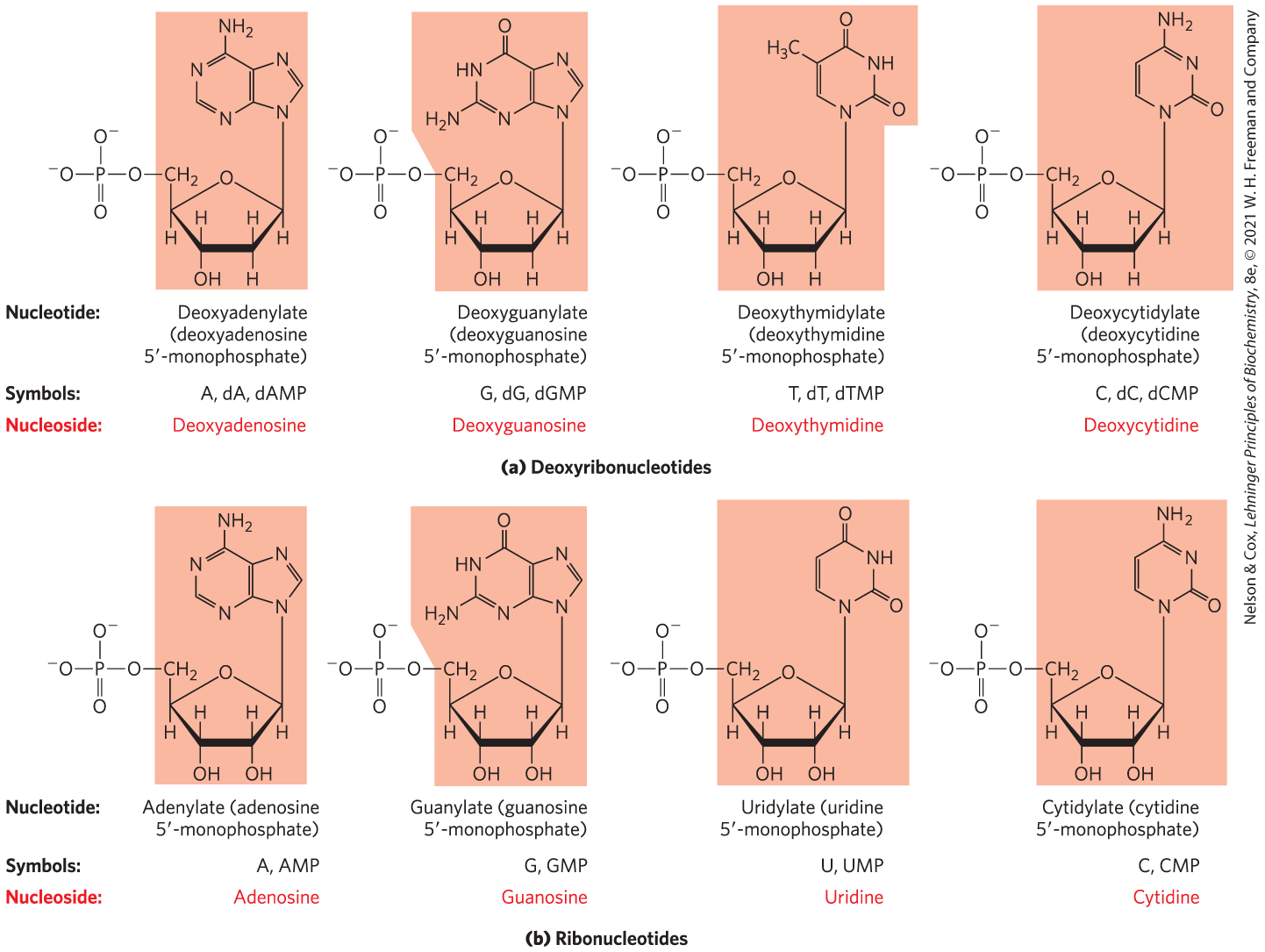
Figure 8-4a gives the structures and names of the four major deoxyribonucleotides, the structural units of DNAs, and Figure 8-4b shows the four major ribonucleotides, the structural units of RNAs. Deoxyribonucleotides are also referred to as deoxyribonucleoside -monophosphates, deoxynucleotides, and deoxynucleoside triphosphates; ribonucleotides are also called ribonucleoside -monophosphates.
FIGURE 8-4 Deoxyribonucleotides and ribonucleotides of nucleic acids. All nucleotides are shown in their free form at pH 7.0. The nucleotide units of (a) DNA and (b) RNA are shown. For each nucleotide, the more common name is given, followed by the complete name in parentheses and symbols used to represent them. All abbreviations assume that the phosphate group is at the position. The nucleoside portion of each molecule is shaded in light red. In this and the following illustrations, the ring carbons are not shown.
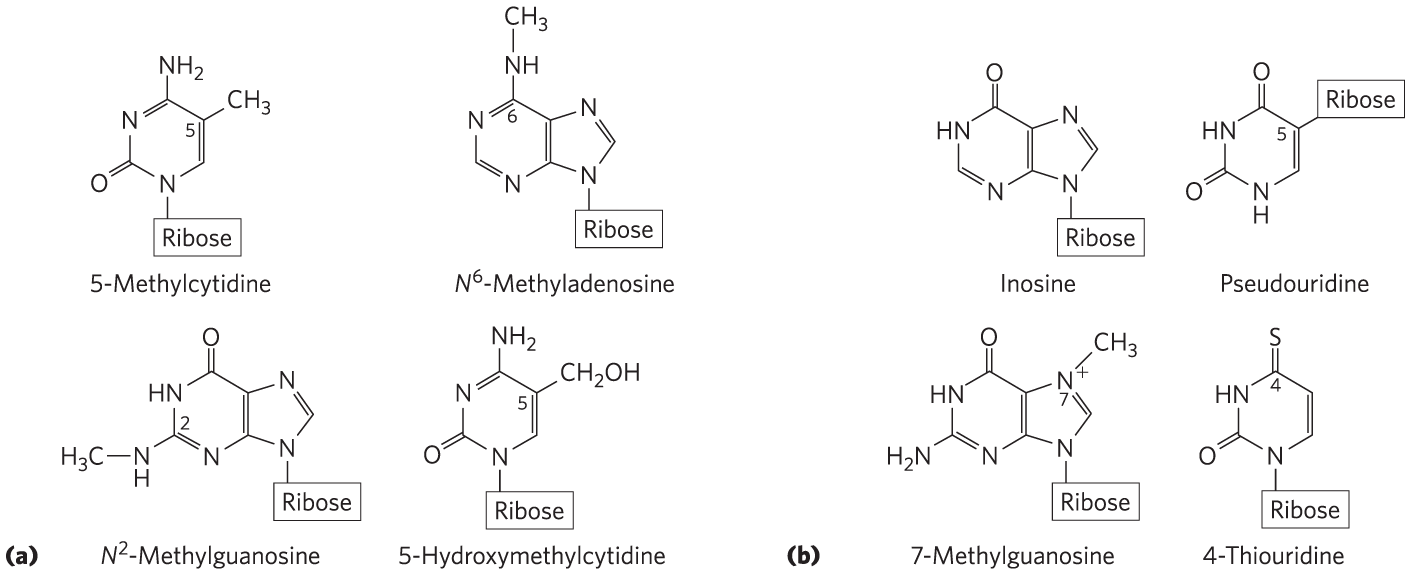
Although nucleotides bearing the major purines and pyrimidines are most common, both DNA and RNA also contain some minor bases (Fig. 8-5). In DNA the most common of these are methylated forms of the major bases; in some viral DNAs, certain bases may be hydroxymethylated or glucosylated. Altered or unusual bases in DNA molecules often have roles in regulating or protecting the genetic information. Hundreds of different modified bases are also found in RNAs, especially in rRNAs and tRNAs (see Fig. 8-25 and Fig. 26-22). The modifications are usually introduced by enzymes that act after the RNA or DNA is synthesized.
FIGURE 8-5 Some minor purine and pyrimidine bases, shown as the nucleosides. (a) Minor bases of DNA. 5-Methylcytidine occurs in the DNA of animals and higher plants, -methyladenosine in bacterial DNA, and 5-hydroxymethylcytidine in the DNA of animals and of bacteria infected with certain bacteriophages. (b) Some minor bases of tRNAs. Inosine contains the base hypoxanthine. Note that pseudouridine, like uridine, contains uracil; they are distinct in the point of attachment to the ribose — in uridine, uracil is attached through N-1, the usual attachment point for pyrimidines; in pseudouridine, uracil is attached through C-5.
Key Convention
The nomenclature for the minor bases can be confusing. Like the major bases, many minor bases have common names — hypoxanthine, for example, shown as its nucleoside inosine in Figure 8-5. When an atom in the purine ring or the pyrimidine ring is substituted, the usual convention (used here) is simply to indicate the ring position of the substituent by its number — for example, 5-methylcytosine, 7-methylguanine, and 5-hydroxymethylcytosine (shown as the nucleosides in Fig. 8-5). The element to which the substituent is attached (N, C, O) is not identified. The convention changes when the substituted atom is exocyclic (i.e., not within the ring structure), in which case the type of atom is identified, and the ring position to which it is attached is denoted with a superscript. The amino nitrogen attached to C-6 of adenine is ; similarly, the carbonyl oxygen and amino nitrogen at C-6 and C-2 of guanine are and , respectively. Examples of this nomenclature are -methyladenosine and -methylguanosine (Fig. 8-5).
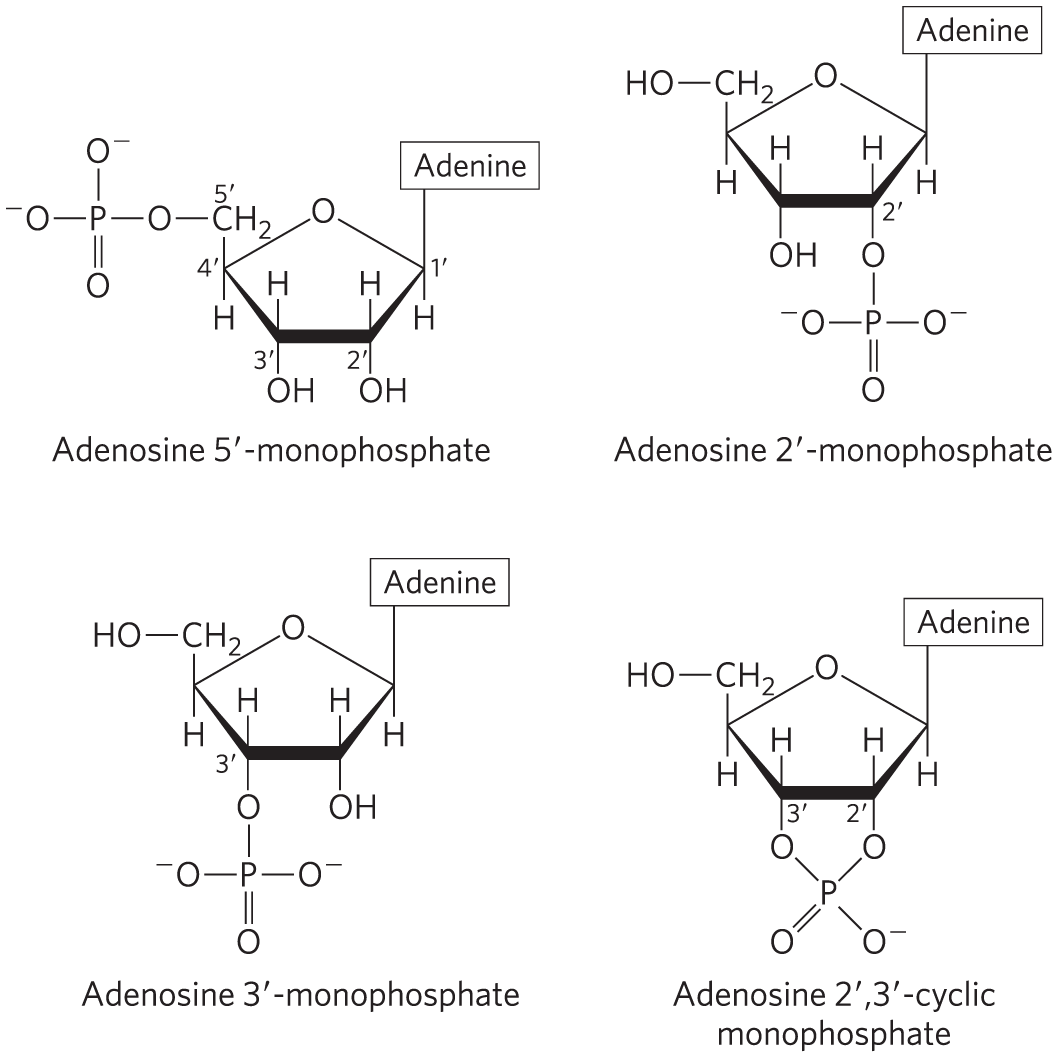
Cells also contain nucleotides with phosphate groups in positions other than on the carbon (Fig. 8-6). Ribonucleoside ,-cyclic monophosphates are isolatable intermediates, and ribonucleoside -monophosphates are end products of the hydrolysis of RNA by certain ribonucleases. Other variations are adenosine ,-cyclic monophosphate (cAMP) and guanosine ,-cyclic monophosphate (cGMP), considered at the end of this chapter.
FIGURE 8-6 Some adenosine monophosphates. Adenosine -monophosphate, -monophosphate, and ,-cyclic monophosphate are formed by enzymatic and alkaline hydrolysis of RNA.
Phosphodiester Bonds Link Successive Nucleotides in Nucleic Acids
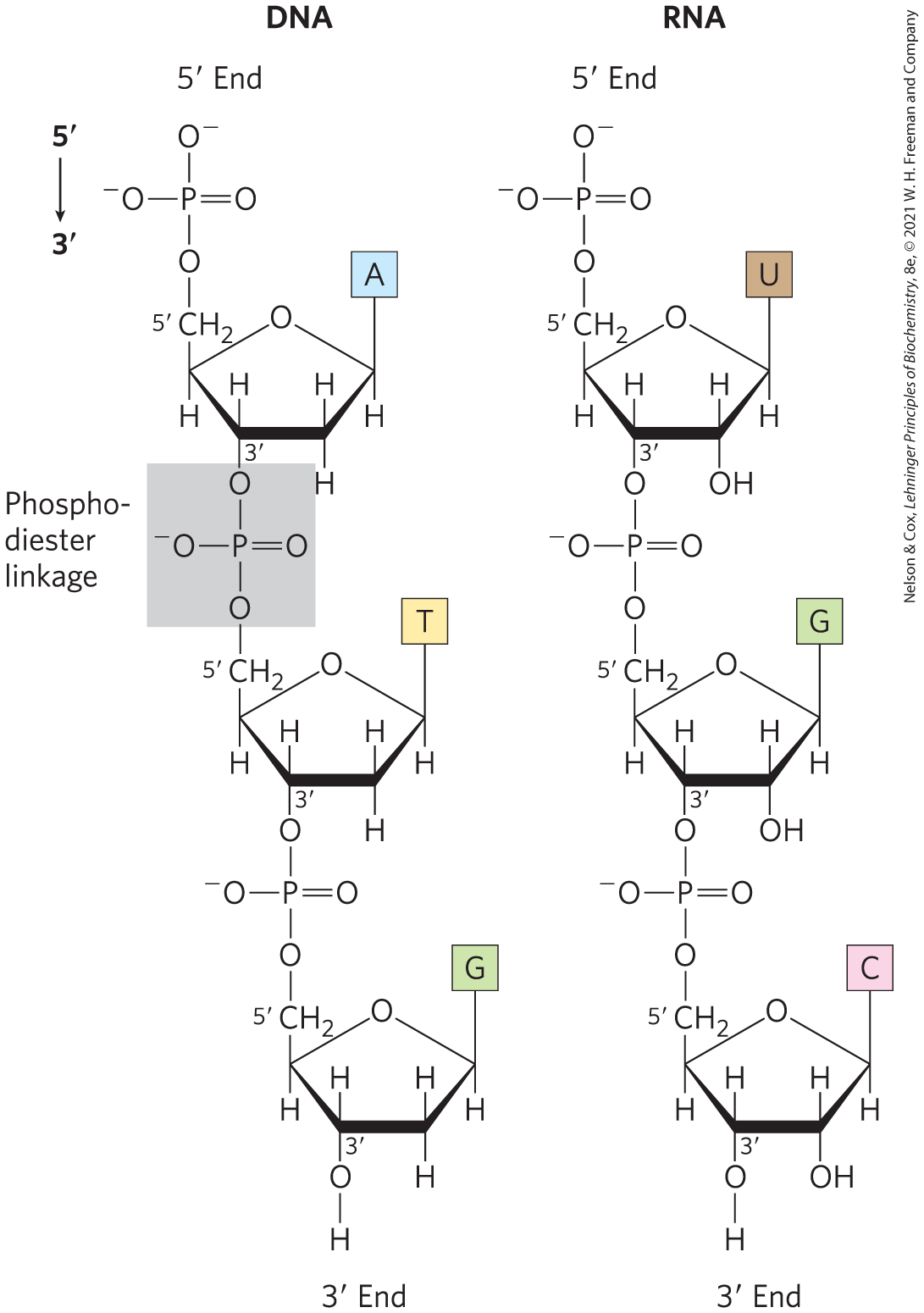
The successive nucleotides of both DNA and RNA are covalently linked through phosphate-group “bridges,” in which the -phosphate group of one nucleotide unit is joined to the -hydroxyl group of the next nucleotide, creating a phosphodiester linkage (Fig. 8-7). Thus the covalent backbones of nucleic acids consist of alternating phosphate and pentose residues, and the nitrogenous bases may be regarded as side groups joined to the backbone at regular intervals. The backbones of both DNA and RNA are hydrophilic. The hydroxyl groups of the sugar residues form hydrogen bonds with water. The phosphate groups, with a near 0, are completely ionized and negatively charged at pH 7, and the negative charges are generally neutralized by ionic interactions with positive charges on proteins, metal ions, and polyamines.
FIGURE 8-7 Phosphodiester linkages in the covalent backbone of DNA and RNA. The phosphodiester bonds (one of which is shaded in the DNA) link successive nucleotide units. The backbone of alternating pentose and phosphate groups in both types of nucleic acid is highly polar. The and ends of the macromolecule may be free or may have an attached phosphoryl group.
Key Convention
All the phosphodiester linkages in DNA and RNA have the same orientation along the chain (Fig. 8-7), giving each linear nucleic acid strand a specific polarity and distinct and ends. By definition, the end lacks a nucleotide attached at the position, and the end lacks a nucleotide attached at the position. Other groups (most often one or more phosphates) may be present on one or both ends. The orientation of a strand of nucleic acid refers to the ends of the strand and the orientation of individual nucleotides, not the orientation of the individual phosphodiester bonds linking its constituent nucleotides.
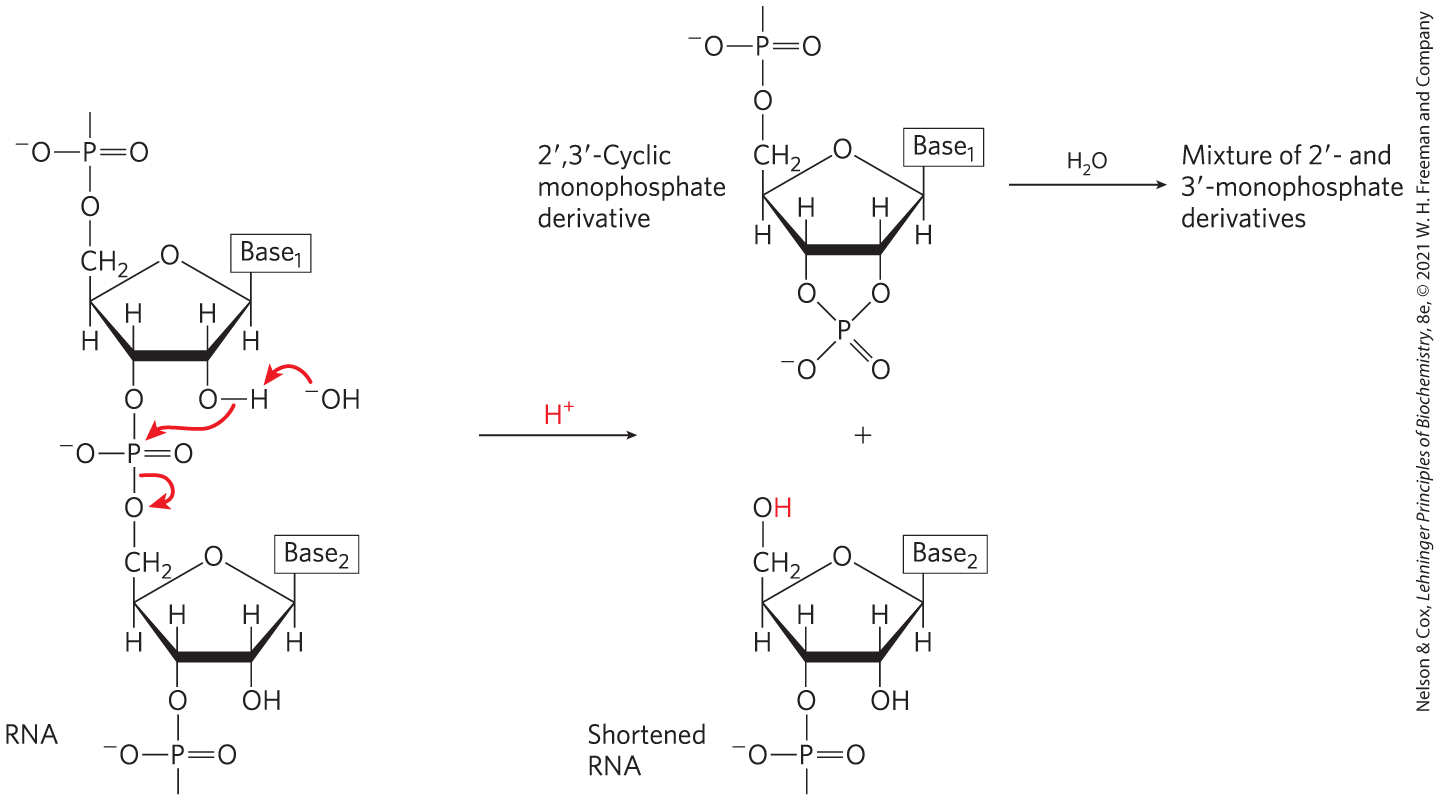
The covalent backbone of DNA and RNA is subject to slow, nonenzymatic hydrolysis of the phosphodiester bonds. In the test tube, RNA is hydrolyzed rapidly under alkaline conditions, but DNA is not; the -hydroxyl groups in RNA (absent in DNA) are directly involved in the process. Cyclic ,-monophosphate nucleotides are the first products of the action of alkali on RNA and are rapidly hydrolyzed further to yield a mixture of - and -nucleoside monophosphates (Fig. 8-8).
FIGURE 8-8 Hydrolysis of RNA under alkaline conditions. The hydroxyl acts as a nucleophile in an intramolecular displacement. The ,-cyclic monophosphate derivative is further hydrolyzed to a mixture of - and -monophosphates. DNA, which lacks hydroxyls, is stable under similar conditions.
The nucleotide sequences of nucleic acids can be represented schematically, as illustrated below by a segment of DNA with five nucleotide units. The phosphate groups are symbolized by , and each deoxyribose is symbolized by a vertical line, from at the top to at the bottom (but keep in mind that the sugar is always in its closed-ring β-furanose form in nucleic acids). The connecting lines between nucleotides (which pass through ) are drawn diagonally from the middle () of the deoxyribose of one nucleotide to the bottom () of the next.
Some simpler representations of this pentadeoxyribonucleotide are , pApCpGpTpA, and pACGTA.
Key Convention
The sequence of a single strand of nucleic acid is always written with the end at the left and the end at the right — that is, in the direction.
A short nucleic acid is referred to as an oligonucleotide. The definition of “short” is somewhat arbitrary, but polymers containing 50 or fewer nucleotides are generally called oligonucleotides. A longer nucleic acid is called a polynucleotide.
The Properties of Nucleotide Bases Affect the Three-Dimensional Structure of Nucleic Acids
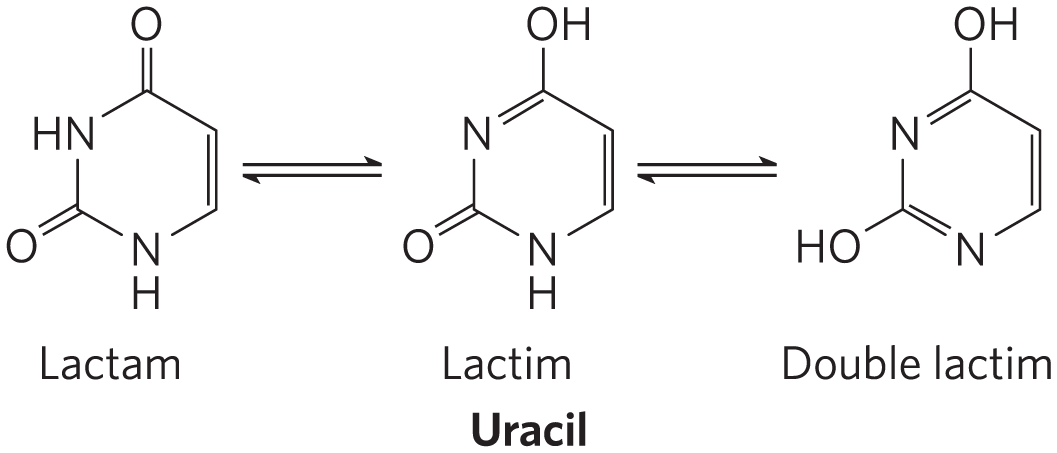
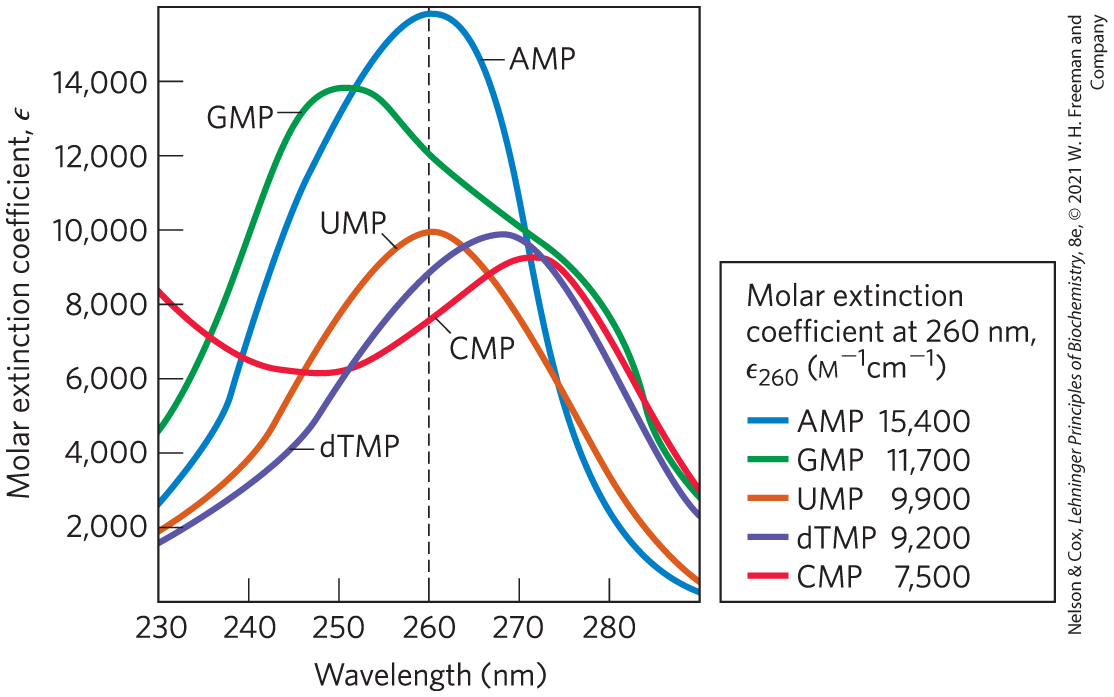
Free pyrimidines and purines are weakly basic compounds and thus are called bases. The purines and pyrimidines common in DNA and RNA are aromatic molecules (Fig. 8-2), a property with important consequences for the structure, electron distribution, and light absorption of nucleic acids. Electron delocalization among atoms in the ring gives most of the bonds in the ring partial double-bond character. One result is that pyrimidines are planar molecules and purines are very nearly planar, with a slight pucker. Free pyrimidine and purine bases may exist in two or more tautomeric forms depending on the pH. Uracil, for example, occurs in several readily interconverted forms called tautomers — lactam, lactim, and double lactim forms (Fig. 8-9). The structures shown in Figure 8-2 are the tautomers that predominate at pH 7.0. All nucleotide bases absorb UV light, and nucleic acids are characterized by a strong absorption at wavelengths near 260 nm (Fig. 8-10).
FIGURE 8-9 Tautomeric forms of uracil. The lactam form predominates at pH 7.0; the other forms become more prominent as pH decreases. The other free pyrimidines and the free purines also have tautomeric forms, but they are more rarely encountered.
FIGURE 8-10 Absorption spectra of the common nucleotides. The spectra are shown as the variation in molar extinction coefficient with wavelength. The molar extinction coefficients at 260 nm and pH 7.0 () are listed in the table. The spectra of corresponding ribonucleotides and deoxyribonucleotides, as well as the nucleosides, are essentially identical. For mixtures of nucleotides, a wavelength of 260 nm (dashed vertical line) is used for absorption measurements.
The purine and pyrimidine bases are hydrophobic and relatively insoluble in water at the near-neutral pH of the cell. At acidic or alkaline pH, the bases become charged and their solubility in water increases. Hydrophobic stacking interactions in which two or more bases are positioned with the planes of their rings parallel (like a stack of coins) are one of two important modes of interaction between bases in nucleic acids. The stacking also involves a combination of van der Waals and dipole-dipole interactions between the bases. Base stacking helps to minimize contact of the bases with water, and base-stacking interactions are very important in stabilizing the three-dimensional structure of nucleic acids, as described later.
The functional groups of pyrimidines and purines are ring nitrogens, carbonyl groups, and exocyclic amino groups. Hydrogen bonds involving the amino and carbonyl groups are the most important mode of complementary interaction between two (and occasionally three or four) complementary strands of nucleic acid. The most common hydrogen-bonding patterns are those defined by James D. Watson and Francis Crick in 1953, in which A bonds specifically to T (or U) and G bonds to C (Fig. 8-11). These two types of base pairs predominate in double-stranded DNA and RNA, and the tautomers shown in Figure 8-2 are responsible for these patterns. It is this specific pairing of bases that permits the duplication of genetic information.
FIGURE 8-11 Hydrogen-bonding patterns in the base pairs defined by Watson and Crick. Here, as elsewhere, hydrogen bonds are represented by three blue lines.
SUMMARY 8.1 Some Basic Definitions and Conventions
A nucleotide consists of a nitrogenous base (purine or pyrimidine), a pentose sugar, and one or more phosphate groups. If no phosphate is present, the combination of the pentose sugar and the nitrogenous base is a nucleoside.
Nucleic acids are polymers of nucleotides, joined together by phosphodiester linkages between the -hydroxyl group of one pentose and the -hydroxyl group of the next.
There are two types of nucleic acid: RNA and DNA. The nucleotides in RNA contain ribose, and the common pyrimidine bases are uracil and cytosine. In DNA, the nucleotides contain -deoxyribose, and the common pyrimidine bases are thymine and cytosine. The primary purines are adenine and guanine in both RNA and DNA. The nitrogenous bases have a hydrophobic character and interact via base-stacking interactions.
 The storage of biological information and the transmission of that information from one generation to the next are the only known functions of DNA.
The storage of biological information and the transmission of that information from one generation to the next are the only known functions of DNA.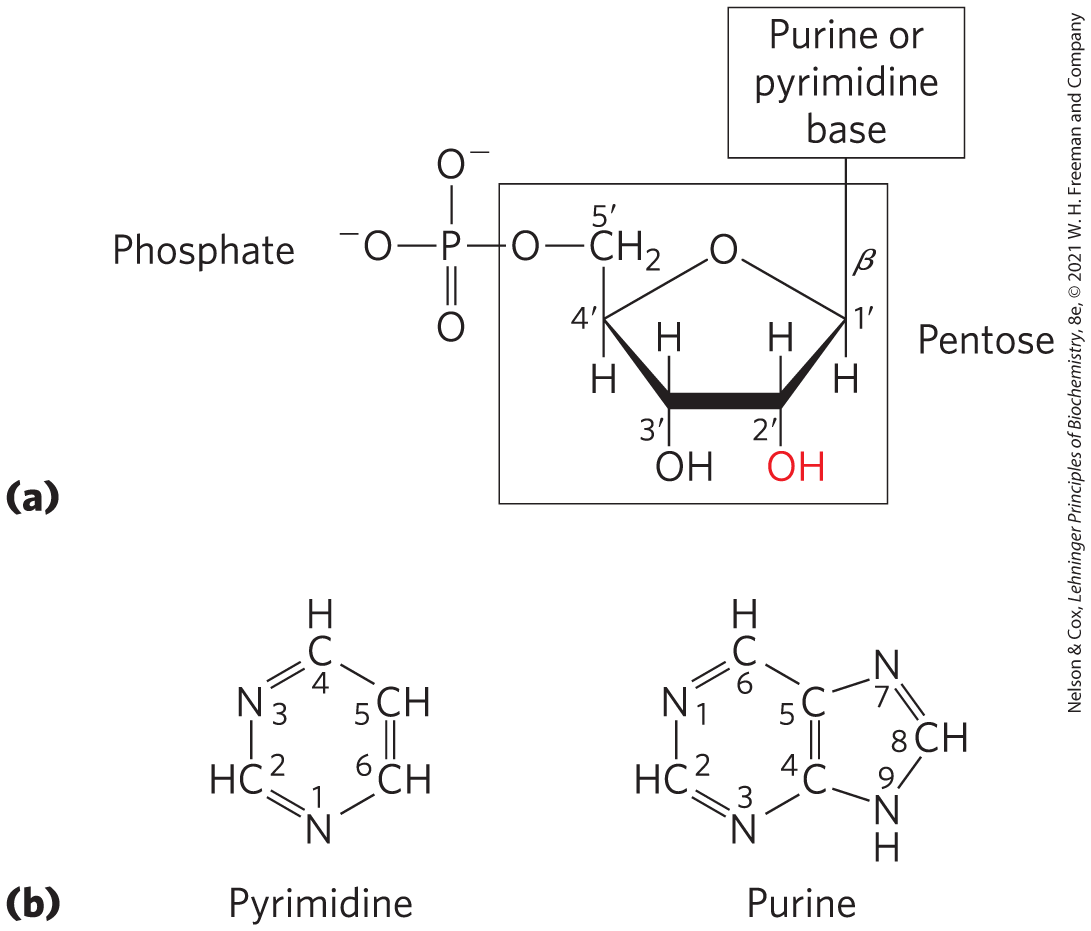

 , and each deoxyribose is symbolized by a vertical line, from at the top to at the bottom (but keep in mind that the sugar is always in its closed-ring β-furanose form in nucleic acids). The connecting lines between nucleotides (which pass through
, and each deoxyribose is symbolized by a vertical line, from at the top to at the bottom (but keep in mind that the sugar is always in its closed-ring β-furanose form in nucleic acids). The connecting lines between nucleotides (which pass through 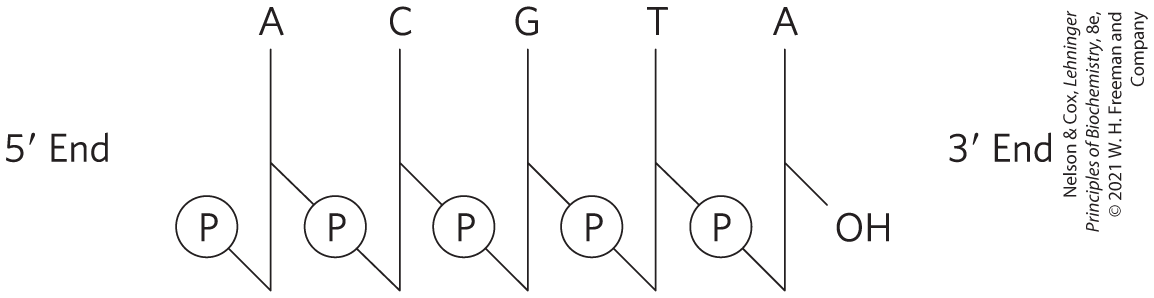
 It is this specific pairing of bases that permits the duplication of genetic information.
It is this specific pairing of bases that permits the duplication of genetic information.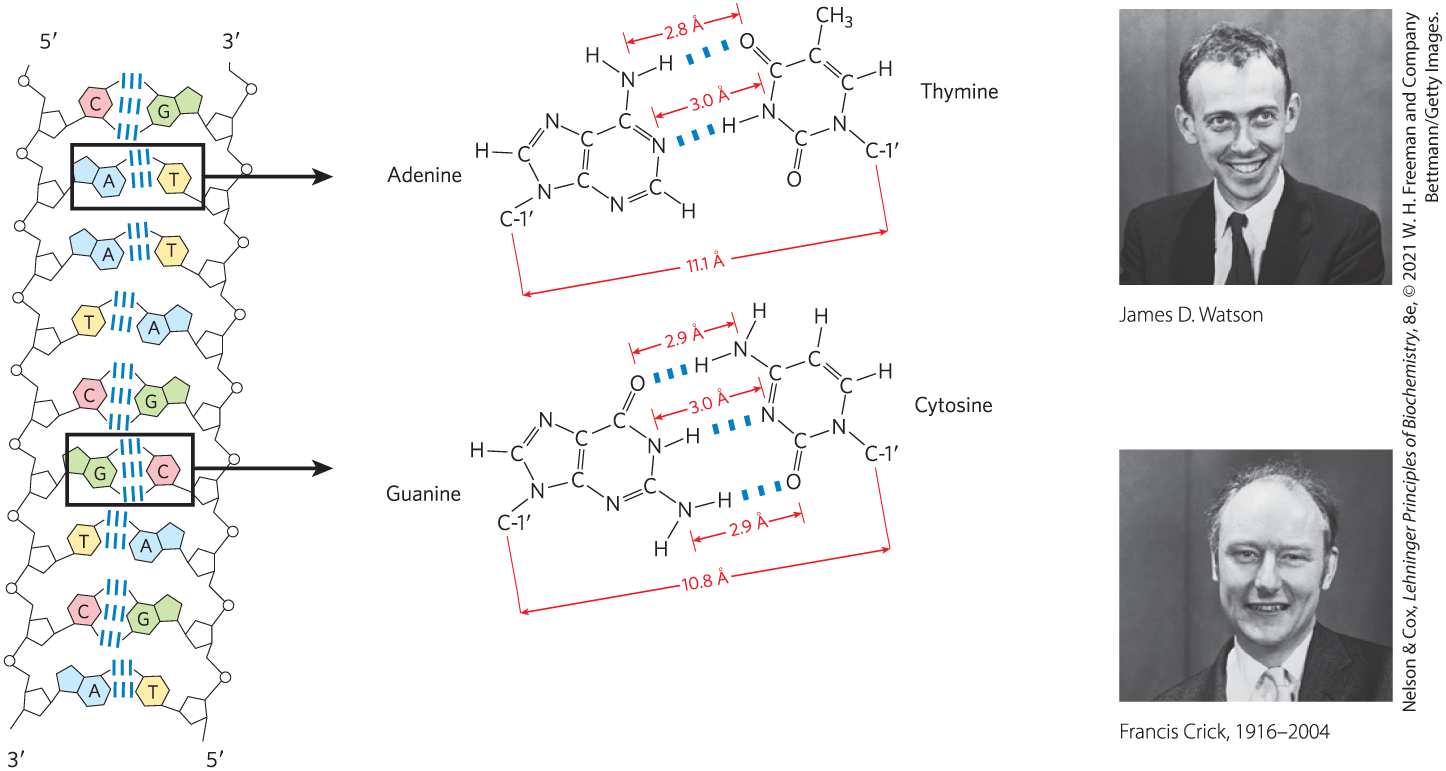
 A nucleotide consists of a nitrogenous base (purine or pyrimidine), a pentose sugar, and one or more phosphate groups. If no phosphate is present, the combination of the pentose sugar and the nitrogenous base is a nucleoside.
A nucleotide consists of a nitrogenous base (purine or pyrimidine), a pentose sugar, and one or more phosphate groups. If no phosphate is present, the combination of the pentose sugar and the nitrogenous base is a nucleoside.