27.1 The Genetic Code
By the 1960s, it was apparent that at least three nucleotide residues of DNA are necessary to encode each amino acid. The four code letters of DNA (A, T, G, and C) in groups of two can yield only different combinations, insufficient to encode 20 amino acids. Groups of three, however, yield different combinations. Deciphering the genetic code quickly became a major goal.
The Genetic Code Was Cracked Using Artificial mRNA Templates
Several key properties of the genetic code were established in early genetic studies. A codon is a triplet of nucleotides that codes for a specific amino acid. In all living systems, translation occurs in such a way that these nucleotide triplets are read in a successive, nonoverlapping fashion (Figs. 27-3, 27-4). A specific first codon in the sequence establishes the reading frame, in which a new codon begins every three nucleotide residues. There is no punctuation between codons for successive amino acid residues. The amino acid sequence of a protein is defined by a linear sequence of contiguous triplets. In principle, any given single-stranded DNA or mRNA sequence has three possible reading frames. Each reading frame gives a different sequence of codons (Fig. 27-5), but only one is likely to encode a given protein. A key question remained: what were the three-letter code words for each amino acid?
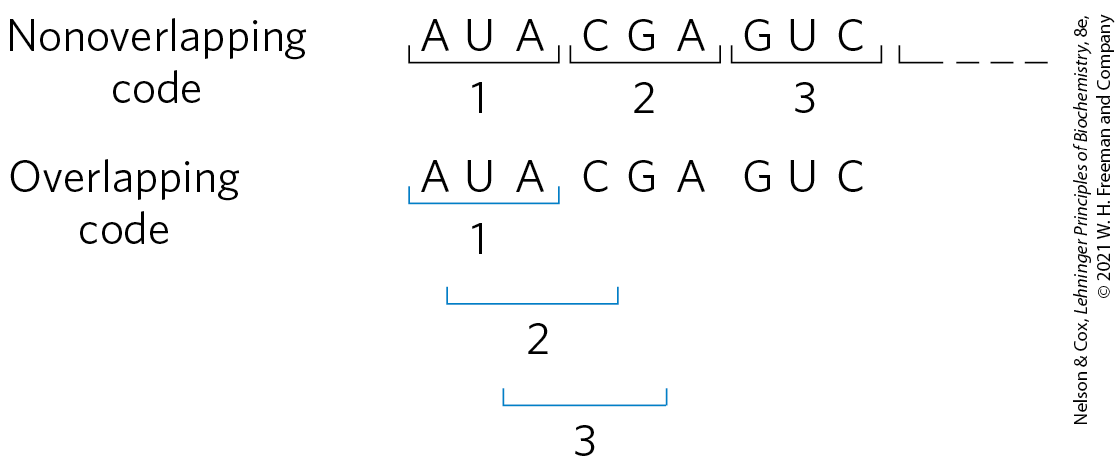
FIGURE 27-3 Overlapping versus nonoverlapping genetic codes. In a nonoverlapping code, codons (numbered consecutively) do not share nucleotides. In an overlapping code, some nucleotides in the mRNA are shared by different codons. In a triplet code with maximum overlap, many nucleotides, such as the third nucleotide from the left (A), are shared by three codons. A nonoverlapping code provides much more flexibility in the triplet sequence of neighboring codons and therefore in the possible amino acid sequences designated by the code.
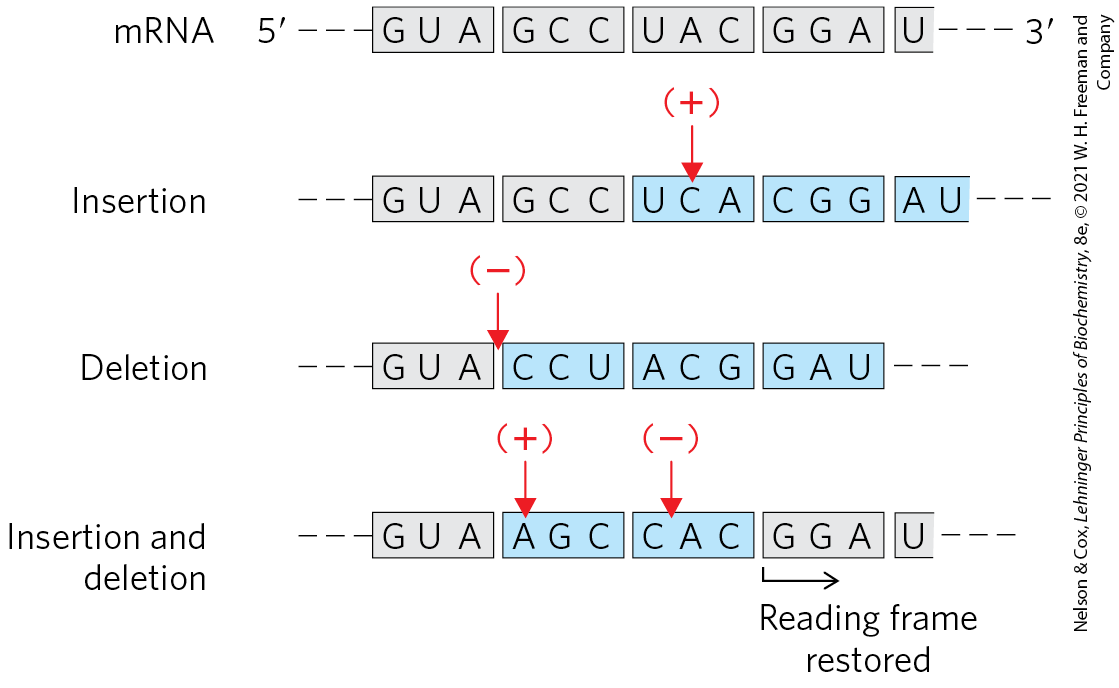
FIGURE 27-4 The triplet, nonoverlapping code. Evidence for the general nature of the genetic code came from many types of experiments, including genetic experiments on the effects of deletion and insertion mutations. Inserting or deleting one base pair (shown here in the mRNA transcript) alters the sequence of all amino acids coded by the mRNA following the change. Combining insertion and deletion mutations affects some amino acids but can eventually restore the correct amino acid sequence. Adding or subtracting three nucleotides (not shown) leaves the remaining triplets intact, providing evidence that a codon has three, rather than four or five, nucleotides. The triplet codons shaded in gray are those transcribed from the original gene; codons shaded in blue are new codons resulting from the insertion or deletion mutations.

FIGURE 27-5 Reading frames in the genetic code. In a triplet, nonoverlapping code, all mRNAs have three potential reading frames, shaded here in different colors. The triplets, and hence the amino acids specified, are different in each reading frame.
In 1961, Marshall Nirenberg and J. Heinrich Matthaei reported the first breakthrough. They incubated synthetic polyuridylate, poly(U), with an Escherichia coli extract, GTP, ATP, and a mixture of the 20 amino acids in 20 different tubes, each tube containing a different radioactively labeled amino acid. Because poly(U) mRNA is made up of many successive UUU triplets, it should promote the synthesis of a polypeptide containing only the amino acid encoded by UUU. A radioactive polypeptide was formed only in the tube containing radioactive phenylalanine. Nirenberg and Matthaei therefore concluded that the triplet codon UUU encodes phenylalanine. The same approach soon revealed that polycytidylate, poly(C), encodes a polypeptide containing only proline (polyproline), and that polyadenylate, poly(A), encodes polylysine. Polyguanylate did not generate any polypeptide in this experiment because it spontaneously forms tetraplexes (see Fig. 8-20d) that cannot be bound by ribosomes.
The synthetic polynucleotides used in such experiments were prepared by using polynucleotide phosphorylase (p. 987), which catalyzes the formation of RNA polymers starting from ADP, UDP, CDP, and GDP. This enzyme, discovered by physician/biochemist Severo Ochoa, requires no template and makes polymers with a base composition that directly reflects the relative concentrations of the nucleoside -diphosphate precursors in the medium. If polynucleotide phosphorylase is presented with only UDP, it makes only poly(U). If it is presented with a mixture of five parts ADP and one part CDP, it makes a polymer in which about five-sixths of the residues are adenylate and one-sixth is cytidylate. This random polymer is likely to have many triplets of the sequence AAA; smaller numbers of AAC, ACA, and CAA triplets; relatively few ACC, CCA, and CAC triplets; and very few CCC triplets (Table 27-1). Using a variety of artificial mRNAs made by polynucleotide phosphorylase from different starting mixtures of ADP, GDP, UDP, and CDP, the Nirenberg and Ochoa groups soon identified the base compositions of the triplets coding for almost all the amino acids. Although these experiments revealed the base composition of the coding triplets, they usually could not reveal the sequence of the bases.
| Amino acid | Observed frequency of incorporation | Tentative assignment for nucleotide composition of corresponding codona | Expected frequency of incorporation based on assignment |
|---|---|---|---|
Asparagine |
24 |
20 |
|
Glutamine |
24 |
20 |
|
Histidine |
6 |
4 |
|
Lysine |
100 |
AAA |
100 |
Proline |
7 |
4.8 |
|
Threonine |
26 |
24 |
|
Note: Presented here is a summary of data from one of the early experiments designed to elucidate the genetic code. A synthetic RNA containing only A and C residues in 5:1 ratio directed polypeptide synthesis, and both the identity and the quantity of incorporated amino acids were determined. Based on the relative abundance of A and C residues in the synthetic RNA, and assigning the codon AAA (the most likely codon) a frequency of 100, there should be three different codons of composition , each at a relative frequency of 20; three of composition , each at a relative frequency of 4.0; and CCC at a relative frequency of 0.8. The CCC assignment was based on information derived from prior studies with poly(C). Where two tentative codon assignments are made, both are proposed to code for the same amino acid. a These designations of nucleotide composition contain no information on nucleotide sequence (except, of course, AAA and CCC). |
|||
Key convention
Much of the following discussion deals with tRNAs. The amino acid specified by a tRNA is indicated by a superscript, such as , and the aminoacylated tRNA is designated by a hyphenated name, such as or .

In 1964, Nirenberg and Philip Leder achieved another experimental breakthrough. Isolated E. coli ribosomes would bind a specific aminoacyl-tRNA in the presence of the corresponding synthetic polynucleotide messenger. For example, ribosomes incubated with poly(U) and bind both RNAs, but if the ribosomes are incubated with poly(U) and some other aminoacyl-tRNA, the aminoacyl-tRNA is not bound, because it does not recognize the UUU triplets in poly(U) (Table 27-2). Even trinucleotides could promote specific binding of appropriate tRNAs, so these experiments could be carried out with chemically synthesized small oligonucleotides. With this technique, researchers determined which aminoacyl-tRNA bound to 54 of the 64 possible triplet codons. For some codons, either no aminoacyl-tRNA or more than one would bind. Another method was needed to complete and confirm the entire genetic code.
| Relative increase in -labeled aminoacyl-tRNA bound to ribosomea | |||
|---|---|---|---|
| Trinucleotide | |||
UUU |
4.6 |
0 |
0 |
AAA |
0 |
7.7 |
0 |
CCC |
0 |
0 |
3.1 |
Information from M. Nirenberg and P. Leder, Science 145:1399, 1964. aEach number represents the factor by which the amount of bound increased when the indicated trinucleotide was present, relative to a control with no trinucleotide. |
|||
At about this time, a complementary approach was provided by H. Gobind Khorana, who developed chemical methods to synthesize polyribonucleotides with defined, repeating sequences of two to four bases. The polypeptides produced by these mRNAs had one or a few amino acids in repeating patterns. These patterns, when combined with information from the random polymers used by Nirenberg and colleagues, permitted unambiguous codon assignments. The copolymer , for example, has alternating ACA and CAC codons: ACACACACACACACA. The polypeptide synthesized on this messenger contained equal amounts of threonine and histidine. Given that a histidine codon has one A and two Cs (Table 27-1), CAC must code for histidine and ACA for threonine.
Consolidation of the results from many experiments permitted assignment of 61 of the 64 possible codons. The other three were identified as termination codons, in part because they disrupted amino acid coding patterns when they occurred in a synthetic RNA polymer (Fig. 27-6). Meanings for all the triplet codons (tabulated in Fig. 27-7) were established by 1966 and have been verified in many different ways. The cracking of the genetic code is regarded as one of the most important scientific discoveries of the twentieth century.

FIGURE 27-6 Effect of a termination codon in a repeating tetranucleotide. Termination codons (light red) are encountered every fourth codon in three different reading frames (shown in different colors). Dipeptides or tripeptides are synthesized, depending on where the ribosome initially binds.
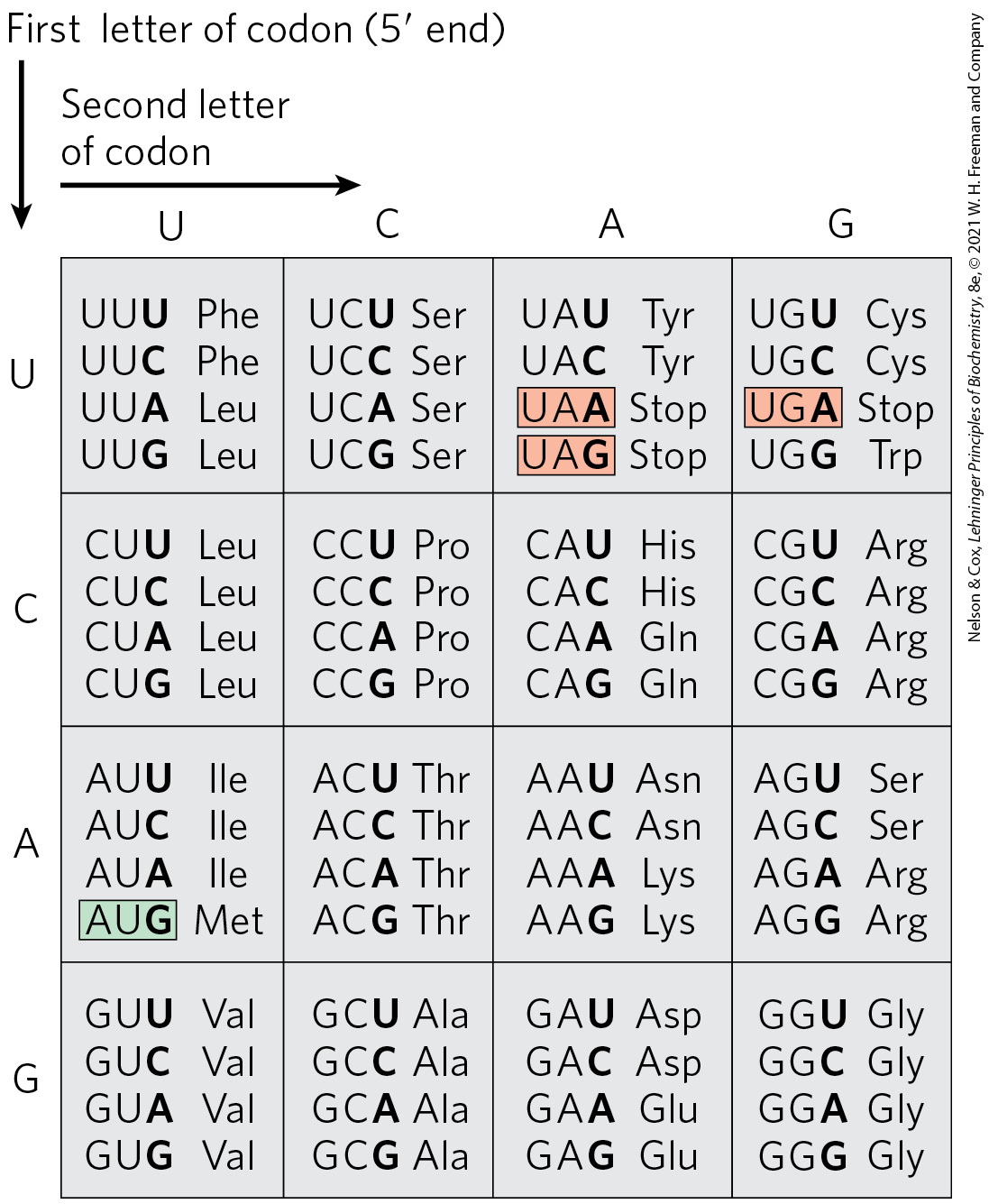
FIGURE 27-7 “Dictionary” of amino acid code words in mRNAs. The codons are written in the direction. The third base of each codon (in bold type) plays a lesser role in specifying an amino acid than the first two. The three termination codons are shaded in light red, the initiation codon AUG in green. All the amino acids except methionine and tryptophan have more than one codon. In most cases, codons that specify the same amino acid differ only at the third base.
Codons are the key to the translation of genetic information, directing the synthesis of specific proteins. The reading frame is set when translation of an mRNA molecule begins, and it is maintained as the synthetic machinery reads sequentially from one triplet to the next. If the initial reading frame is off by one or two bases, or if translation somehow skips a nucleotide in the mRNA, all the subsequent codons will be out of register; the result is usually a “missense” protein with a garbled amino acid sequence.
 Codons are the key to the translation of genetic information, directing the synthesis of specific proteins. The reading frame is set when translation of an mRNA molecule begins, and it is maintained as the synthetic machinery reads sequentially from one triplet to the next. If the initial reading frame is off by one or two bases, or if translation somehow skips a nucleotide in the mRNA, all the subsequent codons will be out of register; the result is usually a “missense” protein with a garbled amino acid sequence.
Codons are the key to the translation of genetic information, directing the synthesis of specific proteins. The reading frame is set when translation of an mRNA molecule begins, and it is maintained as the synthetic machinery reads sequentially from one triplet to the next. If the initial reading frame is off by one or two bases, or if translation somehow skips a nucleotide in the mRNA, all the subsequent codons will be out of register; the result is usually a “missense” protein with a garbled amino acid sequence.Several codons serve special functions (Fig. 27-7). The initiation codon AUG is the most common signal for the beginning of a polypeptide in all cells, in addition to coding for Met residues in internal positions of polypeptides. The termination codons (UAA, UAG, and UGA), also called stop codons or nonsense codons, normally signal the end of polypeptide synthesis and do not code for any known amino acids.
As described in Section 27.2, initiation of protein synthesis in the cell is an elaborate process that relies on initiation codons and other signals in the mRNA. In retrospect, the experiments of Nirenberg, Khorana, and others to identify codon function should not have worked in the absence of initiation codons. Serendipitously, experimental conditions caused the normally complex initiation requirements for protein synthesis (unknown at the time) to be relaxed. Diligence combined with chance to produce a breakthrough — a common occurrence in the history of biochemistry.
 In retrospect, the experiments of Nirenberg, Khorana, and others to identify codon function should not have worked in the absence of initiation codons. Serendipitously, experimental conditions caused the normally complex initiation requirements for protein synthesis (unknown at the time) to be relaxed. Diligence combined with chance to produce a breakthrough — a common occurrence in the history of biochemistry.
In retrospect, the experiments of Nirenberg, Khorana, and others to identify codon function should not have worked in the absence of initiation codons. Serendipitously, experimental conditions caused the normally complex initiation requirements for protein synthesis (unknown at the time) to be relaxed. Diligence combined with chance to produce a breakthrough — a common occurrence in the history of biochemistry.In a random sequence of nucleotides, 1 in every 20 codons in each reading frame is, on average, a termination codon. In general, a reading frame without a termination codon among 50 or more consecutive codons is referred to as an open reading frame (ORF). Long ORFs usually correspond to genes that encode proteins. In the analysis of sequence databases, sophisticated programs are used to search for ORFs in order to find genes among the often-huge background of nongenic DNA. An uninterrupted gene coding for a typical protein with a molecular weight of 60,000 would require an ORF with 500 or more codons.
A striking feature of the genetic code is that an amino acid may be specified by more than one codon, so the code is described as degenerate. This does not suggest that the code is flawed: although an amino acid may have two or more codons, each codon specifies only one amino acid. The degeneracy of the code is not uniform. Whereas methionine and tryptophan have single codons, for example, three amino acids (Arg, Leu, Ser) have six codons, five amino acids have four, isoleucine has three, and nine amino acids have two (Table 27-3).
| Amino acid | Number of codons | Amino acid | Number of codons |
|---|---|---|---|
Met |
1 |
Tyr |
2 |
Trp |
1 |
Ile |
3 |
Asn |
2 |
Ala |
4 |
Asp |
2 |
Gly |
4 |
Cys |
2 |
Pro |
4 |
Gln |
2 |
Thr |
4 |
Glu |
2 |
Val |
4 |
His |
2 |
Arg |
6 |
Lys |
2 |
Leu |
6 |
Phe |
2 |
Ser |
6 |
The genetic code is nearly universal. With the intriguing exception of a few minor variations in mitochondria, some bacteria, and some single-celled eukaryotes, amino acid codons are identical in all species examined so far. Human beings, E. coli, tobacco plants, amphibians, and viruses share the same genetic code. This suggests that all life-forms have a common evolutionary ancestor, whose genetic code has been preserved throughout biological evolution. Even the variations (Box 27-1) reinforce this theme.
Wobble Allows Some tRNAs to Recognize More than One Codon
When several different codons specify one amino acid, the difference between them usually lies at the third base position (at the end). For example, alanine is encoded by the triplets GCU, GCC, GCA, and GCG. The codons for most amino acids can be symbolized by or The first two letters of each codon are the primary determinants of specificity, a feature that has some interesting consequences.
Transfer RNAs base-pair with mRNA codons at a three-base sequence on the tRNA called the anticodon. The first base of the codon in mRNA (read in the direction) pairs with the third base of the anticodon (Fig. 27-8a). If the anticodon triplet of a tRNA recognized only one codon triplet through Watson-Crick base pairing at all three positions, cells would have a different tRNA for each amino acid codon. This is not the case, however, because the anticodons in some tRNAs include the nucleotide inosinate (designated I), which contains the uncommon base hypoxanthine (see Fig. 8-5b). Inosinate can form hydrogen bonds with three different nucleotides — A, U, and C (Fig. 27-8b) — although these pairings are much weaker than the hydrogen bonds of Watson-Crick base pairs and . In yeast, one has the anticodon , which recognizes three arginine codons: , and . The first two bases are identical (CG) and form strong Watson-Crick base pairs with the corresponding bases of the anticodon, but the third base (A, U, or C) forms rather weak hydrogen bonds with the I residue at the first position of the anticodon.
 Transfer RNAs base-pair with mRNA codons at a three-base sequence on the tRNA called the
Transfer RNAs base-pair with mRNA codons at a three-base sequence on the tRNA called the 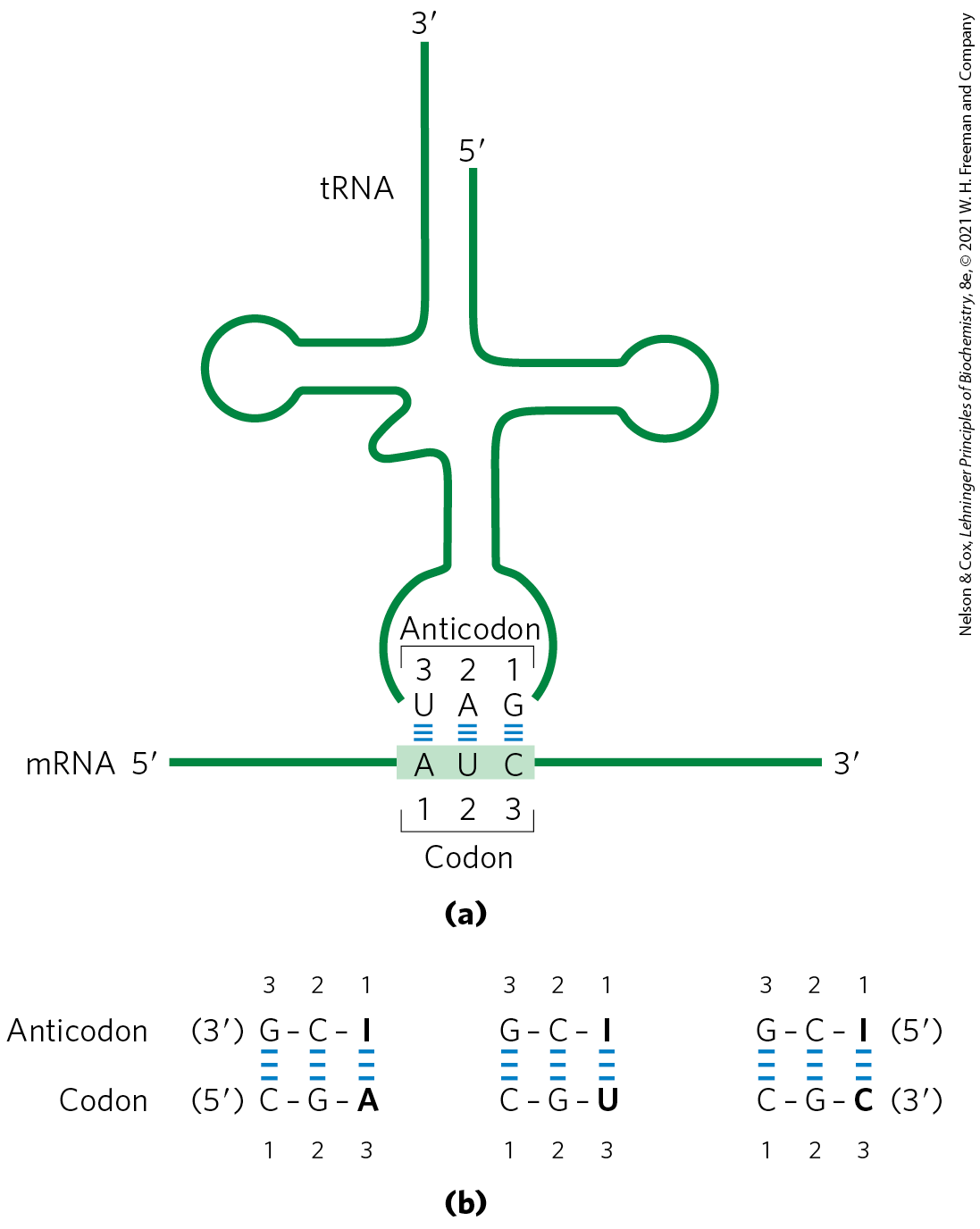
FIGURE 27-8 Pairing relationship of codon and anticodon. (a) Alignment of the two RNAs is antiparallel. The tRNA is shown in the traditional cloverleaf configuration. (b) Three different codon pairing relationships are possible when the tRNA anticodon contains inosinate.
Examination of these and other codon-anticodon pairings led Crick to conclude that the third base of most codons pairs rather loosely with the corresponding base of its anticodon; to use his picturesque word, the third base of such codons (and the first base of their corresponding anticodons) “wobbles.” Crick proposed a set of four relationships called the wobble hypothesis:
- The first two bases of an mRNA codon always form strong Watson-Crick base pairs with the corresponding bases of the tRNA anticodon and confer most of the coding specificity.
- The first base of the anticodon (reading in the direction; this pairs with the third base of the codon) determines the number of codons recognized by the tRNA. When the first base of the anticodon is C or A, base pairing is specific and only one codon is recognized by that tRNA. When the first base is U or G, binding is less specific and two different codons may be read. When inosine (I) is the first (wobble) nucleotide of an anticodon, three different codons can be recognized — the maximum number for any tRNA. These relationships are summarized in Table 27-4.
- When an amino acid is specified by several different codons, the codons that differ in either of the first two bases require different tRNAs.
- A minimum of 32 tRNAs are required to translate all 61 codons (31 to encode the amino acids, 1 for initiation).
TABLE 27-4 How the Wobble Base of the Anticodon Determines the Number of Codons a tRNA Can Recognize
1. One codon recognized:
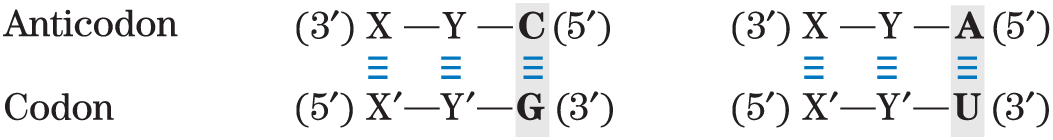
2. Two codons recognized:
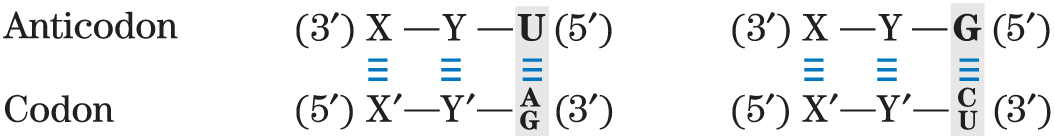
3. Three codons recognized:
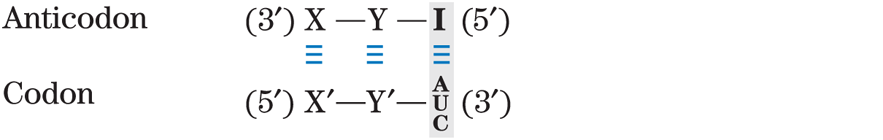
Note: X and Y denote bases complementary to and capable of strong Watson-Crick base pairing with and , respectively. Wobble bases — in the position of codons and position of anticodons — are shaded.
The wobble (or third) base of the codon contributes to specificity, but because it pairs only loosely with its corresponding base in the anticodon, it permits rapid dissociation of the tRNA from its codon during protein synthesis. If all three bases of a codon engaged in strong Watson-Crick pairing with the three bases of the anticodon, tRNAs would dissociate too slowly and this would limit the rate of protein synthesis. Codon-anticodon interactions balance the requirements for accuracy and speed.
Although only 32 tRNAs are required to translate all codons, most cells have more than that. The bacterium E. coli has 47 different tRNA genes. Many of these are present in multiple copies, such that there are 86 total tRNA genes in the E. coli genome.
The Genetic Code Is Mutation-Resistant
The genetic code plays an interesting role in safeguarding the genomic integrity of every living organism. Evolution did not produce a code in which codon assignments appeared at random. Instead, the code is strikingly resistant to the deleterious effects of the most common kinds of mutations — missense mutations, in which a single new base pair replaces another. In the third, or wobble, position of the codon, single base substitutions produce a change in the encoded amino acid only about 25% of the time. Most such changes are thus silent mutations, in which the nucleotide is different but the encoded amino acid remains the same.
Due to the types of spontaneous DNA damage that affect genomes (see Chapter 8), the most frequent missense mutation is a transition mutation, in which a purine is replaced by a purine, or a pyrimidine by a pyrimidine (for example, changed to ). All three codon positions have evolved so that there is some resistance to transition mutations. A mutation in the first position of the codon will usually produce an amino acid coding change, but the change often results in an amino acid with similar chemical properties. This is especially true for the hydrophobic amino acids that dominate the first column of the code shown in Figure 27-7. Consider the Val codon GUU. A change to AUU would substitute Ile for Val. A change to CUU would replace Val with Leu. The resulting changes in the structure and/or function of the protein encoded by that gene would often (but not always) be small.
Computational studies have shown that alternative genetic codes, delineated at random, are almost always less resistant to mutation than the existing code. The results indicate that the code underwent considerable streamlining before the appearance of LUCA, the ancestral cell.
The genetic code tells us how protein sequence information is stored in nucleic acids and provides some clues about how that information is translated into protein.
Translational Frameshifting Affects How the Code Is Read
Once the reading frame has been set during protein synthesis, codons are translated without overlap or punctuation until the ribosomal complex encounters a termination codon. The other two possible reading frames usually contain no useful genetic information. Overlap between two genes would necessarily constrain the possible amino acid sequences encoded by one or both genes in the overlap region. However, to make maximal use of limited (and expensive) genetic information, a few genes are structured so that ribosomes “hiccup” at a certain point in the translation of their mRNAs, changing the reading frame from that point on. This allows two or more related but distinct proteins to be produced from a single transcript.
One of the best-documented examples of translational frameshifting occurs during translation of the mRNA for the overlapping gag and pol genes of the Rous sarcoma virus, a retrovirus (see Fig. 26-31). The reading frame for pol is offset to the left by one base pair (−1 reading frame) relative to the reading frame for gag (Fig. 27-9).

FIGURE 27-9 Translational frameshifting in a retroviral transcript. The gag-pol overlap region in Rous sarcoma virus RNA is shown.
The product of the retroviral pol gene (reverse transcriptase) is translated as a larger polyprotein, on the same mRNA that is used for the Gag protein alone (see Fig. 26-30). The polyprotein, or Gag-Pol protein, is then trimmed to the mature reverse transcriptase by proteolytic digestion. Production of the polyprotein requires a translational frameshift in the overlap region to allow the ribosome to bypass the UAG termination codon at the end of the gag gene (shaded light red in Fig. 27-9).
Frameshifts occur during about 5% of translations of this mRNA, and the Gag-Pol polyprotein (and ultimately reverse transcriptase) is synthesized at about one-twentieth the frequency of the Gag protein, a level that suffices for efficient reproduction of the virus. A similar mechanism produces both the τ and γ subunits of E. coli DNA polymerase III from a single dnaX gene transcript (see footnote to Table 25-2).
Some mRNAs Are Edited before Translation
RNA editing can involve the addition, deletion, or alteration of nucleotides in the RNA in a manner that affects the meaning of the transcript when it is translated. Addition or deletion of nucleotides has been most commonly observed in RNAs originating from the mitochondrial and chloroplast genomes. The initial transcripts of the genes that encode cytochrome oxidase subunit II in some protist mitochondria provide an example of editing by insertion. These transcripts do not correspond precisely to the sequence needed at the carboxyl terminus of the protein product. A posttranscriptional editing process inserts four U residues that shift the translational reading frame of the transcript. The insertions require a special class of guide RNAs (gRNAs; Fig. 27-10) that act as templates for the editing process. The added U residues are all located in a small part of the transcript. Note that the base pairing between the initial transcript and the guide RNA includes several base pairs (blue dots), which are common in RNA molecules.
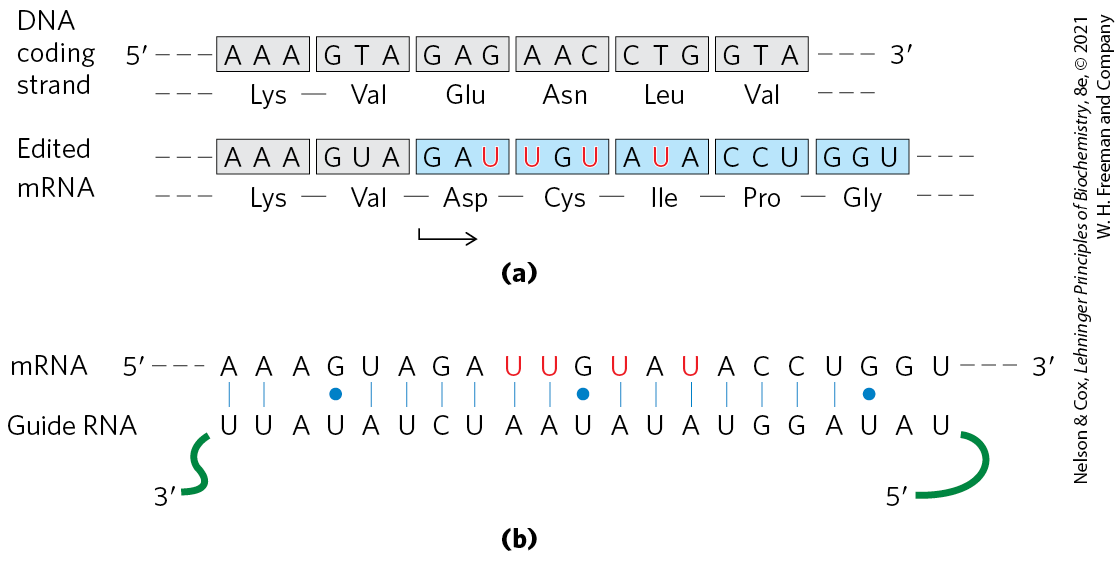
FIGURE 27-10 RNA editing of the transcript of the cytochrome oxidase subunit II gene from Trypanosoma brucei mitochondria. (a) Insertion of four U residues (red) produces a revised reading frame. (b) A special class of guide RNAs, complementary to the edited product, acts as templates for the editing process. Note the presence of three base pairs, signified by blue dots to indicate non-Watson-Crick pairing.
RNA editing by alteration of nucleotides most commonly involves the enzymatic deamination of adenosine or cytidine residues, forming inosine or uridine, respectively (Fig. 27-11), although other base changes have been described. Inosine is interpreted as a G residue during translation. The adenosine deamination reactions are carried out by adenosine deaminases that act on RNA (ADARs). The cytidine deaminations are carried out by the apoB mRNA editing catalytic peptide (APOBEC) family of enzymes, which includes the activation-induced deaminase (AID) enzymes. Both the ADAR and APOBEC groups of deaminase enzymes have a homologous zinc-coordinating catalytic domain.
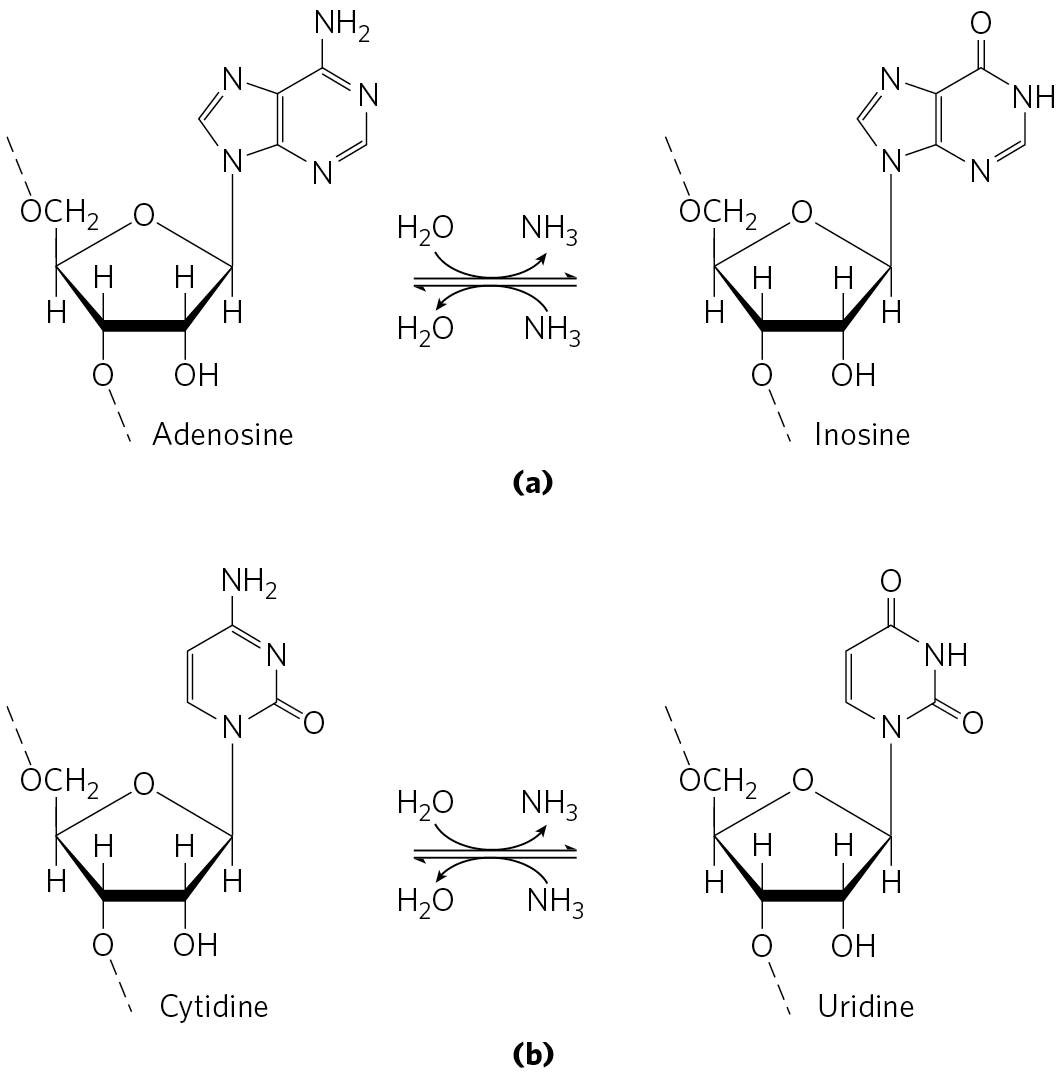
FIGURE 27-11 Deamination reactions that result in RNA editing. (a) Conversion of adenosine nucleotides to inosine nucleotides is catalyzed by ADAR enzymes. (b) Cytidine-to-uridine conversions are catalyzed by the APOBEC family of enzymes.
The ADAR-promoted A-to-I editing of RNA transcripts is particularly common in primates. Most of the editing occurs in Alu elements, a subset of short interspersed elements (SINEs), eukaryotic transposons that are particularly common in primate genomes. Human DNA contains more than a million 300 bp Alu elements, making up about 10% of the genome. These elements are concentrated near protein-coding genes, often in introns and untranslated regions at the and ends of transcripts. When it is first synthesized (before processing), the average human mRNA includes 10 to 20 Alu elements. Certain microRNAs are also targeted by ADARs. The microRNA (miRNA) alterations generally reduce expression and/or function.
The ADAR enzymes bind to and promote A-to-I editing only in duplex regions of RNA. The abundant Alu elements offer many opportunities for intramolecular base pairing within the transcripts, providing the duplex targets required by ADARs. Some of the editing affects the coding sequences of genes. Defects in ADAR function have been associated with a variety of human neurological conditions, including amyotrophic lateral sclerosis (ALS), epilepsy, and major depression.
There are six general classes of APOBEC cytidine deaminases: APOBEC1–APOBEC5 and AID. The AID proteins function in increasing antibody diversity during immunoglobulin gene maturation (see Figs. 25-42 and 25-43). APOBEC1 and some of the APOBEC3 proteins (seven APOBEC paralogs are encoded by the human genome) edit mRNAs. A well-studied example of RNA editing by APOBEC1-mediated deamination occurs in the gene for the apolipoprotein B component of low-density lipoprotein in vertebrates. One form of apolipoprotein B, apoB-100 , is synthesized in the liver; a second form, apoB-48 , is synthesized in the intestine. Both are encoded by an mRNA produced from the gene for apoB-100. An APOBEC cytidine deaminase found only in the intestine binds to the mRNA at the codon for amino acid residue 2,153 and converts the C to a U to create the termination codon UAA. The apoB-48 produced in the intestine from this modified mRNA is simply an abbreviated form (corresponding to the amino-terminal half) of apoB-100 (Fig. 27-12). This reaction permits tissue-specific synthesis of two different proteins from one gene.

FIGURE 27-12 RNA editing of the transcript of the gene for the apoB-100 component of LDL. Deamination, which occurs only in the intestine, converts a specific cytidine to uridine, changing a Gln codon to a stop codon and producing a truncated protein.
APOBEC2, 4, and 5 act on DNA rather than RNA, and their functions are poorly understood. However, their ability to cause genomic mutations can make them a liability to the cell. One or more APOBEC enzymes are often overexpressed in tumor cells, and their mutagenic ability can contribute to the formation of tumors. They also provide a mechanism for introducing multiple mutations into a targeted segment of a chromosome, leading to selective and more rapid evolution of that DNA region.
SUMMARY 27.1 The Genetic Code
- The particular amino acid sequence of a protein is constructed through the translation of information encoded in mRNA. This process is carried out by ribosomes. Amino acids are specified by mRNA codons consisting of nucleotide triplets. Translation requires adaptor molecules, the tRNAs, that recognize codons and insert amino acids into their appropriate sequential positions in the polypeptide.
- The base sequences of the codons were deduced from experiments using synthetic mRNAs of known composition and sequence. The codon AUG signals initiation of translation. The triplets UAA, UAG, and UGA are signals for termination. The genetic code is degenerate: it has multiple codons for almost every amino acid. The standard genetic code is universal in all species, with some minor deviations in mitochondria and a few single-celled organisms. The deviations occur in a pattern that reinforces the concept of a universal code.
- The third position in each codon is much less specific than the first and second positions and is said to wobble. This property allows certain tRNAs to recognize more than one codon.
- The genetic code is resistant to the effects of missense mutations. The code evolved so that many nucleotide changes in a DNA codon do not alter the encoded amino acid, or they result in a very conservative alteration.
- Translational frameshifting and RNA editing affect how the genetic code is read during translation.
- RNA editing by ADARs (adenosine deaminases) and APOBECs (cytidine deaminases) also alters the coding sequence of some mRNAs. Many APOBEC enzymes target DNA, where they function in facilitating antibody diversity and suppression of retroviruses and retrotransposons.
 The particular amino acid sequence of a protein is constructed through the translation of information encoded in mRNA. This process is carried out by ribosomes. Amino acids are specified by mRNA codons consisting of nucleotide triplets. Translation requires adaptor molecules, the tRNAs, that recognize codons and insert amino acids into their appropriate sequential positions in the polypeptide.
The particular amino acid sequence of a protein is constructed through the translation of information encoded in mRNA. This process is carried out by ribosomes. Amino acids are specified by mRNA codons consisting of nucleotide triplets. Translation requires adaptor molecules, the tRNAs, that recognize codons and insert amino acids into their appropriate sequential positions in the polypeptide.