The discovery of the structure of DNA by Watson and Crick in 1953 gave rise to entirely new disciplines and influenced the course of many established ones. In this section we focus on DNA structure, some of the events that led to its discovery, and more recent refinements in our understanding of DNA. We also introduce RNA structure.
As in the case of protein structure (Chapter 4), it is sometimes useful to describe nucleic acid structure in terms of hierarchical levels of complexity (primary, secondary, tertiary). The primary structure of a nucleic acid is its covalent structure and nucleotide sequence. Any regular, stable structure taken up by some or all of the nucleotides in a nucleic acid can be referred to as secondary structure. Most structures considered in the remainder of this chapter fall under the heading of secondary structure. The complex folding of large chromosomes within eukaryotic chromatin and bacterial nucleoids, or the elaborate folding of large tRNA or rRNA molecules, is generally considered tertiary structure. DNA tertiary structure is discussed in Chapter 24. RNA tertiary structure is considered briefly in this chapter and more thoroughly in Chapter 26.
DNA Is a Double Helix That Stores Genetic Information
DNA was first isolated and characterized by Friedrich Miescher in 1869. He called the phosphorus-containing substance “nuclein.” Not until the 1940s, with the work of Oswald T. Avery, Colin MacLeod, and Maclyn McCarty, was there any compelling evidence that DNA was the genetic material. Avery and his colleagues found that an extract of a virulent strain of the bacterium Streptococcus pneumoniae (causing disease in mice) could be used to transform a nonvirulent strain of the same bacterium into a virulent strain. They were able to demonstrate through various chemical tests that it was DNA from the virulent strain (not protein, polysaccharide, or RNA, for example) that carried the genetic information for virulence. Then in 1952, experiments by Alfred D. Hershey and Martha Chase — in which they studied the infection of bacterial cells by a virus (bacteriophage) with radioactively labeled DNA or protein — removed any remaining doubt that DNA, not protein, carried the genetic information.
Another important clue to the structure of DNA came from the work of Erwin Chargaff and his colleagues in the late 1940s. Examining dozens of species, they found that the four nucleotide bases of DNA occur in different ratios in the DNAs of different organisms. However, the base composition remains constant in different tissues of the same species, and does not vary with age, environment, nutritional state, or generation. Furthermore, regardless of the species, the number of adenosine residues is equal to the number of thymidine residues (that is, A = T), and the number of guanosine residues is equal to the number of cytidine residues (G = C). From these relationships it follows that the sum of the purine residues equals the sum of the pyrimidine residues; that is, A + G = T + C. These quantitative relationships, sometimes called “Chargaff’s rules,” were a key to establishing the three-dimensional structure of DNA.
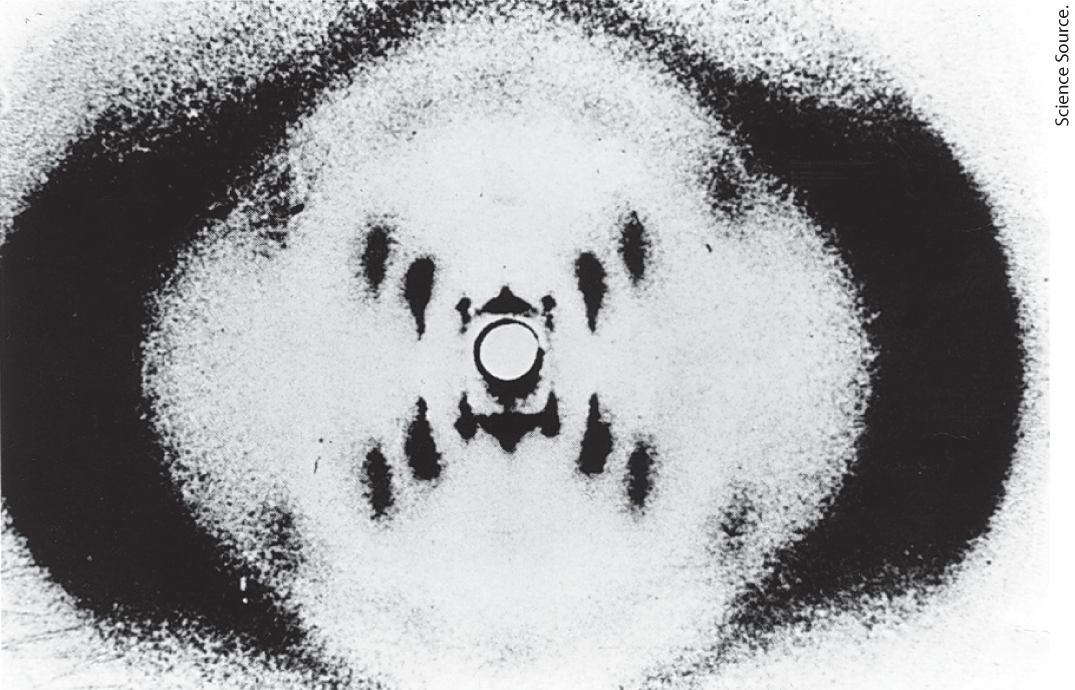
To shed more light on the structure of DNA, in the early 1950s Rosalind Franklin and Maurice Wilkins used the powerful method of x-ray diffraction (see Fig. 4-30) to analyze DNA fibers. Although lacking the molecular definition of diffraction from crystals, the x-ray diffraction pattern generated from the fibers was informative (Fig. 8-12). The pattern revealed that DNA molecules are helical, with two periodicities along their long axis: a primary one of 3.4 Å and a secondary one of 34 Å. The problem then was to formulate a three-dimensional model of the DNA molecule that could account not only for the x-ray diffraction data but also for the specific A = T and G = C base equivalences discovered by Chargaff and for the other chemical properties of DNA.
FIGURE 8-12 X-ray diffraction pattern of DNA fibers. The spots forming a cross in the center denote a helical structure. The heavy bands at the left and the right arise from the recurring bases.
Rosalind Franklin, 1920–1958
Maurice Wilkins, 1916–2004
James Watson and Francis Crick relied on this accumulated information about DNA to set about deducing its structure. In 1953 they postulated a three-dimensional model of DNA structure that accounted for all the available data. It consists of two helical DNA chains wound around the same axis to form a right-handed double helix. (See Box 4-1 for an explanation of the right- or left-handed sense of a helical structure.) The hydrophilic backbones of alternating deoxyribose and phosphate groups are on the outside of the double helix, facing the surrounding water. The furanose ring of each deoxyribose is in the endo conformation. The purine and pyrimidine bases of both strands are stacked inside the double helix, with their hydrophobic and nearly planar ring structures very close together and perpendicular to the long axis. The offset pairing of the two strands creates a major groove and a minor groove on the surface of the duplex (Fig. 8-13). Each nucleotide base of one strand is paired in the same plane with a base of the other strand. Watson and Crick found that the hydrogen-bonded base pairs illustrated in Figure 8-11, G with C and A with T, are those that fit best within the structure, providing a rationale for Chargaff’s rule that in any DNA, G = C and A = T. It is important to note that three hydrogen bonds can form between G and C, symbolized G≡C, but only two can form between A and T, symbolized A═T. Pairings of bases other than G with C and A with T tend (to varying degrees) to destabilize the double-helical structure.
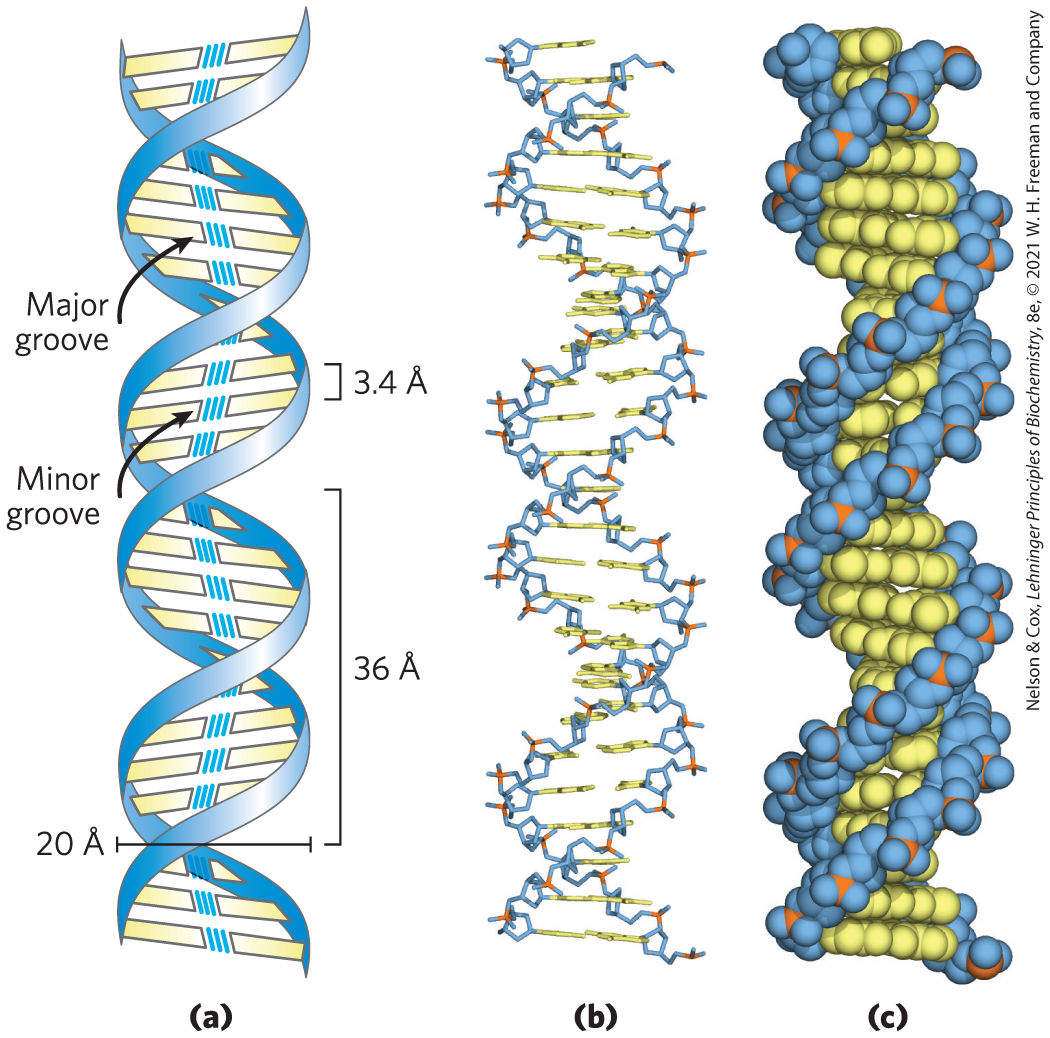
FIGURE 8-13 Watson-Crick model for the structure of DNA. The original model proposed by Watson and Crick had 10 bp, or 34 Å (3.4 nm), per turn of the helix; subsequent measurements revealed 10.5 bp, or 36 Å (3.6 nm), per turn. (a) Schematic representation, showing dimensions of the helix. (b) Stick representation showing the backbone and stacking of the bases. (c) Space-filling model.
When Watson and Crick constructed their model, they had to decide at the outset whether the strands of DNA should be parallel or antiparallel — whether their ,-phosphodiester bonds should run in the same or opposite directions. An antiparallel orientation produced the most convincing model, and later work with DNA polymerases (Chapter 25) provided experimental evidence that the strands are indeed antiparallel, a finding ultimately confirmed by x-ray analysis.
To account for the periodicities observed in the x-ray diffraction patterns of DNA fibers, Watson and Crick manipulated molecular models to arrive at a structure in which the vertically stacked bases inside the double helix would be 3.4 Å apart; the secondary repeat distance of about 34 Å was accounted for by the presence of 10 base pairs (bp) in each complete turn of the double helix. The structure in aqueous solution differs slightly from that in fibers, having 10.5 bp per helical turn (Fig. 8-13).
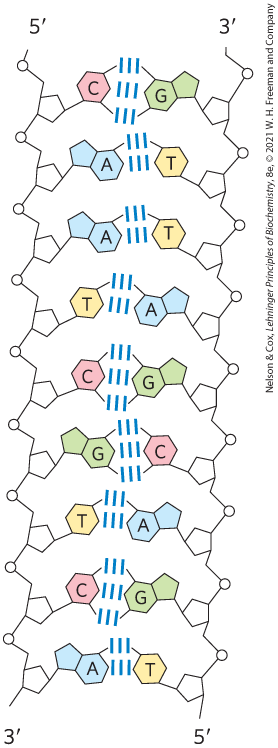
As Figure 8-14 shows, the two antiparallel polynucleotide chains of double-helical DNA are not identical in either base sequence or composition. Instead they are complementary to each other. Wherever adenine occurs in one chain, thymine is found in the other; similarly, wherever guanine occurs in one chain, cytosine is found in the other.
FIGURE 8-14 Complementarity of strands in the DNA double helix. The complementary antiparallel strands of DNA follow the pairing rules proposed by Watson and Crick. The base-paired antiparallel strands differ in base composition: the left strand has the composition ; the right strand has . They also differ in sequence when each chain is read in the direction. Note the base equivalences: A = T and G = C in the duplex.
The DNA double helix, or duplex, is held together by hydrogen bonding between complementary base pairs (Fig. 8-11) and by base-stacking interactions. The complementarity between the DNA strands is attributable to the hydrogen bonding between base pairs; however, the hydrogen bonds do not contribute significantly to the stability of the structure. The double helix is primarily stabilized by metal cations, which shield the negative charges of backbone phosphates, and by base-stacking interactions between successive base pairs. Base-stacking interactions between successive or pairs are stronger than those between successive and pairs or adjacent pairs including all four bases. Because of this, DNA duplexes with higher content are more stable.
The important features of the double-helical model of DNA structure are now supported by much chemical and biological evidence. Moreover, the model immediately suggested a mechanism for the transmission of genetic information. The essential feature of the model was the complementarity of the two DNA strands. As Watson and Crick were able to see, well before confirmatory data became available, this structure could logically be replicated by (1) separating the two strands and (2) synthesizing a complementary strand for each. Because nucleotides in each new strand are joined in a sequence specified by the base-pairing rules stated above, each preexisting strand functions as a template to guide the synthesis of one complementary strand (Fig. 8-15). These expectations were experimentally confirmed, inaugurating a revolution in our understanding of biological inheritance.
FIGURE 8-15 Replication of DNA as suggested by Watson and Crick. The preexisting or “parent” strands become separated, and each is the template for biosynthesis of a complementary “daughter” strand (in pink).
DNA Can Occur in Different Three-Dimensional Forms
DNA is a remarkably flexible molecule. Considerable rotation is possible around several types of bonds in the sugar–phosphate (phosphodeoxyribose) backbone, and thermal fluctuation can produce bending, stretching, and unpairing (melting) of the strands. Many significant deviations from the Watson-Crick DNA structure are found in cellular DNA, some or all of which may be important in DNA metabolism. These structural variations generally do not affect the key properties of DNA defined by Watson and Crick: strand complementarity, antiparallel strands, and the requirement for and base pairs.
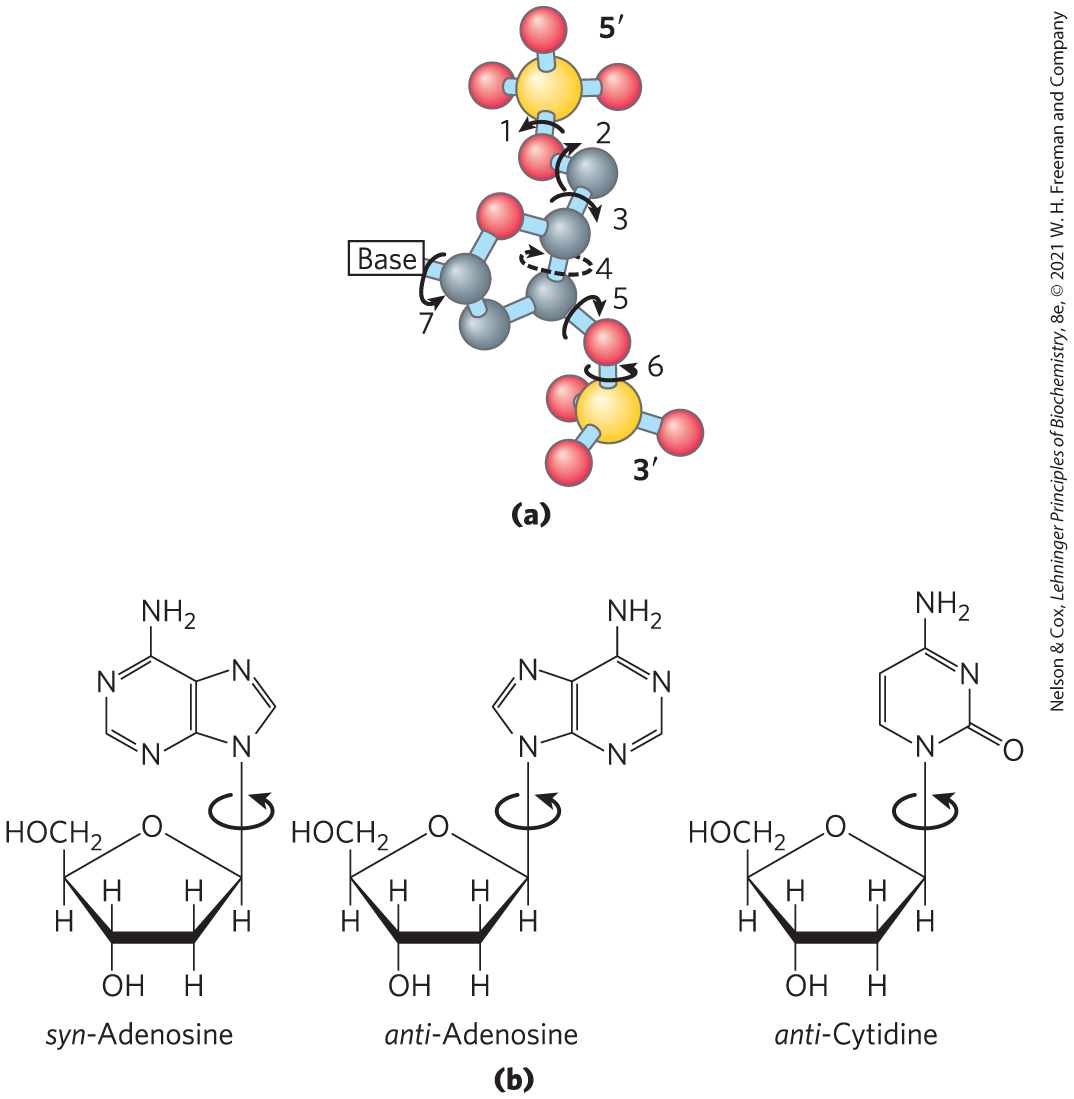
Structural variation in DNA reflects three things: the different possible conformations of the deoxyribose, rotation about the contiguous bonds that make up the phosphodeoxyribose backbone (Fig. 8-16a), and free rotation about the C-–N-glycosyl bond (Fig. 8-16b). Because of steric constraints, purines in purine nucleotides are restricted to two stable conformations with respect to deoxyribose, called syn and anti (Fig. 8-16b). Pyrimidines are generally restricted to the anti conformation because of steric interference between the sugar and the carbonyl oxygen at C-2 of the pyrimidine.
FIGURE 8-16 Structural variation in DNA. (a) The conformation of a nucleotide in DNA is affected by rotation about seven different bonds. Six of the bonds rotate freely. The limited rotation about bond 4 gives rise to ring pucker. This conformation is endo or exo, depending on whether the atom is displaced to the same side of the plane as or to the opposite side (see Fig. 8-3b). (b) For purine bases in nucleotides, only two conformations with respect to the attached ribose units are sterically permitted: anti or syn. Pyrimidines occur in the anti conformation.
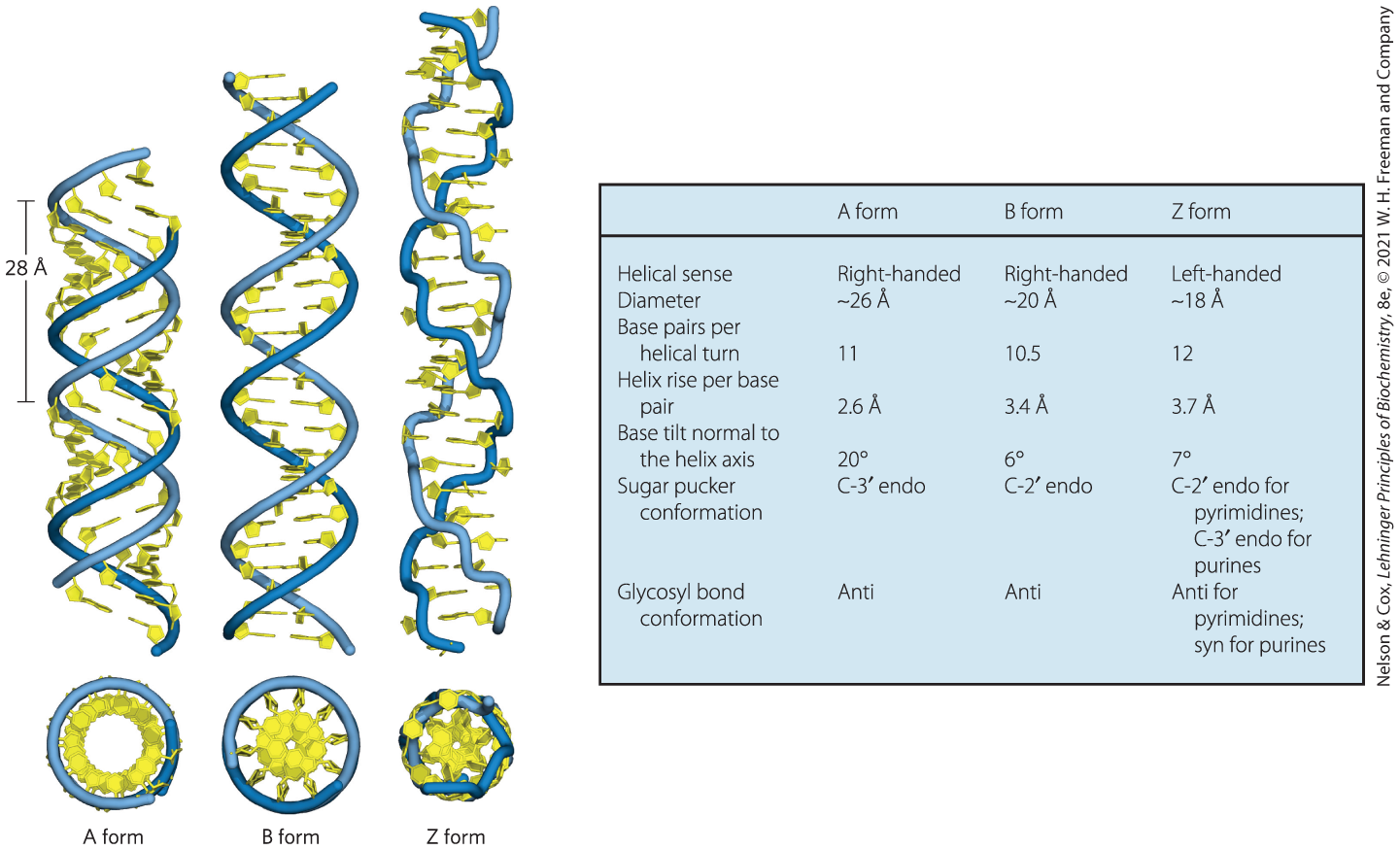
The Watson-Crick structure is also referred to as B-form DNA, or B-DNA. The B form is the most stable structure for a random-sequence DNA molecule under physiological conditions and is therefore the standard point of reference in any study of the properties of DNA. Two structural variants that have been well characterized in crystal structures are the A and Z forms. These three DNA conformations are shown in Figure 8-17, with a summary of their properties. The A form is favored in many solutions that are relatively devoid of water. The DNA is still arranged in a right-handed double helix, but the helix is wider and the number of base pairs per helical turn is 11, rather than 10.5 as in B-DNA. The plane of the base pairs in A-DNA is tilted about relative to B-DNA base pairs, thus the base pairs in A-DNA are not perfectly perpendicular to the helix axis. These structural changes deepen the major groove while making the minor groove shallower. The reagents used to promote crystallization of DNA tend to dehydrate it, and thus most short DNA molecules tend to crystallize in the A form.
FIGURE 8-17 Comparison of A, B, and Z forms of DNA. Each structure shown here has 36 bp. The riboses and bases are shown in yellow. The phosphodiester backbone is represented as a blue rope. Blue is the color used to represent DNA strands in later chapters. The table summarizes some properties of the three forms of DNA.
Z-form DNA is a more radical departure from the B structure; the most obvious distinction is the left-handed helical rotation. There are 12 bp per helical turn, and the structure appears more slender and elongated. The DNA backbone takes on a zigzag appearance. Certain nucleotide sequences fold into left-handed Z helices much more readily than others. Prominent examples are sequences in which pyrimidines alternate with purines, especially alternating C and G (that is, in the helix, alternating and pairs) or 5-methyl-C and G residues. To form the left-handed helix in Z-DNA, the purine residues flip to the syn conformation, alternating with pyrimidines in the anti conformation. The major groove is barely apparent in Z-DNA, and the minor groove is narrow and deep.
Whether A-DNA occurs in cells is uncertain, but there is evidence for some short stretches (tracts) of Z-DNA in both bacteria and eukaryotes. These Z-DNA tracts may play a role (as yet undefined) in regulating the expression of some genes or in genetic recombination.
Certain DNA Sequences Adopt Unusual Structures
Other sequence-dependent structural variations found in larger chromosomes may affect the function and metabolism of the DNA segments in their immediate vicinity. For example, bends occur in the DNA helix wherever four or more adenosine residues appear sequentially in one strand. Six adenosines in a row produce a bend of about . The bending observed with this and other sequences may be important in the binding of some proteins to DNA.
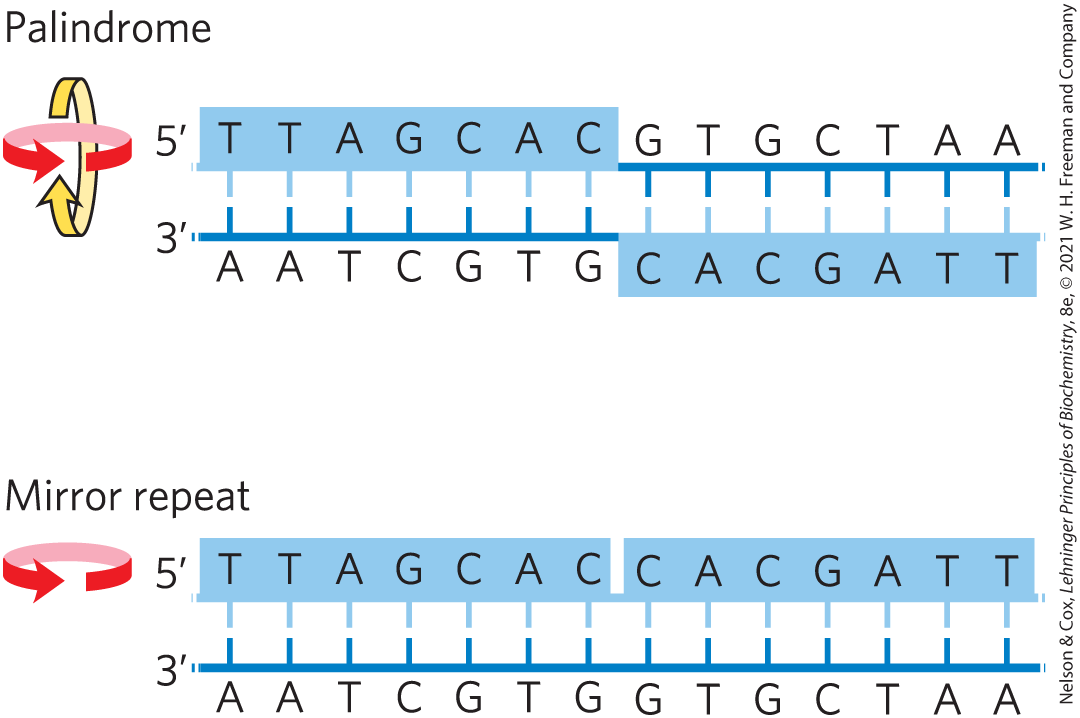
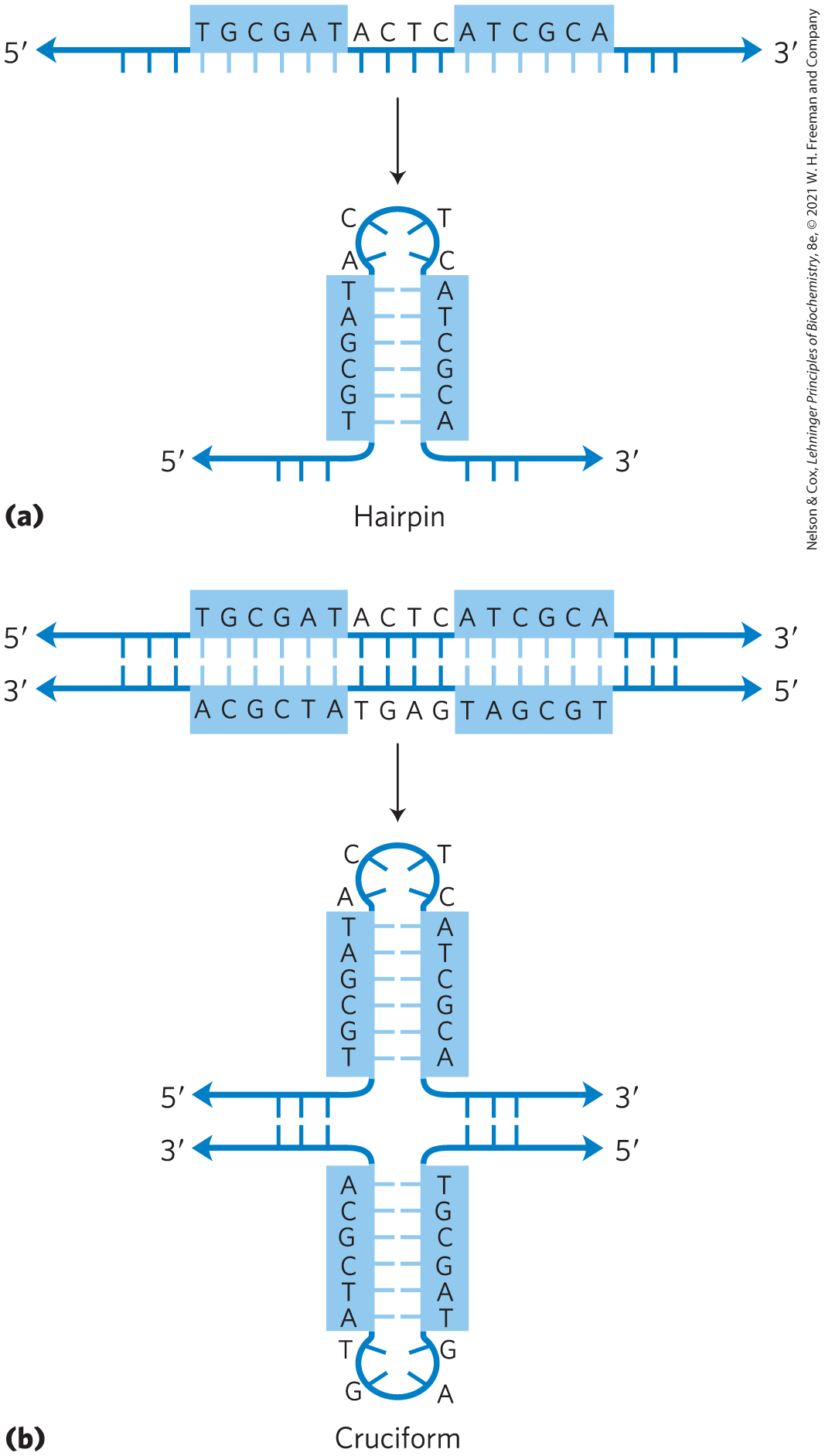
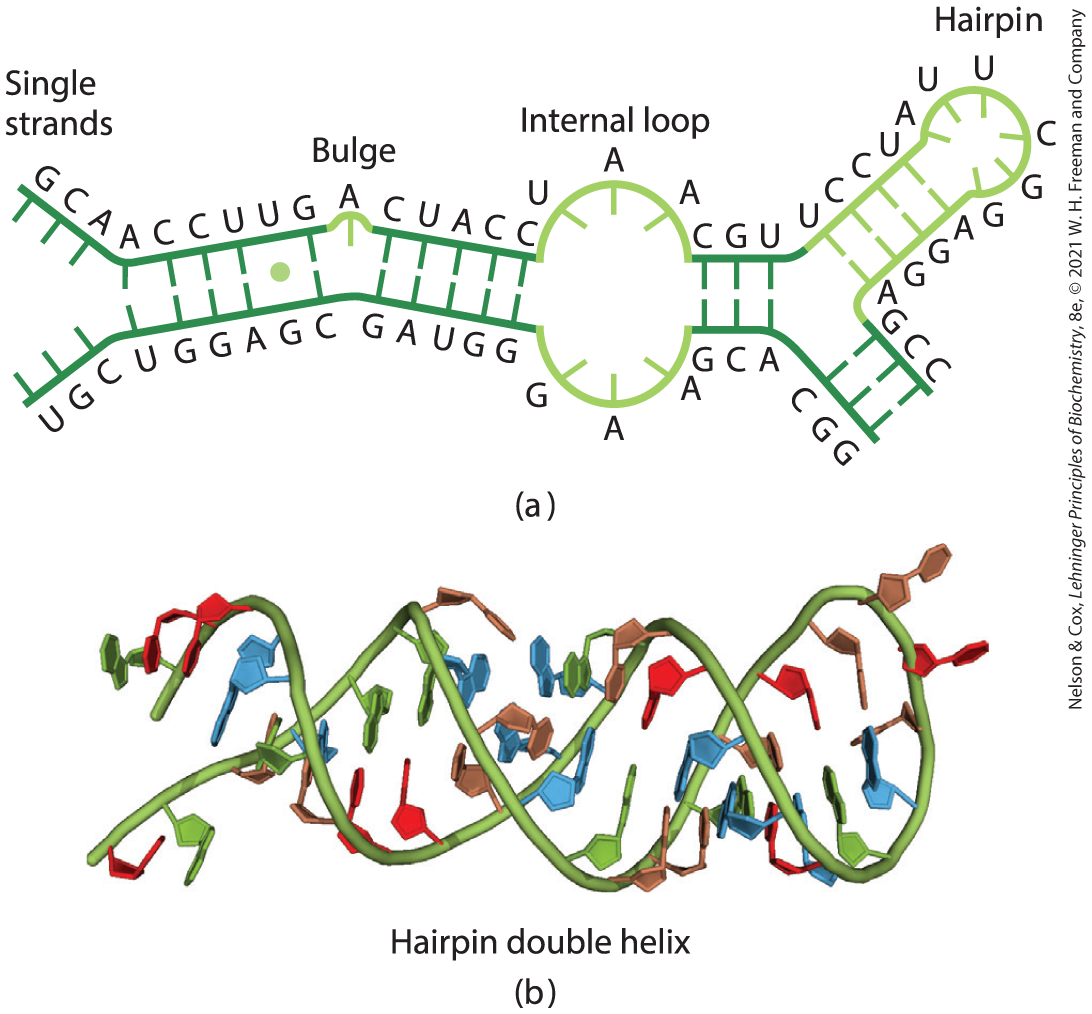
A common type of DNA sequence is a palindrome. A palindrome is a word, phrase, or sentence that is spelled identically when read either forward or backward; two examples are ROTATOR and NURSES RUN. In DNA, the term is applied to regions of DNA with inverted repeats, such that an inverted, self-complementary sequence in one strand is repeated in the opposite orientation in the paired strand, as in Figure 8-18. The self-complementarity within each strand confers the potential to form hairpin or cruciform (cross-shaped) structures (Fig. 8-19). When the inverted repeat occurs within each individual strand of the DNA, the sequence is called a mirror repeat. Mirror repeats do not have complementary sequences within the same strand and thus cannot form hairpin or cruciform structures. Sequences of these types are found in almost every large DNA molecule and can encompass a few base pairs or thousands. The extent to which palindromes occur as cruciforms in cells is not known, although some cruciform structures have been demonstrated in vivo in Escherichia coli. Self-complementary sequences cause isolated single strands of DNA (or RNA) in solution to fold into complex structures containing multiple hairpins.
FIGURE 8-18 Palindromes and mirror repeats. Palindromes are sequences of double-stranded nucleic acids with twofold symmetry. To superimpose one repeat (shaded sequence) on the other, it must be rotated about the horizontal axis and then about the vertical axis, as shown by the colored arrows. A mirror repeat, on the other hand, has a symmetric sequence within each strand. Superimposing one repeat on the other requires only a single rotation about the vertical axis.
FIGURE 8-19 Hairpins and cruciforms. Palindromic DNA (or RNA) sequences can form alternative structures with intrastrand base pairing. (a) Hairpin structures involve a single DNA or RNA strand. (b) Cruciform structures involve both strands of a duplex DNA. Blue shading highlights asymmetric sequences that can pair with the complementary sequence either in the same strand or in the complementary strand.
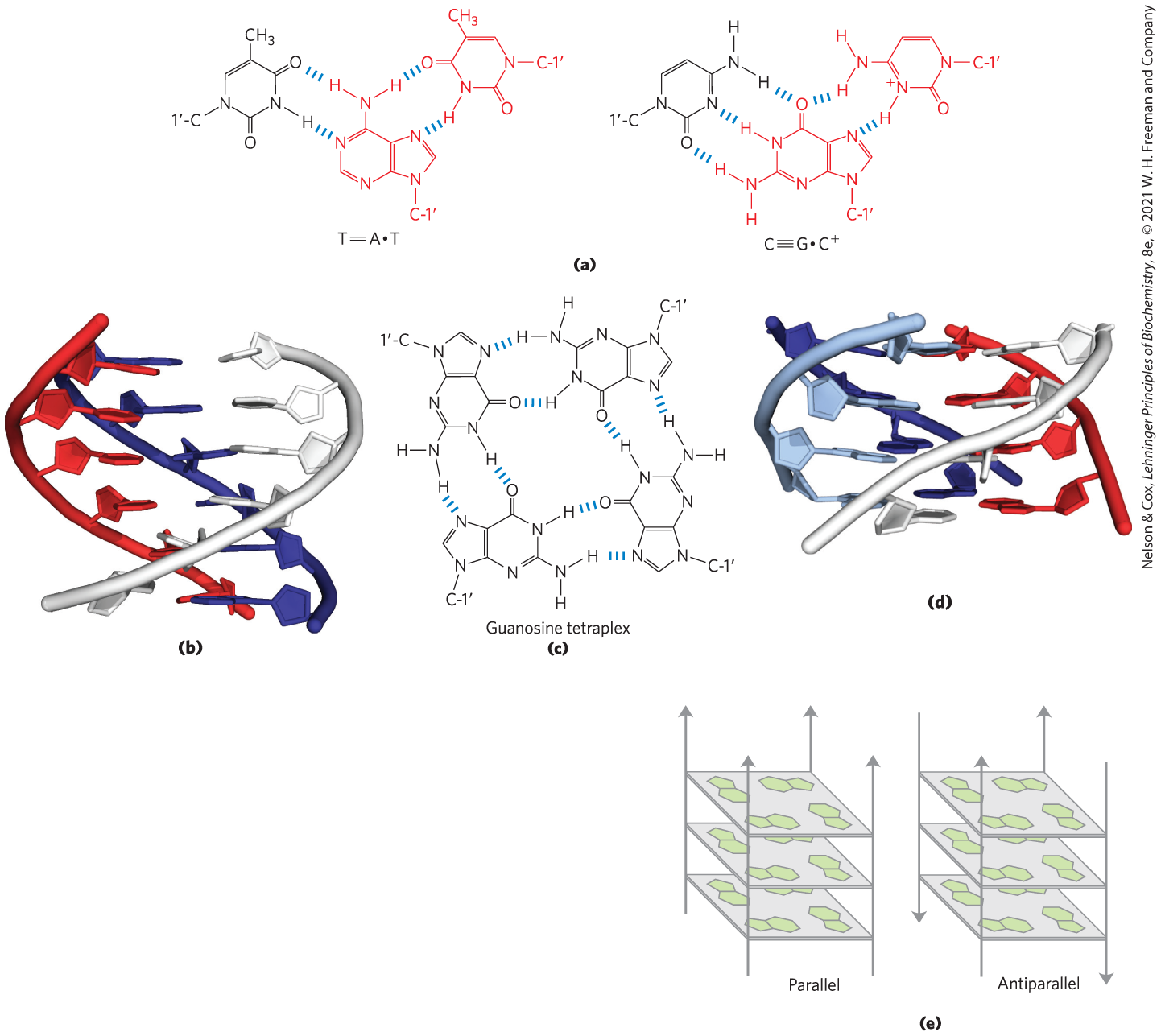
Several unusual DNA structures are formed from three or even four DNA strands. Nucleotides participating in a Watson-Crick base pair (Fig. 8-11) can form additional hydrogen bonds with a third strand, particularly with functional groups arrayed in the major groove. For example, the guanosine residue of a nucleotide pair can pair with a cytidine residue (if protonated) on a third strand (Fig. 8-20a); the adenosine of an pair can pair with a thymidine residue. The N-7, , and of purines, the atoms that participate in the hydrogen bonding with a third DNA strand, are often referred to as Hoogsteen positions, and the non-Watson-Crick pairing is called Hoogsteen pairing, after Karst Hoogsteen, who in 1963 first recognized the potential for these unusual pairings. Hoogsteen pairing allows the formation of triplex DNAs. The triplexes shown in Figure 8-20 (a, b) are most stable at low pH because the triplet requires a protonated cytosine. In the triplex, the of this cytosine is >7.5, altered from its normal value of 4.2. The triplexes also form most readily within long sequences containing only pyrimidines or only purines in a given strand. Some triplex DNAs contain two pyrimidine strands and one purine strand; others contain two purine strands and one pyrimidine strand.
FIGURE 8-20 DNA structures containing three or four DNA strands. (a) Base-pairing patterns in one well-characterized form of triplex DNA. The Hoogsteen pair in each case is shown in red. (b) Triple-helical DNA containing two pyrimidine strands (red and white; sequence TTCCTT) and one purine strand (blue; sequence AAGGAA). The blue and white strands are antiparallel and paired by normal Watson-Crick base-pairing patterns. The third (all-pyrimidine) strand (red) is parallel to the purine strand and paired through non-Watson-Crick hydrogen bonds. The triplex is viewed from the side, with six triplets shown. (c) Base-pairing pattern in the guanosine tetraplex structure. (d) Four successive tetraplets from a G tetraplex structure. (e) Possible variants in the orientation of strands in a G tetraplex. [Data from (b) PDB ID 1BCE, J. L. Asensio et al., Nucleic Acids Res. 26:3677, 1998; (d) PDB ID 244D, G. Laughlan et al., Science 265:520, 1994.]
Four DNA strands can also pair to form a tetraplex (quadruplex), but this occurs readily only for DNA sequences with a very high proportion of guanosine residues (Fig. 8-20c, d). The guanosine tetraplex, or G tetraplex, is quite stable over a broad range of conditions. The orientation of strands in the tetraplex can vary as shown in Figure 8-20e.
In the DNA of living cells, sites recognized by many sequence-specific DNA-binding proteins (Chapter 28) are arranged as palindromes, and polypyrimidine or polypurine sequences that can form triple helices are found within regions involved in the regulation of expression of some eukaryotic genes.
Messenger RNAs Code for Polypeptide Chains
We now turn our attention to the expression of the genetic information that DNA contains. Given that the DNA of eukaryotes is largely confined to the nucleus, whereas protein synthesis occurs on ribosomes in the cytoplasm, some molecule other than DNA must carry the genetic message from the nucleus to the cytoplasm. As early as the 1950s, RNA was considered the logical candidate: RNA is found in both the nucleus and the cytoplasm, and an increase in protein synthesis is accompanied by an increase in the amount of cytoplasmic RNA and an increase in its rate of turnover. These and other observations led several researchers to suggest that RNA carries genetic information from DNA to the protein-synthesizing machinery of the ribosome. In 1961, François Jacob and Jacques Monod presented a unified (and essentially correct) picture of many aspects of this process. They proposed the name “messenger RNA” (mRNA) for that portion of the total cellular RNA carrying the genetic information from DNA to the ribosomes. The mRNAs are formed on a DNA template by the process of transcription. Once they reach the ribosomes, the messengers provide the templates that specify amino acid sequences in polypeptide chains. Although mRNAs from different genes can vary greatly in length, the mRNAs from a particular gene generally have a defined size.
In bacteria and archaea, a single mRNA molecule may code for one or several polypeptide chains. If it carries the code for only one polypeptide, the mRNA is monocistronic; if it codes for two or more different polypeptides, the mRNA is polycistronic. In eukaryotes, most mRNAs are monocistronic. (For the purposes of this discussion, “cistron” refers to a gene. The term itself has historical roots in the science of genetics, and its formal genetic definition is beyond the scope of this text.) The minimum length of an mRNA is set in part by the length of the polypeptide chain for which it codes. For example, a polypeptide chain of 100 amino acid residues requires an RNA coding sequence of at least 300 nucleotides, because each amino acid is coded by a nucleotide triplet (this and other details of protein synthesis are discussed in Chapter 27). However, mRNAs transcribed from DNA are always somewhat longer than the length needed simply to code for a polypeptide sequence (or sequences). The additional, noncoding RNA includes sequences required to begin and end translation by the ribosome, as well as regulatory sequences. Figure 8-21 summarizes the general structure of bacterial mRNAs.
FIGURE 8-21 Bacterial mRNA. Schematic diagrams show (a) monocistronic and (b) polycistronic mRNAs of bacteria. Red segments represent RNA coding for a gene product; gray segments represent noncoding RNA. In the polycistronic transcript, noncoding RNA separates the three genes.
Many RNAs Have More Complex Three-Dimensional Structures
Messenger RNA is only one of several classes of cellular RNA. Transfer RNAs are adapter molecules that act in protein synthesis; covalently linked to an amino acid at one end, each tRNA pairs with the mRNA in such a way that amino acids are joined to a growing polypeptide in the correct sequence. Ribosomal RNAs are components of ribosomes. There is also a wide variety of noncoding RNAs, including some (called ribozymes) that have enzymatic activity. All the RNAs are considered in detail in Chapter 26. The diverse and often complex functions of these RNAs reflect a diversity of structure much richer than that observed in DNA molecules.
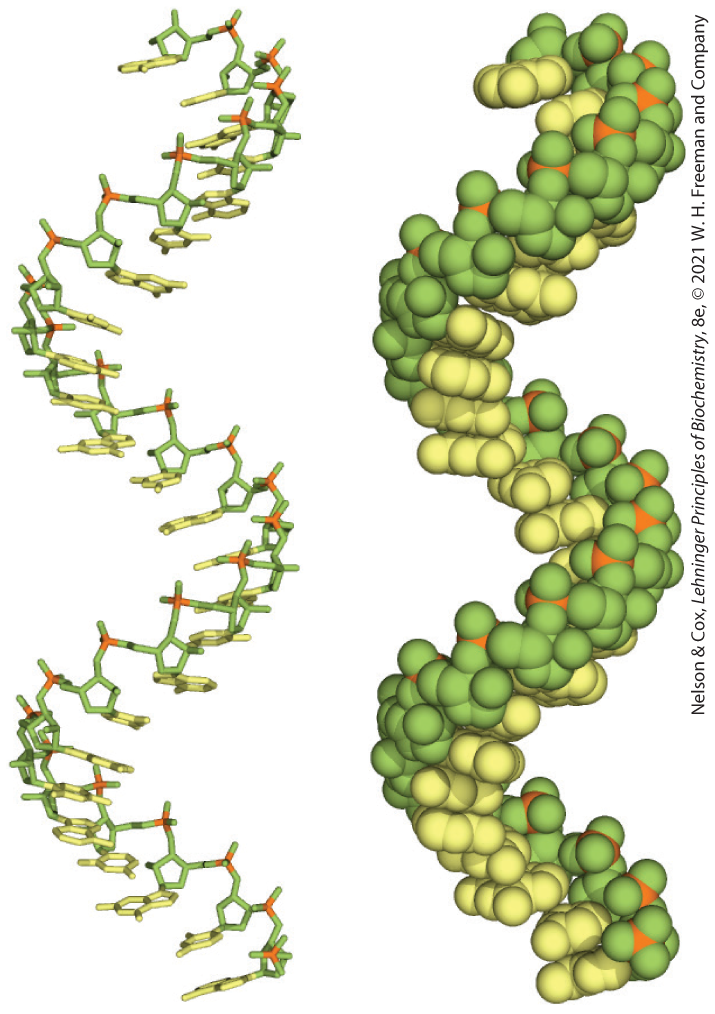
The product of transcription of DNA is always single-stranded RNA. The single strand tends to assume a right-handed helical conformation dominated by base-stacking interactions (Fig. 8-22), which are stronger between two purines than between a purine and a pyrimidine or between two pyrimidines. The purine-purine interaction is so strong that a pyrimidine separating two purines is often displaced from the stacking pattern so that the purines can interact. Any self-complementary sequences in the molecule trigger folding into structures with more complexity. RNA can base-pair with complementary regions of either RNA or DNA. Base pairing matches the pattern for DNA: G pairs with C and A pairs with U (or with the occasional T residue in some RNAs). One difference is that base pairing between G and U residues is allowed in RNA (see Fig. 8-24) when complementary sequences in two single strands of RNA (or within a single strand of RNA that folds back on itself to align the residues) pair with each other. The paired strands in RNA or RNA-DNA duplexes are antiparallel, as in DNA.
FIGURE 8-22 Typical right-handed stacking pattern of single-stranded RNA. The bases are shown in yellow, the phosphorus atoms in orange, and the riboses and phosphate oxygens in green. Green is used to represent RNA strands in succeeding chapters, just as blue is used for DNA.
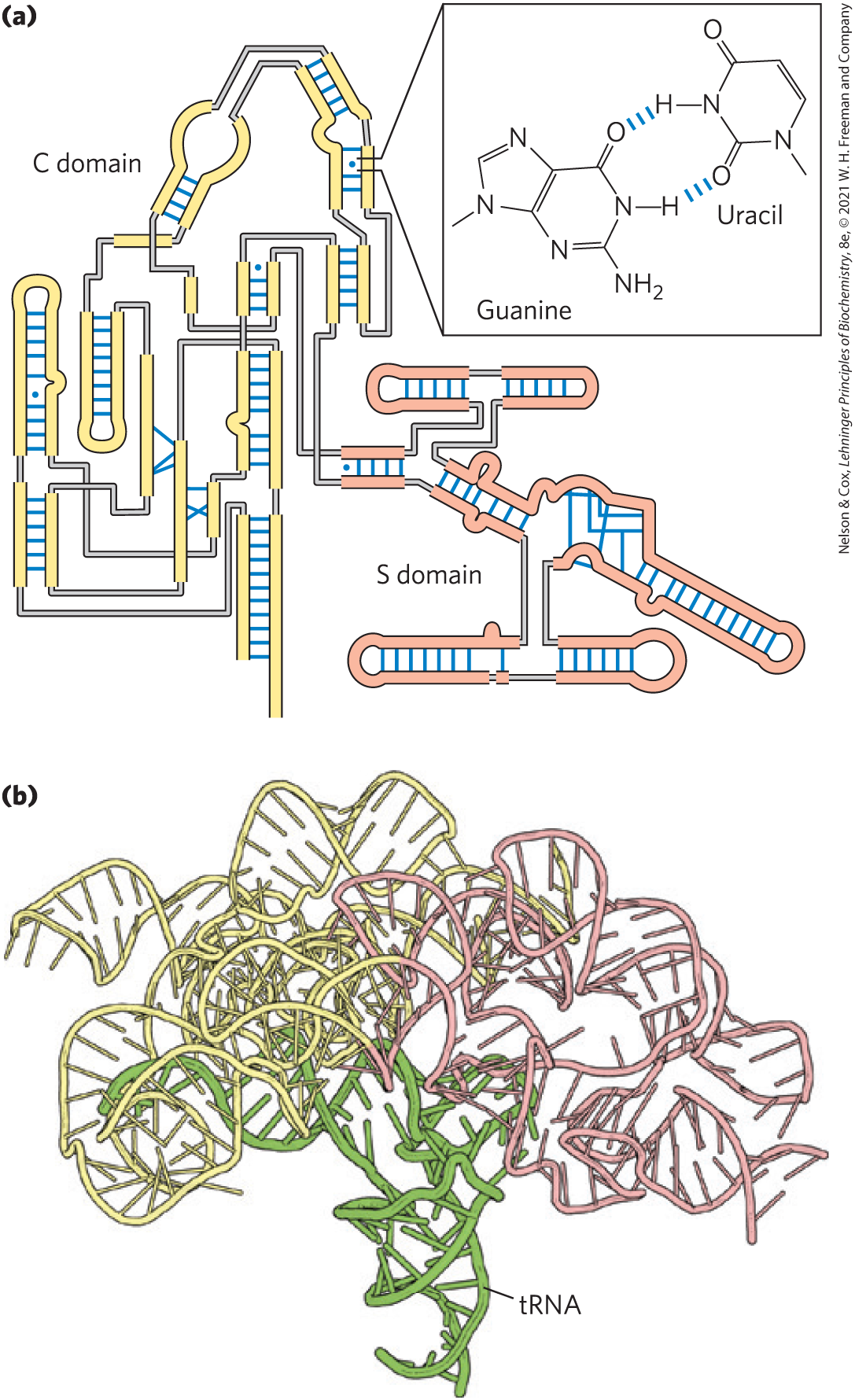
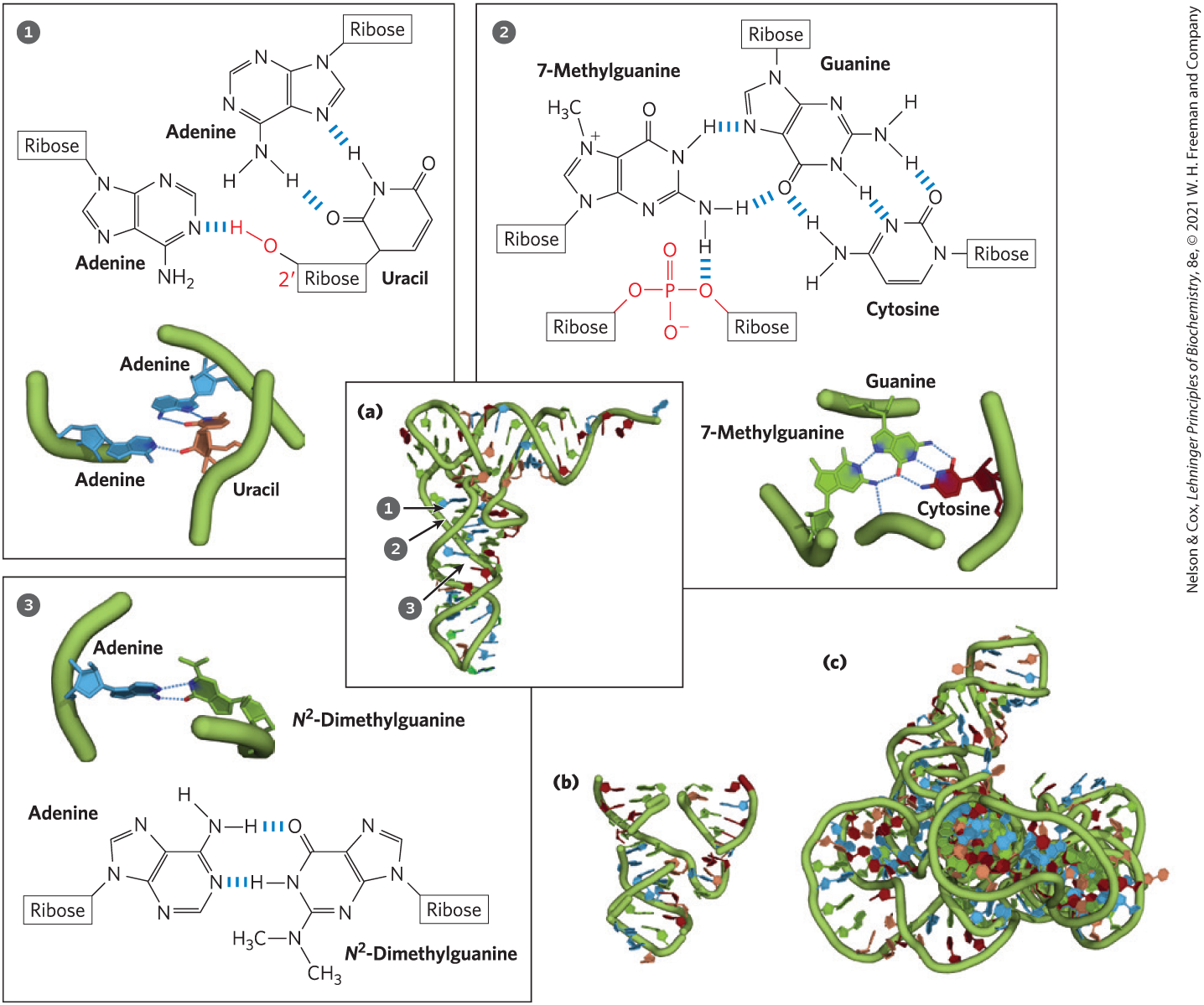
When two strands of RNA with perfectly complementary sequences are paired, the predominant double-stranded structure is an A-form right-handed double helix. However, strands of RNA that are perfectly paired over long regions of sequence are uncommon. The three-dimensional structures of many RNAs, like those of proteins, are complex and unique. Weak interactions, especially base-stacking interactions, help stabilize RNA structures, just as they do in DNA. Z-form helices have been made in the laboratory (under very high-salt or high-temperature conditions). The B form of RNA has not been observed. Breaks in the regular A-form helix caused by mismatched or unmatched bases in one or both strands are common and result in bulges or internal loops (Fig. 8-23). Hairpin loops form between nearby self-complementary (palindromic) sequences. Extensive base-paired helical segments are formed in many RNAs (Fig. 8-24), and the resulting hairpins are the most common type of secondary structure in RNA. Specific short base sequences (such as UUCG) are often found at the ends of RNA hairpins and are known to form particularly tight and stable loops. Such sequences may act as starting points for the folding of an RNA molecule into its precise three-dimensional structure. Other contributions are made by hydrogen bonds that are not part of standard Watson-Crick base pairs. For example, the -hydroxyl group of ribose can hydrogen-bond with other groups. Some of these properties are evident in the tertiary structure of the phenylalanine transfer RNA of yeast — the tRNA responsible for inserting Phe residues into polypeptides — and in two RNA enzymes, or ribozymes, whose functions, like those of protein enzymes, depend on their three-dimensional structures (Fig. 8-25).
FIGURE 8-23 Secondary structure of RNAs. (a) Bulge, internal loop, and hairpin loop. (b) The paired regions generally have an A-form right-handed helix, as shown for a hairpin. The single UG base pair is identified with a green dot. [(b) Data from PDB ID 1GID, J. H. Cate et al., Science 273:1678, 1996.]
FIGURE 8-24 Base-paired helical structures in an RNA. Shown here are (a) the secondary structure and (b) the three-dimensional structure of the P RNA component of the RNase P of Thermotoga maritima. RNase P, which also contains a protein component (not shown), functions in the processing of transfer RNAs. A complexed tRNA is also shown in (b). Separate C (catalytic) and S (specificity) domains are denoted with yellow and light red backbones in both images. The blue dots in (a) indicate non-Watson-Crick base pairs (boxed inset). Note that base pairs are allowed only when presynthesized strands of RNA fold up or anneal with each other. [(a) Information from N. J. Reiter et al., Nature 468:784, 2010, Fig. 2a. (b) Data from PDB ID 3Q1R, N. J. Reiter et al., Nature 468:784, 2010.]
FIGURE 8-25 Three-dimensional structure in RNA. (a) Three-dimensional structure of phenylalanine tRNA of yeast. Some unusual base-pairing patterns found in this tRNA are shown in the numbered insets. Note in a hydrogen bond with a ribose -hydroxyl group and in a hydrogen bond with the oxygen of a ribose phosphodiester (both shown in red). (b) A hammerhead ribozyme (so named because the secondary structure at the active site looks like the head of a hammer), derived from certain plant viruses. Ribozymes, or RNA enzymes, catalyze a variety of reactions, primarily in RNA metabolism and protein synthesis. The complex three-dimensional structures of these RNAs reflect the complexity inherent in catalysis, as described for protein enzymes in Chapter 6. (c) A segment of mRNA known as an intron, from the ciliated protozoan Tetrahymena thermophila. This intron (a ribozyme) catalyzes its own excision from between exons in an mRNA strand (discussed in Chapter 26). [Data from (a) PDB ID 1TRA, E. Westhof and M. Sundaralingam, Biochemistry 25:4868, 1986; (b) PDB ID 1MME, W. G. Scott et al., Cell 81:991, 1995; (c) PDB ID 1GRZ, B. L. Golden et al., Science 282:259, 1998.]
The analysis of RNA structure and the relationship between its structure and its function remains a robust field of inquiry that has many of the same complexities as the analysis of protein structure. The importance of understanding RNA structure grows as we become increasingly aware of the large number of functional roles for RNA molecules.
SUMMARY 8.2 Nucleic Acid Structure
Many lines of evidence show that DNA bears genetic information. Some of the earliest evidence came from the Avery-MacLeod-McCarty experiment, which showed that DNA isolated from one bacterial strain can enter and transform the cells of another strain, endowing the second strain with some of the inheritable characteristics of the donor. The Hershey-Chase experiment showed that the DNA of a bacterial virus, but not its protein coat, carries the genetic message for replication of the virus in a host cell.
Putting together the available data, Watson and Crick postulated that native DNA consists of two antiparallel chains in a right-handed double-helical arrangement. Complementary base pairs, and , are formed by hydrogen bonding between chains in the helix. The base pairs are stacked perpendicular to the long axis of the double helix, 3.4 Å apart, with 10.5 bp per turn.
DNA can exist in several structural forms. Two variations of the Watson-Crick form, or B-DNA, are A- and Z-DNA.
Some sequence-dependent structural variations cause bends in the DNA molecule. DNA strands with appropriate sequences can form hairpin or cruciform structures or triplex or tetraplex DNA.
Messenger RNA transfers genetic information from DNA to ribosomes for protein synthesis.
Transfer RNA and ribosomal RNA are also involved in protein synthesis. RNA can be structurally complex; single RNA strands can fold into hairpins, double-stranded regions, or complex loops. Additional noncoding RNAs have a variety of special functions.



 Because nucleotides in each new strand are joined in a sequence specified by the base-pairing rules stated above, each preexisting strand functions as a template to guide the synthesis of one complementary strand (
Because nucleotides in each new strand are joined in a sequence specified by the base-pairing rules stated above, each preexisting strand functions as a template to guide the synthesis of one complementary strand (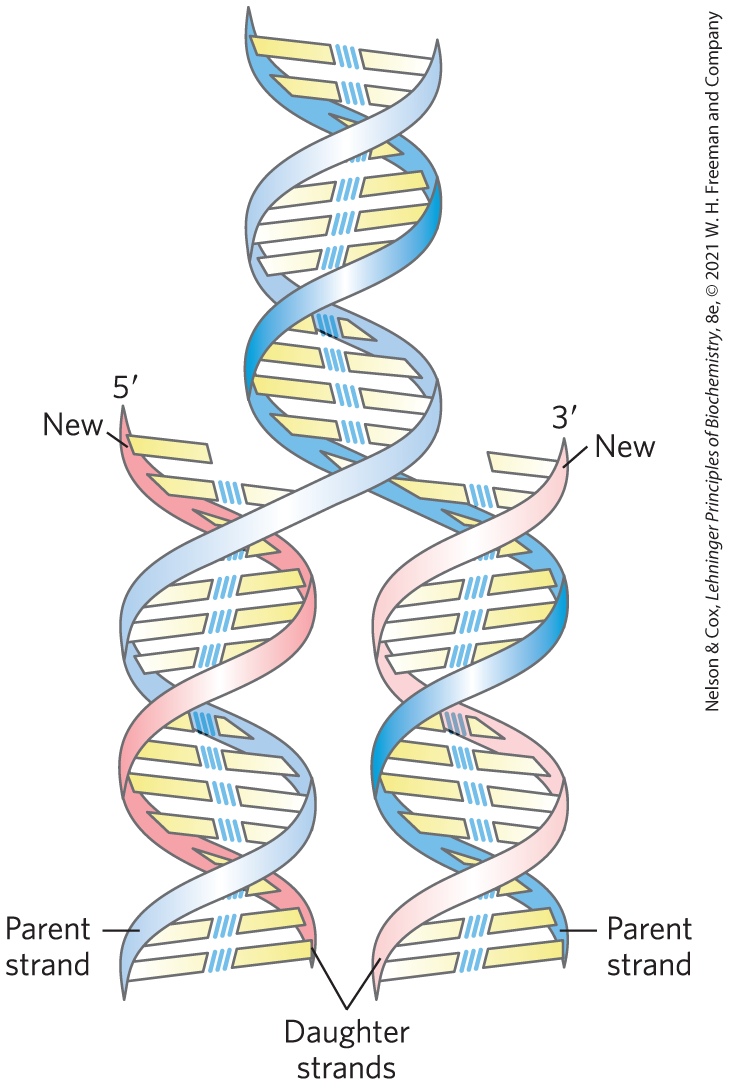

 a hydrogen bond with a ribose -hydroxyl group and in
a hydrogen bond with a ribose -hydroxyl group and in  a hydrogen bond with the oxygen of a ribose phosphodiester (both shown in red). (b) A hammerhead ribozyme (so named because the secondary structure at the active site looks like the head of a hammer), derived from certain plant viruses. Ribozymes, or RNA enzymes, catalyze a variety of reactions, primarily in RNA metabolism and protein synthesis. The complex three-dimensional structures of these RNAs reflect the complexity inherent in catalysis, as described for protein enzymes in
a hydrogen bond with the oxygen of a ribose phosphodiester (both shown in red). (b) A hammerhead ribozyme (so named because the secondary structure at the active site looks like the head of a hammer), derived from certain plant viruses. Ribozymes, or RNA enzymes, catalyze a variety of reactions, primarily in RNA metabolism and protein synthesis. The complex three-dimensional structures of these RNAs reflect the complexity inherent in catalysis, as described for protein enzymes in  Many lines of evidence show that DNA bears genetic information. Some of the earliest evidence came from the Avery-MacLeod-McCarty experiment, which showed that DNA isolated from one bacterial strain can enter and transform the cells of another strain, endowing the second strain with some of the inheritable characteristics of the donor. The Hershey-Chase experiment showed that the DNA of a bacterial virus, but not its protein coat, carries the genetic message for replication of the virus in a host cell.
Many lines of evidence show that DNA bears genetic information. Some of the earliest evidence came from the Avery-MacLeod-McCarty experiment, which showed that DNA isolated from one bacterial strain can enter and transform the cells of another strain, endowing the second strain with some of the inheritable characteristics of the donor. The Hershey-Chase experiment showed that the DNA of a bacterial virus, but not its protein coat, carries the genetic message for replication of the virus in a host cell.