26.3 RNA-Dependent Synthesis of RNA and DNA
In our discussion of DNA and RNA synthesis up to this point, the role of the template strand has been reserved for DNA. However, some enzymes use an RNA template for nucleic acid synthesis. With the important exception of viruses with an RNA genome, these enzymes play only supporting roles in information pathways. RNA viruses are the source of most characterized RNA-dependent polymerases, although some eukaryotes also use these enzymes to amplify double-stranded RNAs used in RNA interference.
The existence of RNA replication requires an elaboration of the central dogma — the notion that genetic information flows only from DNA to RNA to proteins. RNA-dependent polymerases allow the genetic information stored in RNA to be replicated and reverse transcribed into DNA. The enzymes of the RNA replication process have profound implications for investigations into the nature of self-replicating molecules that may have existed in prebiotic times.
Reverse Transcriptase Produces DNA from Viral RNA
Certain RNA viruses that infect animal cells carry within the viral particle an RNA-dependent DNA polymerase called reverse transcriptase. On infection, the single-stranded RNA viral genome (∼10,000 nucleotides) and the enzyme enter the host cell. The reverse transcriptase first catalyzes the synthesis of a DNA strand complementary to the viral RNA (Fig. 26-29), then degrades the RNA strand of the viral RNA-DNA hybrid and replaces it with DNA. The resulting duplex DNA often becomes incorporated into the genome of the eukaryotic host cell. These integrated (and dormant) viral genes can be activated and transcribed, and the gene products — viral proteins and the viral RNA genome itself — are packaged as new viruses. The RNA viruses that contain reverse transcriptases are known as retroviruses (retro is the Latin prefix for “backward”).
 Certain RNA viruses that infect animal cells carry within the viral particle an RNA-dependent DNA polymerase called
Certain RNA viruses that infect animal cells carry within the viral particle an RNA-dependent DNA polymerase called 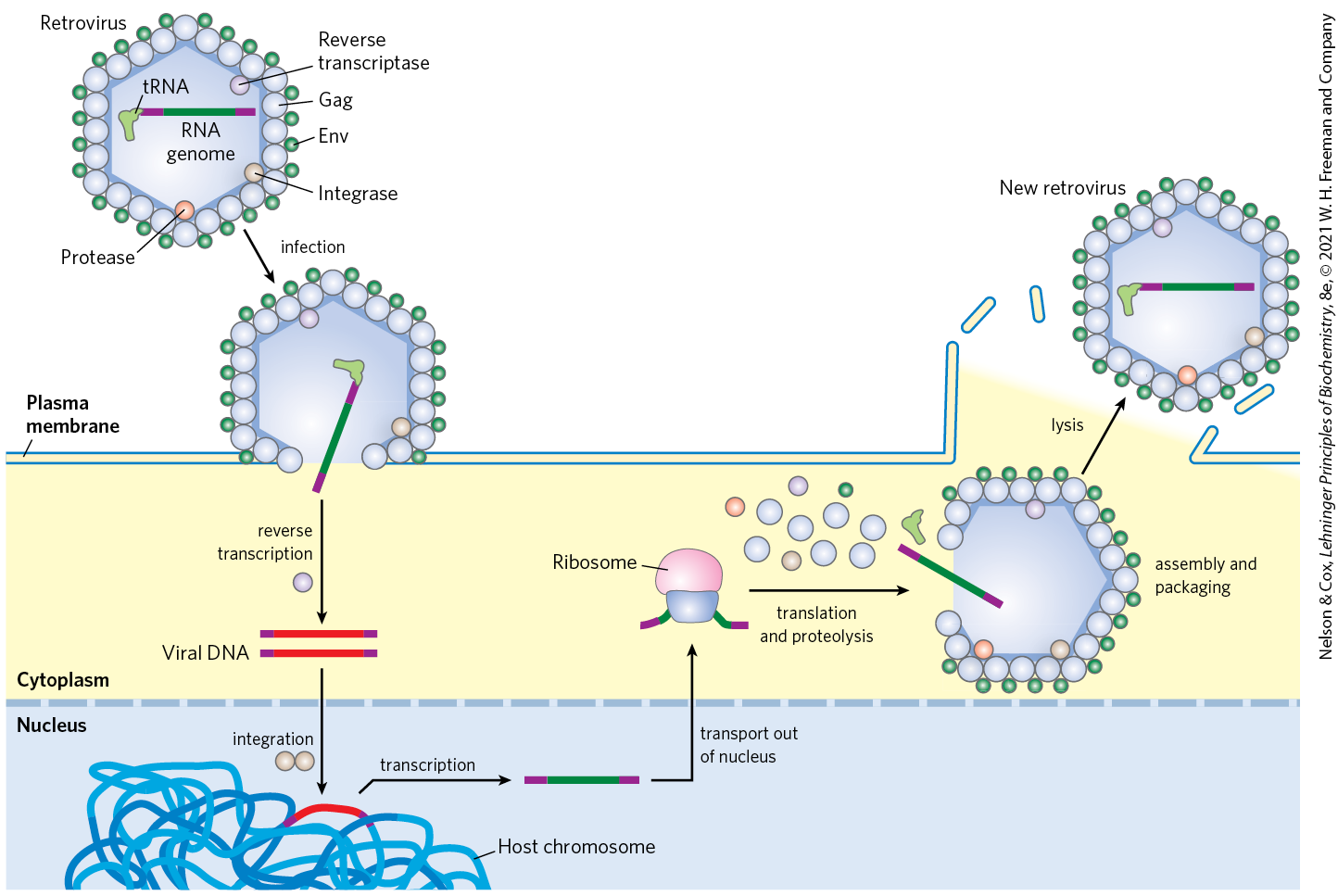
FIGURE 26-29 Retroviral infection of a mammalian cell and integration of the retrovirus into the host chromosome. Viral particles entering the host cell carry viral reverse transcriptase and a cellular tRNA (picked up from a former host cell) already base-paired to the viral RNA. The purple segments represent the long terminal repeats on the viral RNA. The tRNA facilitates immediate conversion of viral RNA to double-stranded DNA by the action of reverse transcriptase. The double-stranded DNA enters the nucleus and is integrated into the host genome. The integration is catalyzed by a virally encoded integrase. Integration of viral DNA into host DNA is mechanistically similar to the insertion of transposons in bacterial chromosomes (see Fig. 25-41). For example, a few base pairs of host DNA become duplicated at the site of integration, forming short repeats of 4 to 6 bp at each end of the inserted retroviral DNA (not shown). On transcription and translation of the integrated viral DNA, new viruses are formed and released by cell lysis (right). In the viruses, the viral RNA is enclosed by capsid proteins called Gag and outer envelope proteins called Env. Additional viral proteins (reverse transcriptase, integrase, and a viral protease needed for posttranslational processing of viral proteins) are packaged within the virus particle with the RNA.
The existence of reverse transcriptases in RNA viruses was predicted by Howard Temin in 1962, and the enzymes were ultimately detected by Temin and, independently, by David Baltimore in 1970. Their discovery aroused much attention as dogma-shaking proof that genetic information can flow “backward” from RNA to DNA.

Howard Temin, 1934–1994; David Baltimore
Retroviruses typically have three genes: gag (a name derived from the historical designation group associated antigen), pol, and env (Fig. 26-30). The transcript that contains gag and pol is translated into a long “polyprotein,” a single large polypeptide that is cleaved into six proteins with distinct functions. The proteins derived from the gag gene make up the interior core of the viral particle. The pol gene encodes the protease that cleaves the long polypeptide, an integrase that inserts the viral DNA into the host chromosomes, and reverse transcriptase. Many reverse transcriptases have two subunits, α and β. The pol gene specifies the β subunit (), and the α subunit () is simply a proteolytic fragment of the β subunit. The env gene encodes the proteins of the viral envelope. At each end of the linear RNA genome are long terminal repeat (LTR) sequences of a few hundred nucleotides. Transcribed into the duplex DNA, these sequences facilitate integration of the viral chromosome into the host DNA and contain promoters for viral gene expression.
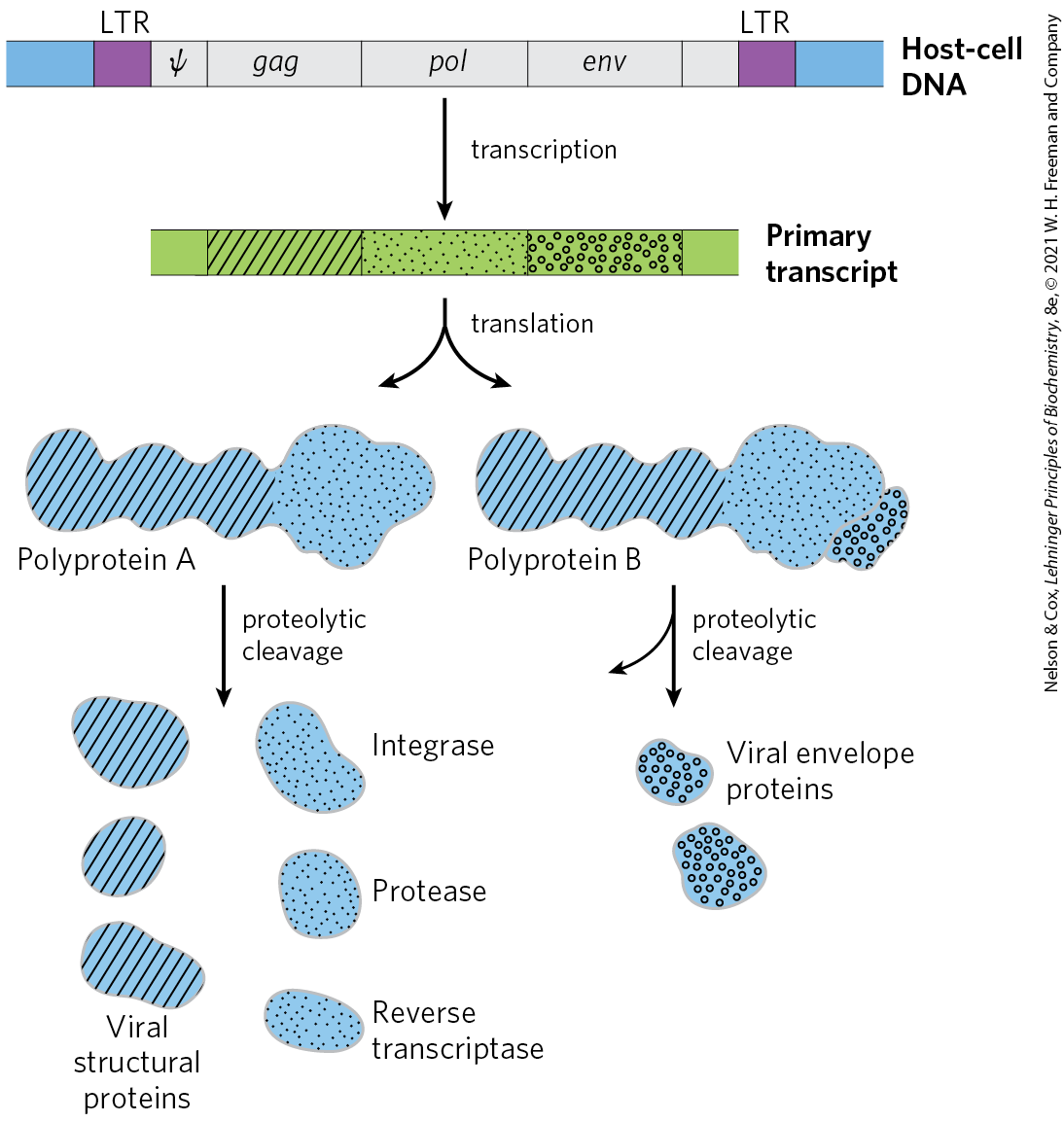
FIGURE 26-30 Structure and gene products of an integrated retroviral genome. The long terminal repeats (LTRs) have sequences needed for the regulation and initiation of transcription. The sequence denoted ψ is required for packaging of retroviral RNAs into mature viral particles. Transcription of the retroviral DNA produces a primary transcript encompassing the gag, pol, and env genes. Translation (Chapter 27) produces a polyprotein, a single long polypeptide derived from the gag and pol genes, which is cleaved into six distinct proteins. Splicing of the primary transcript yields an mRNA derived largely from the env gene, which is also translated into a polyprotein, then cleaved to generate viral envelope proteins.
Reverse transcriptases catalyze three different reactions: (1) RNA-dependent DNA synthesis, (2) RNA degradation, and (3) DNA-dependent DNA synthesis. Each transcriptase is most active with the RNA of its own virus, but each can be used experimentally to make DNA complementary to a variety of RNAs. The DNA and RNA synthesis and RNA degradation activities use separate active sites on the protein. For DNA synthesis to begin, the reverse transcriptase requires a primer, a cellular tRNA obtained during an earlier infection and carried in the viral particle. This tRNA is base-paired at its end with a complementary sequence in the viral RNA. The new DNA strand is synthesized in the direction, as in all RNA and DNA polymerase reactions. Reverse transcriptases, like RNA polymerases, do not have proofreading exonucleases. They generally have error rates of about 1 per 20,000 nucleotides added. An error rate this high is extremely unusual in DNA replication and seems to be a characteristic of most enzymes that replicate the genomes of RNA viruses. A consequence is a higher mutation rate and a faster rate of viral evolution, which is a factor in the frequent appearance of new strains of disease-causing retroviruses.
Reverse transcriptases have become important reagents in the study of DNA-RNA relationships and in DNA cloning techniques. They make possible the synthesis of DNA complementary to an mRNA template, and synthetic DNA prepared in this manner, called complementary DNA (cDNA), can be used to clone cellular genes (see Fig. 9-13).
Some Retroviruses Cause Cancer and AIDS
Retroviruses have featured prominently in the molecular understanding of cancer. Most retroviruses do not kill their host cells but remain integrated in the cellular DNA, replicating when the cell divides. Some retroviruses, classified as RNA tumor viruses, contain an oncogene that can cause the cell to grow abnormally. The first retrovirus of this type to be studied was the Rous sarcoma virus (also called avian sarcoma virus; Fig. 26-31), named for F. Peyton Rous, who studied chicken tumors now known to be caused by this virus. Since the initial discovery of oncogenes by Harold Varmus and Michael Bishop, many dozens of such genes have been found in retroviruses.


FIGURE 26-31 Rous sarcoma virus genome. The src gene encodes a tyrosine kinase, one of a class of enzymes that function in systems affecting cell division, cell-cell interactions, and intercellular communication (see Section 12.4). The same gene is found in chicken DNA (the usual host for this virus) and in the genomes of many other eukaryotes, including humans. When associated with the Rous sarcoma virus, this oncogene is often expressed at abnormally high levels, contributing to unregulated cell division and cancer.
The human immunodeficiency virus (HIV), which causes acquired immune deficiency syndrome (AIDS), is a retrovirus. Identified in 1983, HIV has an RNA genome with standard retroviral genes along with several other unusual genes (Fig. 26-32). Unlike many other retroviruses, HIV kills many of the cells it infects (principally T lymphocytes) rather than causing tumor formation. This gradually leads to suppression of the immune system in the host organism. The reverse transcriptase of HIV is even more error-prone than other known reverse transcriptases — 10 times more so — resulting in high mutation rates in this virus. One or more errors are generally made every time the viral genome is replicated, so any two viral RNA molecules are likely to differ.
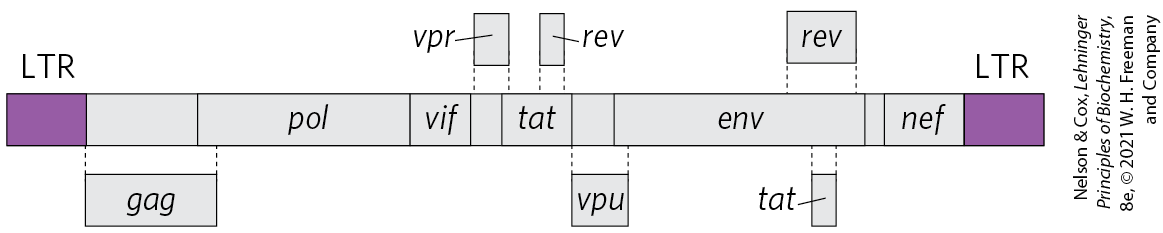
FIGURE 26-32 The genome of HIV, the virus that causes AIDS. In addition to the typical retroviral genes, HIV contains several small genes with a variety of functions (not identified here and not all known). Some of these genes overlap. Alternative splicing mechanisms produce many different proteins from this small ( nucleotides) genome.
Many modern vaccines for viral infections consist of one or more coat proteins of the virus, produced by methods described in Chapter 9. These proteins are not infectious on their own but stimulate the immune system to recognize and resist subsequent viral invasions (Chapter 5). Because of the high error rate of the HIV reverse transcriptase, the env gene in this virus (along with the rest of the genome) undergoes very rapid mutation, complicating the development of an effective vaccine. However, repeated cycles of cell invasion and replication are needed to propagate an HIV infection, so inhibition of viral enzymes offers the most effective therapy currently available. The HIV protease is targeted by a class of drugs called protease inhibitors (see Fig. 6-29). Reverse transcriptase is the target of some additional drugs widely used to treat HIV-infected individuals (Box 26-3).

Many Transposons, Retroviruses, and Introns May Have a Common Evolutionary Origin
Some well-characterized eukaryotic DNA transposons from sources as diverse as yeast and fruit flies have a structure very similar to that of retroviruses; these are sometimes called retrotransposons (Fig. 26-33). Retrotransposons encode an enzyme homologous to the retroviral reverse transcriptase, and their coding regions are flanked by LTR sequences. They transpose from one position to another in the cellular genome by means of an RNA intermediate, using reverse transcriptase to make a DNA copy of the RNA, followed by integration of the DNA at a new site. Most transposons in eukaryotes use this mechanism for transposition, distinguishing them from bacterial transposons, which move as DNA directly from one chromosomal location to another (see Fig. 25-41).
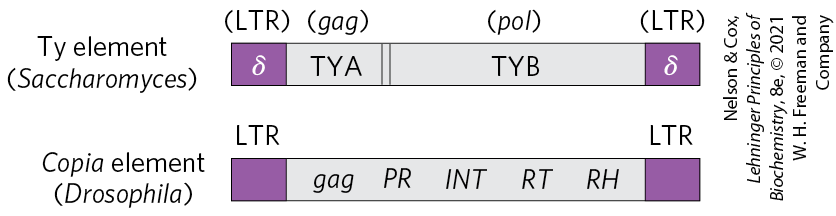
FIGURE 26-33 Eukaryotic transposons. The Ty element of the yeast Saccharomyces and the copia element of the fruit fly Drosophila are examples of eukaryotic retrotransposons, which often have a structure similar to retroviruses but lack the env gene. The δ sequences of the Ty element are functionally equivalent to retroviral LTRs. In the copia element, INT and RT are homologous to the integrase and reverse transcriptase segments, respectively, of the pol gene.
Retrotransposons lack an env gene and so cannot form viral particles. They can be thought of as defective viruses, trapped in cells. Comparisons between retroviruses and eukaryotic transposons suggest that reverse transcriptase is an ancient enzyme that predates the evolution of multicellular organisms.
Many group I and group II introns are also mobile genetic elements. In addition to their self-splicing activities, they encode DNA endonucleases that promote their movement. During genetic exchanges between cells of the same species, or when DNA is introduced into a cell by parasites or by other means, these endonucleases promote insertion of the intron into an identical site in another DNA copy of a homologous gene that does not contain the intron, in a process termed homing (Fig. 26-34). Whereas group I intron homing is DNA-based, group II intron homing occurs through an RNA intermediate. The endonucleases of the group II introns have associated reverse transcriptase activity. The proteins can form complexes with the intron RNAs themselves, after the introns are spliced from the primary transcripts. Because the homing process involves insertion of the RNA intron into DNA and reverse transcription of the intron, the movement of these introns has been called retrohoming. Over time, every copy of a particular gene in a population may acquire the intron. Much more rarely, the intron may insert itself into a new location in an unrelated gene. If this event does not kill the host cell, it can lead to the evolution and distribution of an intron in a new location. The structures and mechanisms used by mobile introns support the idea that at least some introns originated as molecular parasites whose evolutionary past can be traced to retroviruses and transposons.
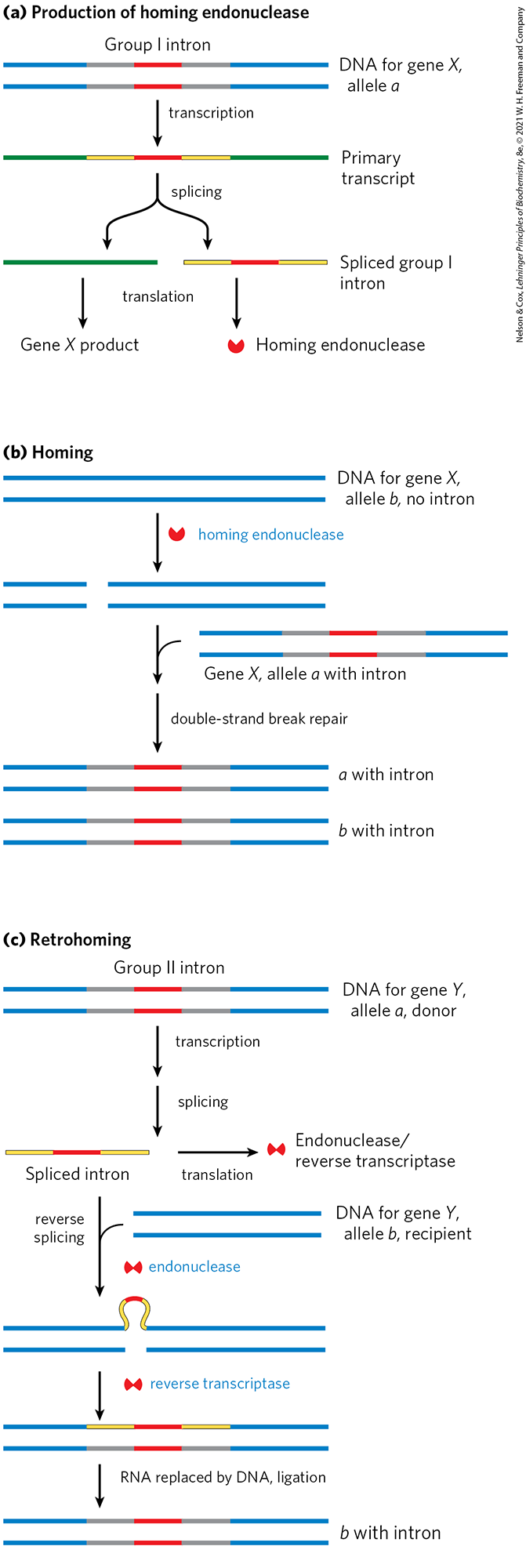
FIGURE 26-34 Introns that move: homing and retrohoming. Certain introns include a gene (shown in red) for enzymes that promote homing (some group I introns) or retrohoming (some group II introns). (a) The gene in the spliced intron is bound by a ribosome and translated. Group I homing introns specify a site-specific endonuclease, called a homing endonuclease. Group II retrohoming introns specify a protein with both endonuclease and reverse transcriptase activities (not shown here). (b) Homing. Allele a of a gene X containing a group I homing intron is present in a cell containing allele b of the same gene, which lacks the intron. The homing endonuclease produced by a cleaves b at the position corresponding to the intron in a, and double-strand break repair (recombination with allele a; see Fig. 25-34) then creates a new copy of the intron in b. (c) Retrohoming. Allele a of gene Y contains a retrohoming group II intron; allele b lacks the intron. The spliced intron inserts itself into the coding strand of b in a reaction that is the reverse of the splicing that excised the intron from the primary transcript (see Fig. 26-14), except that here the insertion is into DNA rather than RNA. The noncoding DNA strand of b is then cleaved by the intron-encoded endonuclease/reverse transcriptase. This same enzyme uses the inserted RNA as a template to synthesize a complementary DNA strand. The RNA is then degraded by cellular ribonucleases and replaced with DNA.
Telomerase Is a Specialized Reverse Transcriptase
Telomeres, the structures at the ends of linear eukaryotic chromosomes (see Fig. 24-7), generally consist of many tandem copies of a short oligonucleotide sequence. This sequence usually has the form in one strand and in the complementary strand, where x and y are typically in the range of 1 to 4 (p. 890). Telomeres vary in length from a few dozen base pairs in some ciliated protozoans to tens of thousands of base pairs in mammals. The TG strand is longer than its complement, leaving a region of single-stranded DNA of up to a few hundred nucleotides at the end.
The ends of a linear chromosome are not readily replicated by cellular DNA polymerases. DNA replication requires a template and primer, and beyond the end of a linear DNA molecule no template is available for the pairing of an RNA primer. Without a special mechanism for replicating the ends, chromosomes would be shortened somewhat in each cell generation. The enzyme telomerase, discovered by Carol Greider and Elizabeth Blackburn, solves this problem by adding telomeres to chromosome ends.

Carol Greider; Elizabeth Blackburn
The discovery and purification of this enzyme provided insight into a reaction mechanism that is remarkable and unprecedented. Telomerase, like some other enzymes described in this chapter, is an RNP that contains both RNA and protein components. The RNA component in humans is about 150 nucleotides long and contains about 1.5 copies of the appropriate telomere repeat. This region of the RNA acts as a template for synthesis of the strand of the telomere. Telomerase thereby acts as a cellular reverse transcriptase that provides the active site for RNA-dependent DNA synthesis. Unlike retroviral reverse transcriptases, telomerase copies only a small segment of RNA that it carries within itself. Telomere synthesis requires the end of a chromosome as primer and proceeds in the usual direction. Having synthesized one copy of the repeat, the enzyme repositions to resume extension of the telomere (Fig. 26-35a).
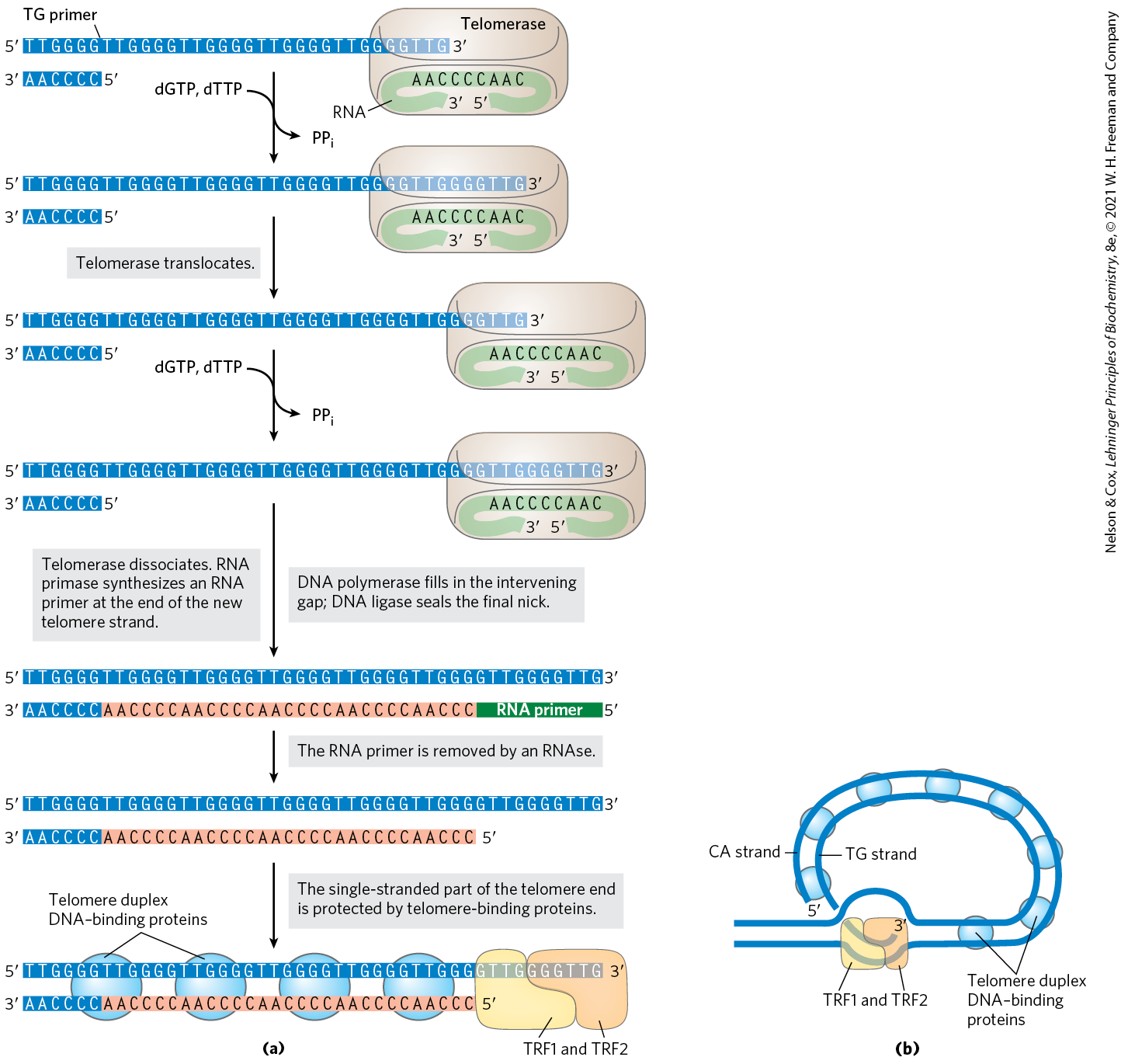
FIGURE 26-35 Telomere synthesis and structure. (a) The internal template RNA of telomerase binds to and base-pairs with the TG primer of DNA. Telomerase adds more T and G residues to the TG primer, then repositions the internal template RNA to allow the addition of more T and G residues to generate the TG strand of the telomere. The complementary strand is synthesized by cellular DNA polymerases, after priming by an RNA primase. (b) Proposed structure of T loops in telomeres. The single-stranded tail synthesized by telomerase is folded back and paired with its complement in the duplex portion of the telomere. The telomere is bound by several telomere-binding proteins, including TRF1 and TRF2 (telomere repeat binding factors).
After extension of the strand by telomerase, the complementary strand is synthesized by cellular DNA polymerases, starting with an RNA primer (see Fig. 25-11). The single-stranded region is protected by specific binding proteins in many lower eukaryotes, especially those species with telomeres of less than a few hundred base pairs. In higher eukaryotes (including mammals) with telomeres many thousands of base pairs long, the single-stranded end is sequestered in a specialized structure called a T loop (Fig. 26-35b). The single-stranded end is folded back and paired with its complement in the double-stranded portion of the telomere. The formation of a T loop involves invasion of the end of the telomere’s single strand into the duplex DNA, perhaps by a mechanism similar to the initiation of homologous genetic recombination (see Fig. 25-34). In mammals, the looped DNA is bound by two proteins, TRF1 and TRF2, with the latter protein involved in formation of the T loop. T loops protect the ends of chromosomes, making them inaccessible to nucleases and the enzymes that repair double-strand breaks.
In protozoans (such as Tetrahymena), loss of telomerase activity results in a gradual shortening of telomeres with each cell division, ultimately leading to the death of the cell line. A similar link between telomere length and cell senescence (cessation of cell division) has been observed in humans. In germ-line cells, which contain telomerase activity, telomere lengths are maintained; in somatic cells, which lack telomerase, they are not. There is a linear, inverse relationship between the length of telomeres in cultured fibroblasts and the age of the individual from whom the fibroblasts were taken: telomeres in human somatic cells gradually shorten as an individual ages. If the telomerase reverse transcriptase is introduced into human somatic cells in vitro, telomerase activity is restored and the cellular life span increases markedly.
Is the gradual shortening of telomeres a key to the aging process? Is our natural life span determined by the length of the telomeres we are born with? Further research in this area should yield some fascinating insights.
Some RNAs Are Replicated by RNA-Dependent RNA Polymerase
Apart from the retroviruses, the RNA viruses include some E. coli bacteriophages as well as eukaryotic viruses such as the influenza virus and coronaviruses that cause SARS or COVID-19. The single-stranded RNA chromosomes of these viruses also function as mRNAs for the synthesis of viral proteins. They are replicated in the host cell by an RNA-dependent RNA polymerase (RNA replicase). All RNA viruses — with the exception of retroviruses — must encode a protein with RNA-dependent RNA polymerase activity, either because the host cells lack such an enzyme or because the RNA genome structure of a virus imposes specialized enzymatic requirements.
The RNA replicase isolated from E. coli cells infected with the bacteriophage Qβ catalyzes the formation of an RNA complementary to the viral RNA, in a reaction equivalent to that catalyzed by DNA-dependent RNA polymerases. New RNA strand synthesis proceeds in the direction by a chemical mechanism identical to that used in all other nucleic acid synthetic reactions that require a template. RNA replicase requires RNA as its template and will not function with DNA. It lacks a separate proofreading endonuclease activity and has an error rate similar to that of RNA polymerase. Unlike the DNA and RNA polymerases, RNA replicases are specific for the RNA of their own virus; the RNAs of the host cell are generally not replicated. This explains how RNA viruses are preferentially replicated in the host cell, which contains many other types of RNA.
RNA-dependent RNA polymerases are not limited to viruses. Enzymes of this type are found in plants, protists, fungi, and some simpler animals, but not in insects or mammals. Those found in the genomes of eukaryotes generally play a role in the metabolism of another class of small RNAs, called small interfering RNAs (siRNAs), which participate in gene regulation (Chapter 28).
RNA-Dependent RNA Polymerases Share a Common Structural Fold
Even though viral RNA replication and reverse transcription, retrohoming, and telomere synthesis represent a diverse array of biological processes, the polymerases involved in each pathway bear remarkable similarities in structure (Fig. 26-36). In all cases, palm and finger domains are used to grip the duplexed template and primer nucleic acids within the active site. Amazingly, the group II intron retrohoming reverse transcriptase is structurally most closely related to a protein component of the spliceosome that helps scaffold its RNA active site. In addition to identical splicing chemistry and active site features (see Fig. 26-17), this provides further evidence that the spliceosome evolved from a group II intron–like ancestor.
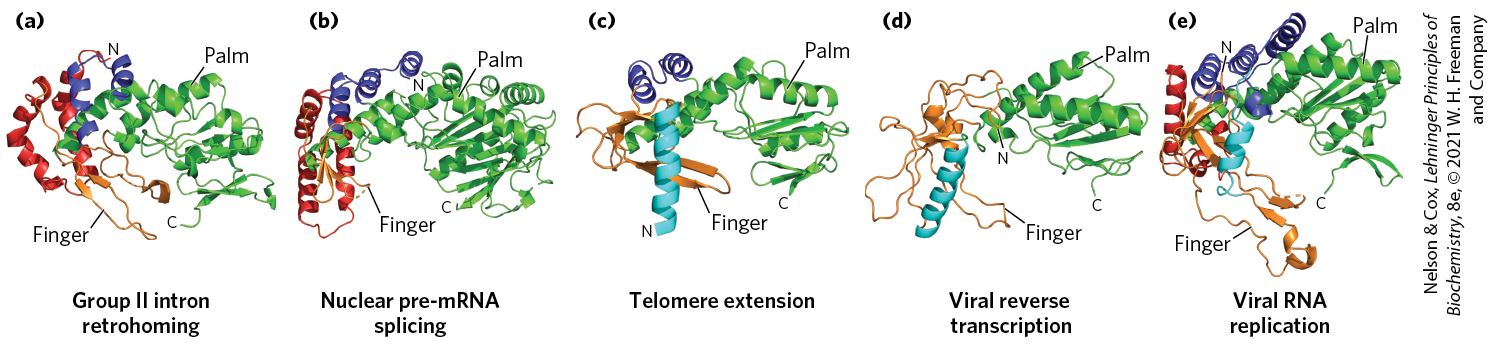
FIGURE 26-36 Structural similarities between RNA-dependent polymerases. RNA-dependent polymerases use a common active site architecture in which the duplexed substrate sits in a hand-shaped protein fold with palm and finger domains. This protein fold can be found in protein factors involved in (a) group II intron retrohoming, (b) spliceosome-catalyzed pre-mRNA splicing, (c) telomere synthesis, (d) HIV reverse transcription, and (e) hepatitis C viral genome replication. The retrohoming reverse transcriptase of group II introns is most structurally related to the reverse transcriptase structure present in the spliceosome, supporting their close evolutionary relationship. [Information from C. Zhao and A. M. Pyle, Nat. Struct. Mol. Biol. 23:558, 2016, Fig. 2. Data from (a) PDB ID 5HHJ, C. Zhao and A. M. Pyle, Nat. Struct. Mol. Biol. 23:558, 2016; (b) PDB ID 4I43, W. P. Galej et al., Nature 493:638, 2013; (c) PDB ID 3DU6, A. J. Gillis et al., Nature 455:633, 2008; (d) PDB ID 2HMI, J. Ding et al., J. Mol. Biol. 284:1095, 1998; (e) PDB ID 1C2P, C. A. Lesburg et al., Nat. Struct. Biol. 6:937, 1999.]
SUMMARY 26.3 RNA-Dependent Synthesis of RNA and DNA
- RNA-dependent DNA polymerases, also called reverse transcriptases, were first discovered in retroviruses, which must convert their RNA genomes into double-stranded DNA as part of their life cycle. These enzymes transcribe the viral RNA into DNA, a process that can be used experimentally to form cDNA.
- Retroviruses can cause human diseases, including AIDS and cancers. Some of these viruses contain oncogenes, which cause infected cells to grow abnormally.
- Many eukaryotic transposons are related to retroviruses, and their mechanism of transposition includes an RNA intermediate. An RNA intermediate is also present in group II intron retrohoming, in which the RNA intron is inserted into a DNA gene followed by production of a DNA copy by a reverse transcriptase.
- Telomerase, the enzyme that synthesizes the telomere ends of linear chromosomes, is a specialized reverse transcriptase that contains an internal RNA template.
- RNA-dependent RNA polymerases, such as the replicases of RNA bacteriophages, are template-specific for the viral RNA. These enzymes share structural homology with reverse transcriptases involved in retroviral replication, telomere production, and retrohoming.
 RNA-dependent DNA polymerases, also called reverse transcriptases, were first discovered in retroviruses, which must convert their RNA genomes into double-stranded DNA as part of their life cycle. These enzymes transcribe the viral RNA into DNA, a process that can be used experimentally to form cDNA.
RNA-dependent DNA polymerases, also called reverse transcriptases, were first discovered in retroviruses, which must convert their RNA genomes into double-stranded DNA as part of their life cycle. These enzymes transcribe the viral RNA into DNA, a process that can be used experimentally to form cDNA.