24.1 Chromosomal Elements
Cellular DNA contains genes and intergenic regions, both of which may serve functions vital to the cell. The more complex genomes, such as those of eukaryotic cells, demand increased levels of chromosomal organization, and this is reflected in the structural features of the chromosomes. We begin by considering the different types of DNA sequences and structural elements within chromosomes.
Genes Are Segments of DNA That Code for Polypeptide Chains and RNAs
Our understanding of genes has evolved tremendously over the past century. Classically, a gene was defined as a portion of a chromosome that determines or affects a single character or phenotype (visible property), such as eye color. George Beadle and Edward Tatum proposed a molecular definition of a gene in 1940. After exposing spores of the fungus Neurospora crassa to x-rays and other agents now known to damage DNA and cause alterations in DNA sequence (mutations), they detected mutant fungal strains that lacked one or another specific enzyme, sometimes resulting in the failure of an entire metabolic pathway. Beadle and Tatum concluded that a gene is a segment of genetic material that determines, or codes for, one enzyme: the one gene–one enzyme hypothesis. Later this concept was broadened to one gene–one polypeptide, because many genes code for a protein that is not an enzyme or for one polypeptide of a multisubunit protein.
The modern biochemical definition of a gene is even more precise. A gene is all the DNA that encodes the primary sequence of some final gene product, which can be either a polypeptide or an RNA with a structural or catalytic function. DNA also contains other segments or sequences that have a purely regulatory function. Regulatory sequences provide signals that may denote the beginning or the end of genes, or influence the transcription of genes, or function as initiation points for replication or recombination (Chapter 28). Some genes can be expressed in different ways to generate multiple gene products from a single segment of DNA; the special transcriptional and translational mechanisms that allow this are described in Chapters 26 through 28.
We can estimate directly the minimum overall size of genes that encode proteins. As described in detail in Chapter 27, each amino acid of a polypeptide chain is coded for by a sequence of three consecutive nucleotides in a single strand of DNA (Fig. 24-2), with these “codons” arranged in a sequence that corresponds to the sequence of amino acids in the polypeptide that the gene encodes. A polypeptide chain of 350 amino acid residues (an average-size chain) corresponds to 1,050 base pairs (bp) of coding DNA. Many genes in eukaryotes and a few in bacteria and archaea are interrupted by noncoding DNA segments and are therefore considerably longer than this simple calculation would suggest.
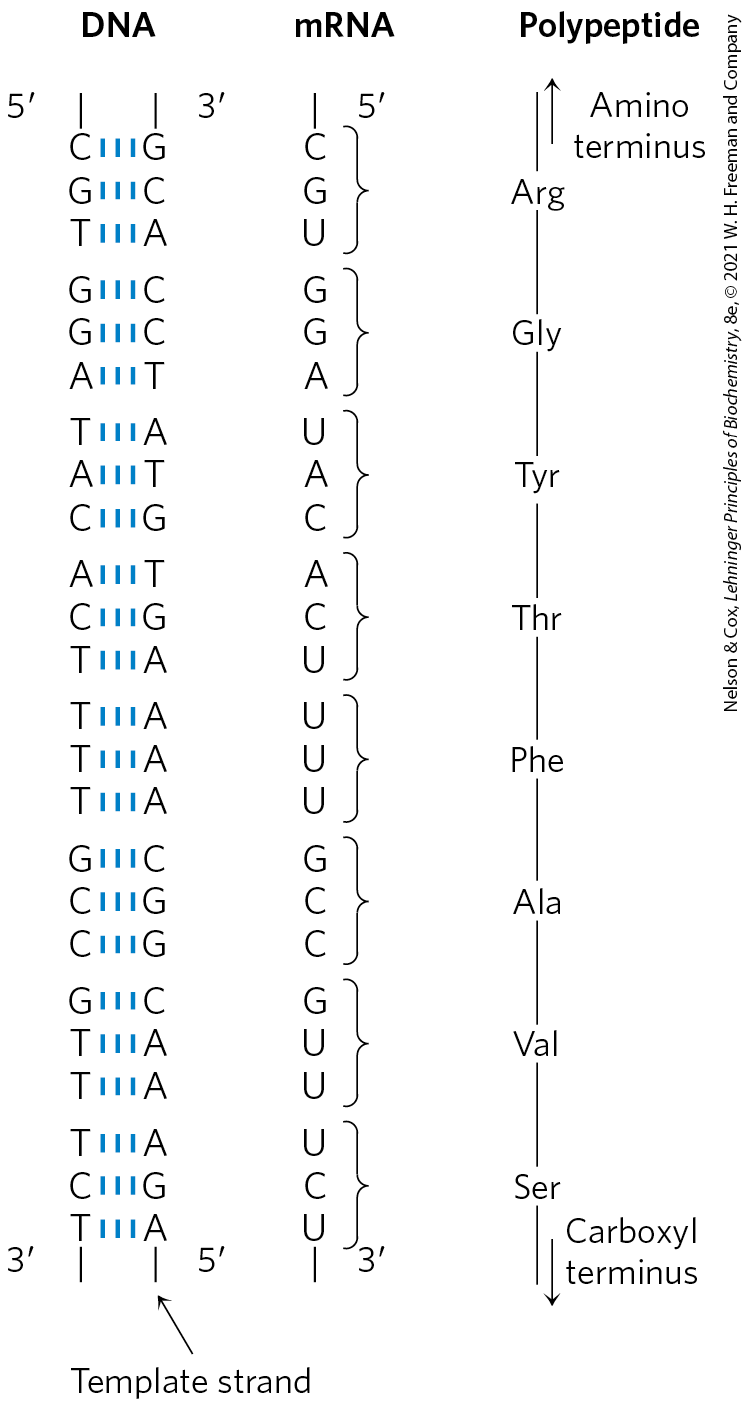
FIGURE 24-2 Colinearity of the coding nucleotide sequences of DNA and mRNA and the amino acid sequence of a polypeptide chain. The triplets of nucleotide units in DNA determine the amino acids in a protein through the intermediary mRNA. One of the DNA strands serves as a template for synthesis of mRNA, which has nucleotide triplets (codons) complementary to those of the DNA. In some bacterial and many eukaryotic genes, coding sequences are interrupted at intervals by regions of noncoding sequences (called introns).
How many genes are in a single chromosome? The Escherichia coli chromosome is a circular DNA molecule (in the sense of an endless loop rather than a perfect circle) with 4,641,652 bp. These base pairs encode about 4,300 genes for proteins and more than 200 genes for structural or catalytic RNA molecules. Among eukaryotes, the approximately 3.1 billion base pairs of the human genome include approximately 20,000 genes on the 24 different chromosomes.
DNA Molecules Are Much Longer than the Cellular or Viral Packages That Contain Them
Chromosomal DNAs are often many orders of magnitude longer than the cells or viruses in which they are located (Fig. 24-1; Table 24-1). This is true of every class of organism or viral parasite.
| Virus | Size of viral DNA (bp) | Length of viral DNA (nm) | Long dimension of viral particles (nm) |
|---|---|---|---|
ϕX174 |
5,386 |
1,939 |
25 |
T7 |
39,936 |
14,377 |
78 |
λ (lambda) |
48,502 |
17,460 |
190 |
T4 |
168,889 |
60,800 |
210 |
Note: Data on size of DNA are for the replicative form (double-stranded). The contour length is calculated assuming that each base pair occupies a length of 3.4 Å (see Fig. 8-13). |
|||
Viruses
Viruses are not free-living organisms; rather, they are infectious parasites that use the resources of a host cell to carry out many of the processes they require to propagate. Many viral particles consist of no more than a genome (usually a single RNA or DNA molecule) surrounded by a protein coat.
Almost all plant viruses and some bacterial and animal viruses have RNA genomes. These genomes tend to be particularly small. For example, the genomes of mammalian retroviruses such as HIV consist of 9,000 nucleotides of single-stranded RNA.
The genomes of DNA viruses vary greatly in size. Many viral DNAs are circular for at least part of their life cycle. During viral replication within a host cell, specific types of viral DNA called replicative forms may appear; for example, many linear DNAs become circular and all single-stranded DNAs become double-stranded. A typical medium-size DNA virus is bacteriophage λ (lambda), which infects E. coli. In its replicative form inside cells, λ DNA is a circular double helix. This double-stranded DNA contains 48,502 bp and has a contour length of 17.5 μm. Bacteriophage ϕX174 is much smaller; the DNA in the viral particle is a single-stranded circle, and the double-stranded replicative form contains 5,386 bp. Although viral genomes are small, the contour lengths of their DNAs are typically hundreds of times longer than the long dimensions of the viral particles that contain them (Table 24-1).
 Although viral genomes are small, the contour lengths of their DNAs are typically hundreds of times longer than the long dimensions of the viral particles that contain them (
Although viral genomes are small, the contour lengths of their DNAs are typically hundreds of times longer than the long dimensions of the viral particles that contain them (Bacteria
A single E. coli cell contains almost 100 times as much DNA as a bacteriophage λ particle. The chromosome of an E. coli cell is a single, double-stranded circular DNA molecule. Its 4,641,652 bp have a contour length of about 1.7 mm, some 850 times the length of the E. coli cell (Fig. 24-3). In addition to the very large, circular DNA chromosome in their nucleoid, many bacteria contain one or more small circular DNA molecules that are free in the cytosol. These extrachromosomal elements are called plasmids (Fig. 24-4; see also p. 305). Most plasmids are only a few thousand base pairs long, but some contain up to 400,000 bp. They carry genetic information and undergo replication to yield daughter plasmids, which pass into the daughter cells at cell division. Plasmids have been found in yeast and other fungi as well as in bacteria.

FIGURE 24-3 A bacterial cell and its DNA. The length of the E. coli chromosome (1.7 mm), depicted in linear form, relative to the length of a typical E. coli cell (2 μm).
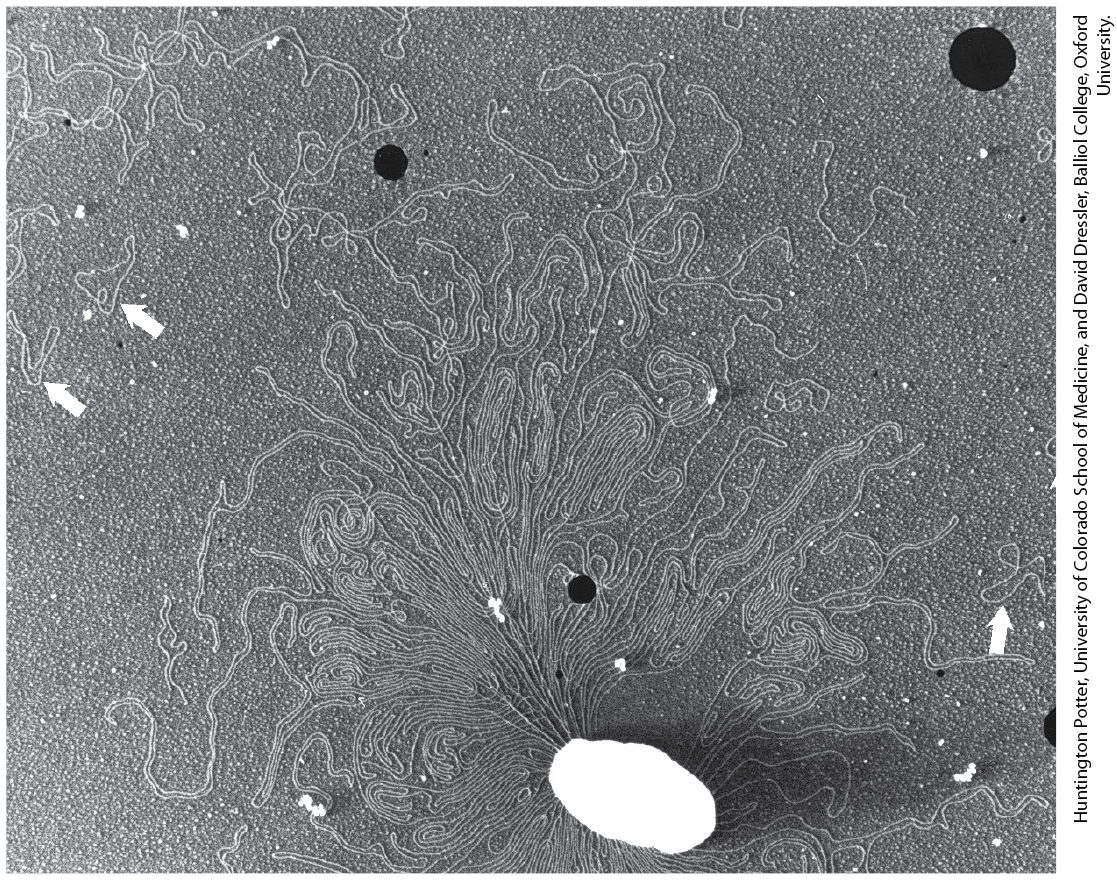
FIGURE 24-4 DNA from a lysed E. coli cell. In this electron micrograph, several small, circular plasmid DNAs are indicated by white arrows. The black spots and white specks are artifacts of the preparation.
In many cases plasmids confer no obvious advantage on their host, and their sole function seems to be self-propagation. However, some plasmids carry genes that are useful to the host bacterium. For example, some plasmid genes make a host bacterium resistant to antibacterial agents. Plasmids carrying the gene for the enzyme β-lactamase confer resistance to β-lactam antibiotics such as penicillin, ampicillin, and amoxicillin (see Fig. 6-34). These and similar plasmids may pass from an antibiotic-resistant cell to an antibiotic-sensitive cell of the same or another bacterial species, making the recipient cell antibiotic-resistant. The extensive use of antibiotics in some human populations and in animal feeds has served as a strong selective force, encouraging the spread of antibiotic resistance–coding plasmids (as well as transposable elements, described below, that harbor similar genes) in disease-causing bacteria.
Eukaryotes
A yeast cell, one of the simplest eukaryotes, has 2.6 times more DNA in its genome than an E. coli cell (Table 24-2). Cells of Drosophila, the fruit fly used in classical genetic studies, contain more than 35 times as much DNA as E. coli cells, and human cells have almost 700 times as much. The cells of many plants and amphibians contain even more. The genetic material of eukaryotic cells is apportioned into chromosomes, the diploid (2n) number depending on the species. A human somatic cell, for example, has 46 chromosomes (Fig. 24-5). Each chromosome of a eukaryotic cell, such as that shown in Figure 24-5a, contains a single, very large, duplex DNA molecule. The DNA molecules in the 24 different types of human chromosomes (22 matching pairs of autosomes plus the X and Y sex chromosomes) vary in length over a 25-fold range. Each type of chromosome in eukaryotes carries a characteristic set of genes.
| Total DNA (bp) | Number of chromosomesa | Approximate number of protein-coding genes | |
|---|---|---|---|
Escherichia coli K12 (bacterium) |
4,641,652 |
1 |
4,494b |
Saccharomyces cerevisiae (yeast) |
12,157,105 |
16c |
6,600 |
Caenorhabditis elegans (nematode) |
100,286,401 |
12d |
20,191 |
Arabidopsis thaliana (plant) |
119,667,750 |
10 |
27,655 |
Drosophila melanogaster (fruit fly) |
143,726,002 |
18 |
13,931 |
Oryza sativa (rice) |
375,049,285 |
24 |
37,849 |
Mus musculus (mouse) |
2,730,871,774 |
40 |
22,480 |
Homo sapiens (human) |
3,096,649,726 |
46 |
20,454e |
Note: This information is constantly being refined. For the most current information, consult the websites for the individual genome projects. [Data from ensembl.org. Accessed April 21, 2020.] aThe diploid chromosome number is given for all eukaryotes except yeast. bIncludes known RNA-coding genes. cHaploid chromosomes number. Wild yeast strains generally have eight (octoploid) or more sets of these chromosomes. dNumber for females, with two X chromosomes. Males have an X but no Y, thus 11 chromosomes in all. eWhen known genes encoding functional RNAs are included, this number rises to more than 43,000. |
|||
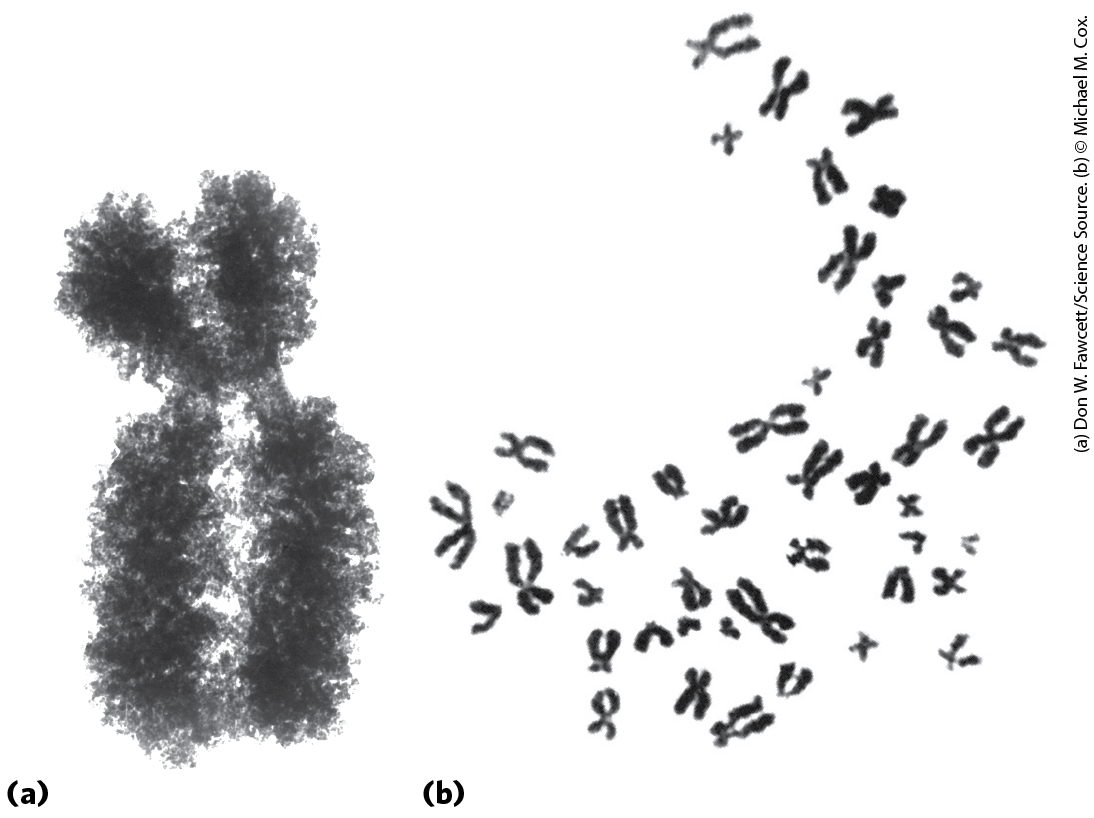
FIGURE 24-5 Eukaryotic chromosomes. (a) A pair of linked and condensed sister chromatids from a Chinese hamster ovary cell. Eukaryotic chromosomes are in this state after replication at metaphase during mitosis. (b) A complete set of chromosomes from a leukocyte from one of the authors. There are 46 chromosomes in every normal human somatic cell.
DNA molecules of one human genome (22 chromosomes plus X and Y), placed end to end, would extend for about a meter. Most human cells are diploid, so each cell contains a total of 2 m of DNA. An adult human body contains approximately cells and thus a total DNA length of . Compare this with the circumference of the earth or the distance between the earth and the sun — a dramatic illustration of the extraordinary degree of DNA compaction in our cells.
Eukaryotic cells also have organelles, mitochondria and chloroplasts, that contain DNA. Mitochondrial DNA (mtDNA) molecules are much smaller than the nuclear chromosomes. In animal cells, mtDNA contains fewer than 20,000 bp (16,569 bp in human mtDNA) and is a circular duplex. Each mitochondrion typically has 2 to 10 copies of this mtDNA molecule, and the number can rise to hundreds in certain cells of an embryo that is undergoing cell differentiation. Plant cell mtDNA ranges in size from 200,000 to 2,500,000 bp. Chloroplast DNA (cpDNA) also exists as circular duplexes and ranges in size from 120,000 to 160,000 bp. Mitochondrial and chloroplast DNAs have an evolutionary origin in the chromosomes of ancient bacteria that gained access to the cytoplasm of host cells and became the precursors of these organelles (see Fig. 1-37). Mitochondrial DNA codes for the mitochondrial tRNAs and rRNAs and for a few mitochondrial proteins. More than 95% of mitochondrial proteins are encoded by nuclear DNA. Mitochondria and chloroplasts divide when the cell divides. Their DNA is replicated before and during division, and the daughter DNA molecules pass into the daughter organelles.
Eukaryotic Genes and Chromosomes Are Very Complex
Many bacterial species have only one chromosome per cell and, in nearly all cases, each chromosome contains only one copy of each gene. A very few genes, such as those for rRNAs, are repeated several times. Genes and regulatory sequences account for almost all the DNA in bacteria. Moreover, almost every gene is precisely colinear with the amino acid sequence (or RNA sequence) it encodes throughout its entire length (Fig. 24-2).
The organization of genes in eukaryotic DNA is structurally and functionally much more complex. Studies of eukaryotic chromosome structure and the sequencing of entire eukaryotic genomes have yielded many surprises. Many, if not most, eukaryotic genes have a distinctive structural feature: the colinearity of the DNA and amino acid sequence is periodically broken by intervening segments of DNA that do not code for the amino acid sequence of the polypeptide product. Such nontranslated DNA segments in genes are called introns, and the coding segments are called exons. Few bacterial genes contain introns. In higher eukaryotes, the typical gene has much more intron sequence than sequences devoted to exons. For example, in the gene coding for the single polypeptide chain of ovalbumin, an avian egg protein (Fig. 24-6), the introns are much longer than the exons; altogether, the seven introns make up 85% of the gene’s DNA. The gene encoding the hemoglobin β subunit has only two introns, but again they are larger than the exons. Genes for histones seem to have no introns. In many cases the function of introns is not clear. In total, only about 1.5% of human DNA is “coding” or exon DNA, carrying sequence information for protein products. However, when the much larger introns are included as functional elements in the gene and their length is included, as much as 30% of the human genome consists of protein-coding genes.
 Many, if not most, eukaryotic genes have a distinctive structural feature: the colinearity of the DNA and amino acid sequence is periodically broken by intervening segments of DNA that do not code for the amino acid sequence of the polypeptide product. Such nontranslated DNA segments in genes are called
Many, if not most, eukaryotic genes have a distinctive structural feature: the colinearity of the DNA and amino acid sequence is periodically broken by intervening segments of DNA that do not code for the amino acid sequence of the polypeptide product. Such nontranslated DNA segments in genes are called 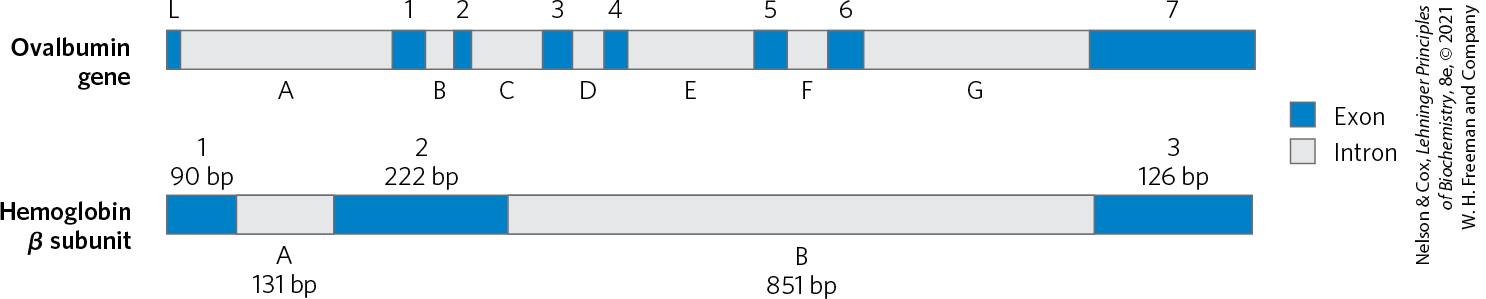
FIGURE 24-6 Introns in two eukaryotic genes. The gene for ovalbumin has seven introns (A to G), splitting the coding sequences into eight exons (L, and 1 to 7). The gene for the β subunit of hemoglobin has two introns and three exons, including one intron that alone contains more than half the base pairs of the gene.
A great deal of work remains to be done to understand the genomic sequences that do not correspond to protein-encoding genes. Much of the DNA that is not within genes is made up of repeated sequences of several kinds. These include transposable elements (transposons), molecular parasites that account for nearly half of the DNA in the human genome (see Fig. 9-25a and Chapters 25 and 26), and genes encoding functional RNA molecules of many types.
Approximately 3% of the human genome consists of highly repetitive sequences, also referred to as simple-sequence DNA or simple sequence repeats (SSR). These short sequences, generally less than 10 bp long, are sometimes repeated millions of times per cell. The simple-sequence DNA is also called satellite DNA, so named because its unusual base composition often causes it to migrate as “satellite” bands (separated from the rest of the DNA) when fragmented cellular DNA samples are centrifuged in a cesium chloride density gradient. Studies suggest that simple-sequence DNA does not encode proteins or RNAs. The functional importance of the highly repetitive DNA has been defined in at least some cases. Much of it is associated with two crucial features of eukaryotic chromosomes: centromeres and telomeres.
The centromere (Fig. 24-7) is a sequence of DNA that functions during cell division as an attachment point for proteins that link the chromosome to the mitotic spindle. This attachment is essential for the equal and orderly segregation of chromosome sets to daughter cells. The centromeres of Saccharomyces cerevisiae have been isolated and studied. The sequences essential to centromere function are about 130 bp long and are very rich in pairs. The centromeric sequences of higher eukaryotes are much longer and, unlike those of yeast, generally consist of thousands of tandem copies of one or several sequences of 5 to 10 bp, in the same orientation.
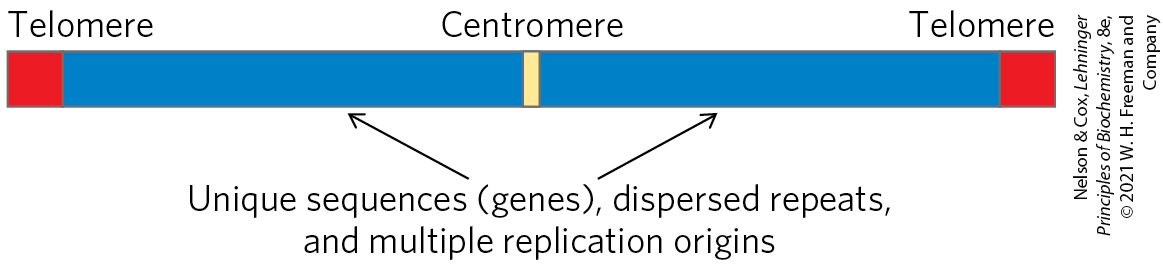
FIGURE 24-7 Important structural elements of a yeast chromosome.
Telomeres (Greek telos, “end”) are sequences at the ends of eukaryotic chromosomes that help stabilize the chromosome. Telomeres end with multiple repeated sequences of the form
where x and y are generally between 1 and 4 (Table 24-3). The number of telomere repeats, n, is in the range of 20 to 100 for most single-celled eukaryotes and is generally more than 1,500 in mammals. The ends of a linear DNA molecule cannot be routinely replicated by the cellular replication machinery (which may be one reason why bacterial DNA molecules are circular). Repeated telomeric sequences are added to eukaryotic chromosome ends primarily by the enzyme telomerase (see Fig. 26-35).
| Organism | Telomere repeat sequence |
|---|---|
Homo sapiens (human) |
|
Tetrahymena thermophila (ciliated protozoan) |
|
Saccharomyces cerevisiae (yeast) |
|
Arabidopsis thaliana (plant) |
Artificial chromosomes (Chapter 9) have been constructed as a means of better understanding the functional significance of many structural features of eukaryotic chromosomes. A reasonably stable artificial linear chromosome requires only three components: a centromere, a telomere at each end, and sequences that allow the initiation of DNA replication. Yeast artificial chromosomes (YACs; see Fig. 9-6) have been developed as a research tool in biotechnology. Similarly, human artificial chromosomes (HACs) are being developed for the treatment of genetic diseases. These may eventually provide a new path to the intracellular replacement of missing or defective gene products, or somatic gene therapy.
SUMMARY 24.1 Chromosomal Elements
- Genes are segments of a chromosome that contain the information for a functional polypeptide or RNA molecule. In addition to genes, chromosomes contain a variety of regulatory sequences involved in replication, transcription, and other processes.
- Genomic DNA and RNA molecules are generally orders of magnitude longer than the viral particles or cells that contain them.
- Many genes in eukaryotic cells (but few in bacteria and archaea) are interrupted by noncoding sequences, or introns. The coding segments separated by introns are called exons. Only about 1.5% of human genomic DNA encodes proteins; even when introns are included, less than one-third of human genomic DNA consists of genes. Much of the remainder consists of repeated sequences of various types. Nucleic acid parasites known as transposons account for about half of the human genome. Eukaryotic chromosomes have two important special-function repetitive DNA sequences: centromeres, which are attachment points for the mitotic spindle, and telomeres, located at the ends of chromosomes.
 Genes are segments of a chromosome that contain the information for a functional polypeptide or RNA molecule. In addition to genes, chromosomes contain a variety of regulatory sequences involved in replication, transcription, and other processes.
Genes are segments of a chromosome that contain the information for a functional polypeptide or RNA molecule. In addition to genes, chromosomes contain a variety of regulatory sequences involved in replication, transcription, and other processes.