As we have seen for DNA and RNA (Chapters 25 and 26), the synthesis of polymeric biomolecules can be considered in terms of initiation, elongation, and termination stages. These fundamental processes are typically bracketed by two additional stages: activation of precursors before synthesis and postsynthetic processing of the completed polymer. Protein synthesis follows the same pattern. The activation of amino acids before their incorporation into polypeptides and the posttranslational processing of the completed polypeptide play particularly important roles in ensuring both the fidelity of synthesis and the proper function of the protein product. The process is outlined in Figure 27-13. The cellular components involved in the five stages of protein synthesis in E. coli and other bacteria are listed in Table 27-5; the requirements in eukaryotic cells are similar, although the components are usually more numerous. Before looking at these five stages in detail, we must examine two key components of protein biosynthesis: the ribosome and tRNAs.
FIGURE 27-13 An overview of the five stages of protein synthesis.
TABLE 27-5 Components Required for the Five Major Stages of Protein Synthesis in E. coli
Stage
Essential components
1. Activation of amino acids
20 amino acids
20 aminoacyl-tRNA synthases
32 or more tRNAs
ATP
2. Initiation
mRNA
Initiation codon in mRNA (AUG)
30S ribosomal subunit
50S ribosomal subunit
Initiation factors (IF1, IF2, IF3)
GTP
3. Elongation
Functional 70S ribosomes (initiation complex)
Aminoacyl-tRNAs specified by codons
Elongation factors (EF-Tu, EF-Ts, EF-G)
GTP
4. Termination and ribosome recycling
Termination codon in mRNA
Release factors (RF1, RF2, RF3, RRF)
EF-G
IF3
5. Folding and posttranslational processing
Chaperones and folding enzymes (PPI, PDI); specific enzymes, cofactors, and other components for removal of initiating residues and signal sequences, additional proteolytic processing, modification of terminal residues, and attachment of acetyl, phosphoryl, methyl, carboxyl, carbohydrate, or prosthetic groups
The Ribosome Is a Complex Supramolecular Machine
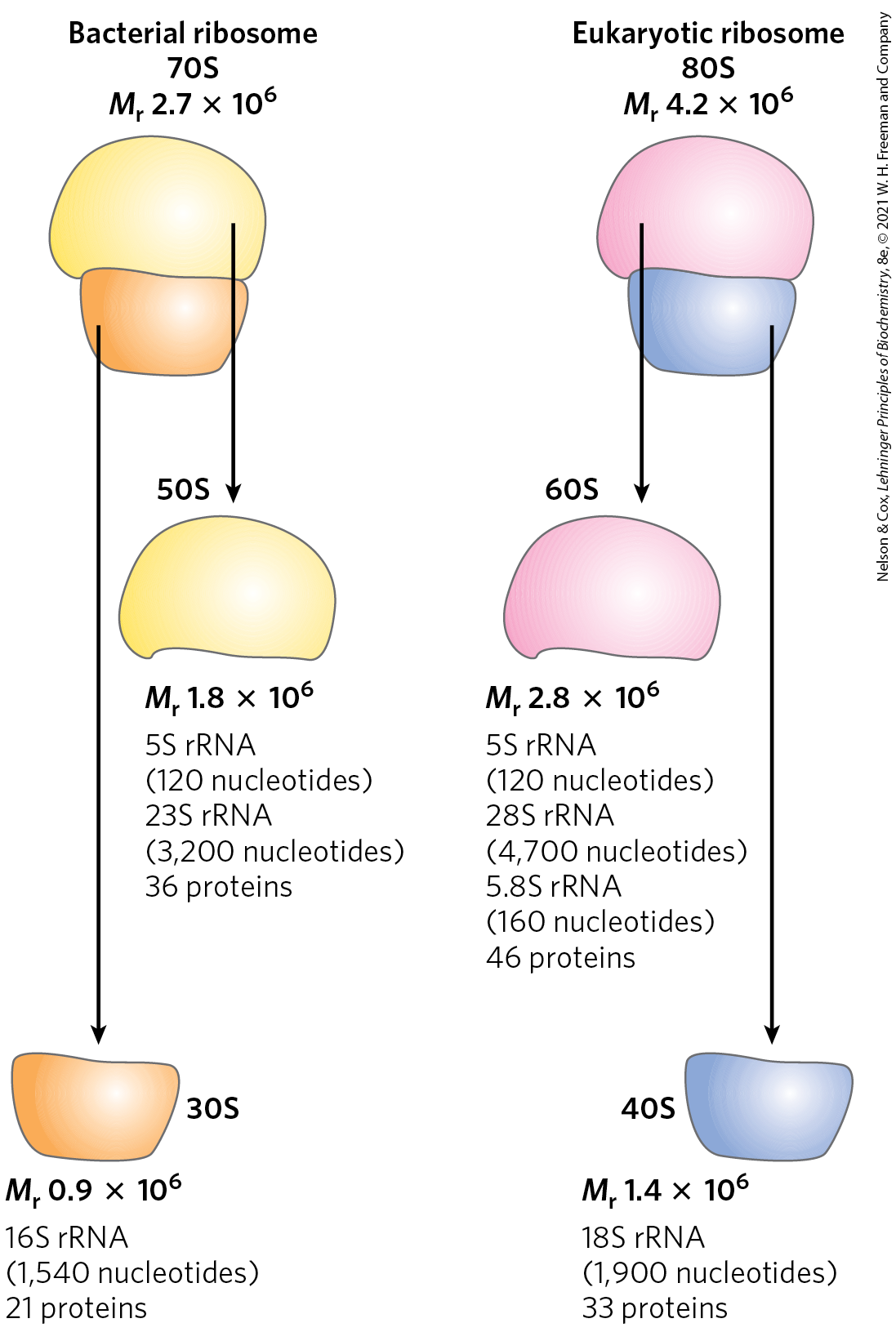
Each E. coli cell contains 15,000 or more ribosomes, which comprise nearly a quarter of the dry weight of the cell. Bacterial ribosomes contain about 65% rRNA and 35% protein; they have a diameter of about 18 nm and are composed of two unequal subunits with sedimentation coefficients of 30S and 50S and a combined sedimentation coefficient of 70S. Both subunits contain dozens of ribosomal proteins (r-proteins) and at least one large rRNA (Table 27-6).
TABLE 27-6 RNA and Protein Components of the E. coli Ribosome
aThe L1 to L36 protein designations do not correspond to 36 different proteins. The protein originally designated L7 is a modified form of L12, and L8 is a complex of three other proteins. Also, L26 proved to be the same protein as S20 (and not part of the 50S subunit). This gives 33 different proteins in the large subunit. There are four copies of the L7/L12 protein, with the three extra copies bringing the total protein count to 36.
As it became clear that ribosomes are the complexes responsible for protein synthesis, and following elucidation of the genetic code, the study of ribosomes accelerated. In the late 1960s Masayasu Nomura and colleagues demonstrated that both ribosomal subunits can be broken down into their RNA and protein components, then reconstituted in vitro. Ribosomal subunits are identified by their S (Svedberg unit) values, sedimentation coefficients that refer to their rate of sedimentation in a centrifuge. Under appropriate experimental conditions, the RNA and protein spontaneously reassemble to form 30S or 50S subunits nearly identical in structure and activity to native subunits. This breakthrough fueled decades of research into the function and structure of ribosomal RNAs and proteins. At the same time, increasingly sophisticated structural methods revealed more and more details about ribosome structure.
The dawn of a new millennium illuminated the first high-resolution structures of bacterial ribosomal subunits by Venkatraman Ramakrishnan, Thomas Steitz, Ada Yonath, Harry Noller, and others. This work yielded a wealth of surprises (Fig. 27-14a). First, a traditional focus on the protein components of ribosomes was shifted. The ribosomal subunits are huge RNA molecules. In the 50S subunit, the 5S and 23S rRNAs form the structural core. The proteins are secondary elements in the complex, decorating the surface. Second, and most important, there is no protein within 18 Å of the active site for peptide bond formation. The high-resolution structure thus confirms what Noller had predicted much earlier: the ribosome is a ribozyme. In addition to the insight that the detailed structures of the ribosome and its subunits provide into the mechanism of protein synthesis (as elaborated below), these findings have stimulated a new look at the evolution of life (Section 26.4). The ribosomes of eukaryotic cells have also yielded to structural analysis (Fig. 27-14b).
FIGURE 27-14 The structure of ribosomes. Our understanding of ribosome structure has been greatly enhanced by multiple high-resolution images of the ribosomes from bacteria and yeast. (a) The bacterial ribosome. The 50S and 30S subunits come together to form the 70S ribosome. The cleft between them is where protein synthesis occurs. (b) The yeast ribosome has a similar structure with somewhat increased complexity. [Data from (a) PDB ID 4V4I, A. Korostelev et al., Cell 126:1065, 2006; (b) PDB ID 4V7R, A. Ben-Shem et al., Science 330:1203, 2010.]
The bacterial ribosome is complex, with a combined molecular weight of ∼2.7 million. The two irregularly shaped ribosomal subunits fit together to form a cleft through which the mRNA passes as the ribosome moves along it during translation (Fig. 27-14a). The 57 proteins in bacterial ribosomes vary enormously in size and structure. Molecular weights range from about 6,000 to 75,000. Most of the proteins have globular domains arranged on the ribosome surface. Some also have snakelike extensions that protrude into the rRNA core of the ribosome, stabilizing its structure. The functions of some of these proteins have not yet been elucidated in detail, although a structural role seems evident for many of them.
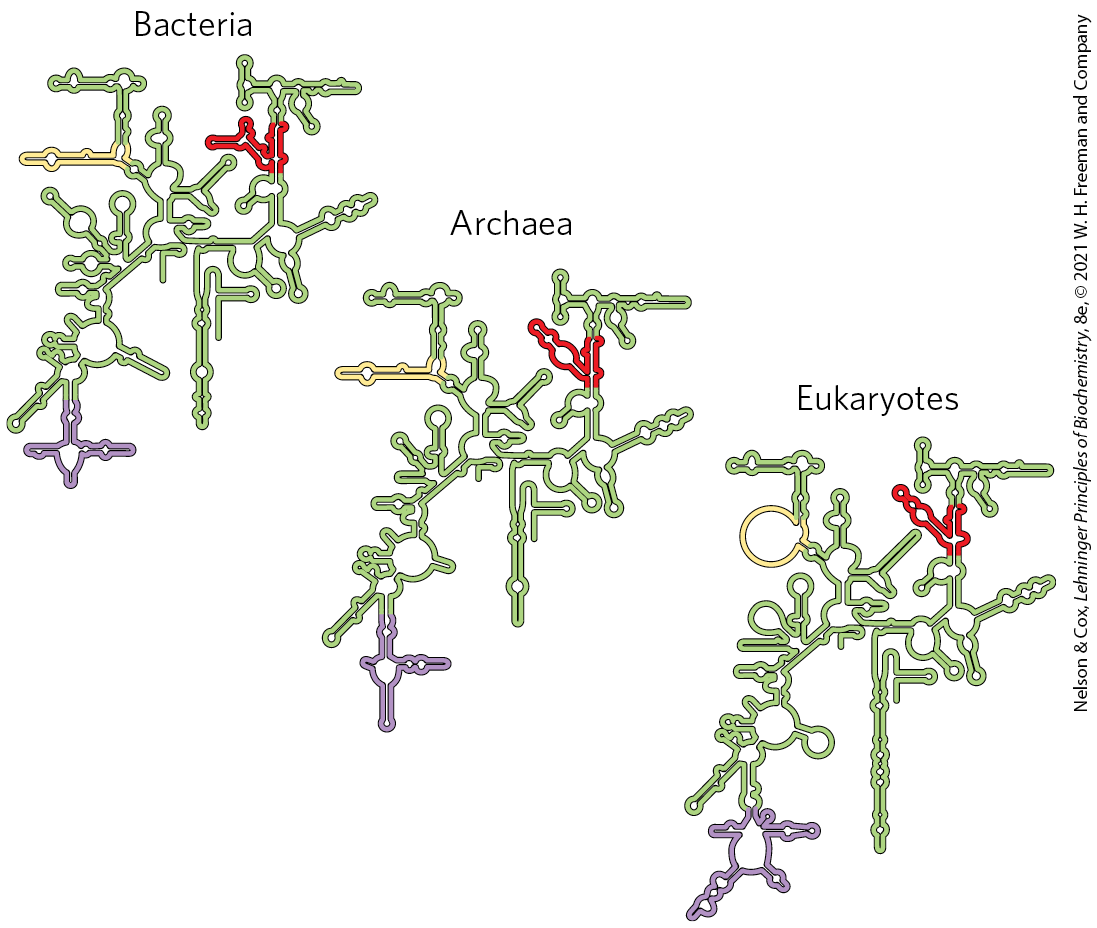
The sequences of the rRNAs of countless thousands of organisms are now known due to genomic sequencing. Each of the three single-stranded rRNAs of E. coli has a specific three-dimensional conformation with extensive intrachain base pairing. The folding patterns of the rRNAs are highly conserved in all organisms, particularly the regions implicated in key functions (Fig. 27-15). The predicted secondary structure of the rRNAs has largely been confirmed by structural analysis but fails to convey the extensive network of tertiary interactions apparent in the complete structure.
FIGURE 27-15 Conservation of secondary structure in the small subunit rRNAs from the three domains of life. The red, yellow, and purple indicate areas where the structures of the rRNAs from bacteria, archaea, and eukaryotes have diverged. Conserved regions are shown in green. [Information originally from the Comparative RNA Web, University of Texas.]
The ribosomes of eukaryotic cells (other than mitochondrial and chloroplast ribosomes) are larger and more complex than bacterial ribosomes (Fig. 27-16; compare Fig. 27-14b), with a diameter of about 23 nm and a sedimentation coefficient of about 80S. They also have two subunits, which vary in size among species but on average are 60S and 40S. Altogether, a ribosome of the yeast Saccharomyces cerevisiae contains 79 different proteins and 4 ribosomal RNAs. The ribosomes of mitochondria and chloroplasts are somewhat smaller and simpler than bacterial ribosomes. Nevertheless, ribosomal structure and function are strikingly similar in all organisms and organelles.
FIGURE 27-16 Summary of the composition and mass of ribosomes in bacteria and eukaryotes. The S values associated with the subunits are not additive when subunits are combined, because S values are approximately proportional to the two-thirds power of molecular weight and are also slightly affected by shape.
In both bacteria and eukaryotes, ribosomes are assembled through a hierarchical incorporation of r-proteins as the rRNAs are synthesized. Much of the processing of pre-rRNAs occurs within large ribonucleoprotein complexes. The composition of these complexes changes as new r-proteins are added, the rRNAs acquire their final form, and some proteins required for rRNA processing dissociate. In eukaryotes, the early stages of assembly occur in the nucleolus, with the final maturation of the ribosome completed after export to the cytosol. Dozens of assembly factors, both proteins and some small RNA molecules (snoRNAs; Fig. 26-24), participate in this process (Fig. 27-17).
FIGURE 27-17 Assembly of ribosomes in eukaryotes. Most of the early steps of ribosome assembly occur in the nucleolus, an organelle inside the nucleus. Ribonucleases and specialized RNAs, including some snoRNAs, process the initial rRNA transcript. Large pre-ribosomal particles are formed and additional processing of the large complex occurs with the aid of proteins called assembly factors. The pre-40S and pre-60S complexes move into the nucleoplasm. The 40S and 60S subunits are exported to the cytoplasm, coupled with the ejection of assembly factors. Final maturation of the ribosome occurs in the cytoplasm.
Transfer RNAs Have Characteristic Structural Features
To understand how tRNAs can serve as adaptors in translating the language of nucleic acids into the language of proteins, we must first examine their structure in more detail. Transfer RNAs are relatively small and consist of a single strand of RNA folded into a precise three-dimensional structure (see Fig. 8-25a). The tRNAs of bacteria and in the cytosol of eukaryotes have between 73 and 93 nucleotide residues, corresponding to molecular weights of 24,000 to 31,000. Mitochondria and chloroplasts contain distinctive, somewhat smaller tRNAs. Cells have at least one kind of tRNA for each amino acid; at least 32 tRNAs are required to recognize all the amino acid codons (some recognize more than one codon), but some cells use more than 32.
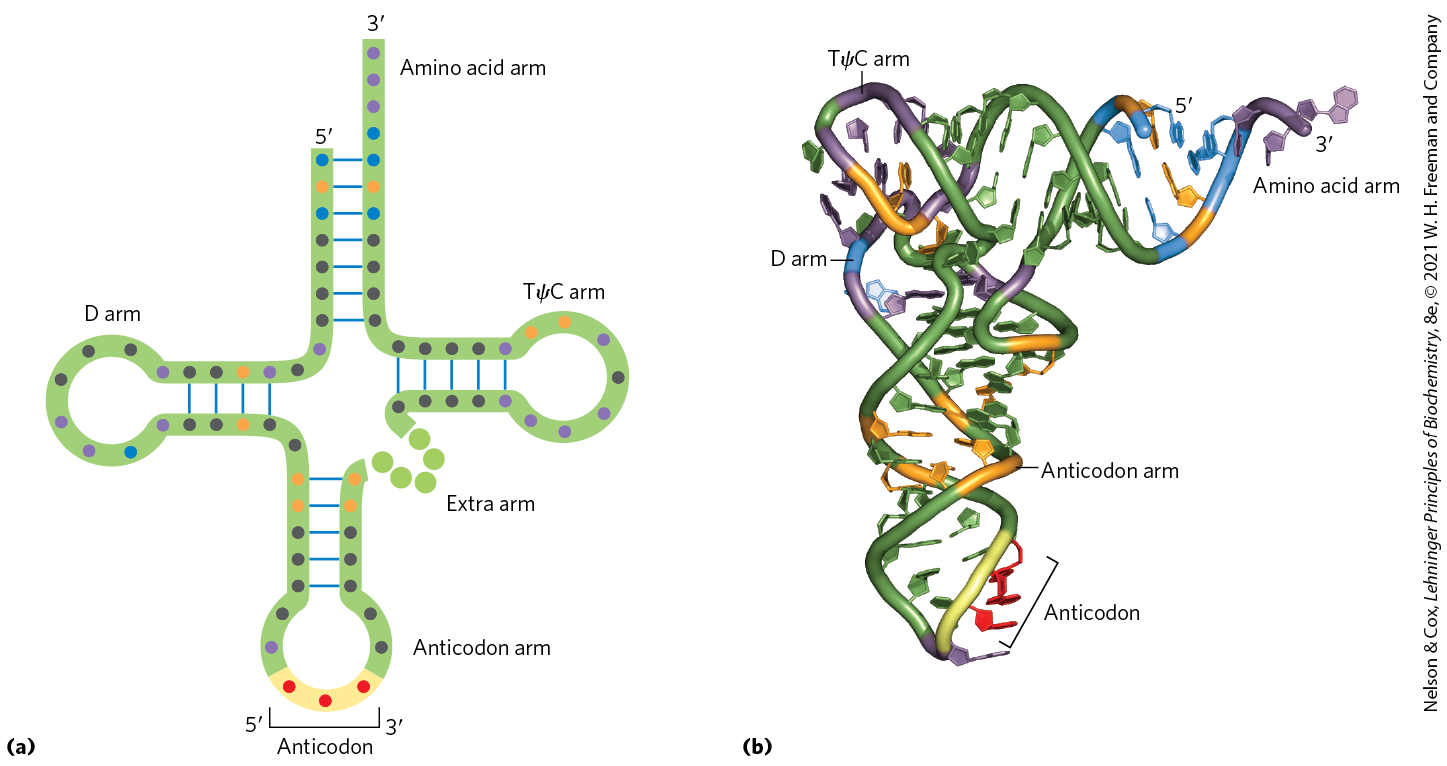
Yeast alanine tRNA was the first nucleic acid to be completely sequenced, by Robert Holley in 1965. It contains 76 nucleotide residues, 10 of which have modified bases. Comparisons of tRNAs from various species have revealed many common structural features (Fig. 27-18a). Eight or more of the nucleotide residues have modified bases and sugars, many of which are methylated derivatives of the principal bases. Most tRNAs have a guanylate (pG) residue at the end, and all have the trinucleotide sequence at the end. When drawn in two dimensions, all tRNAs have a hydrogen-bonding pattern that forms a cloverleaf structure with four arms, as first proposed by Elizabeth Keller. The longer tRNAs have a short fifth arm, or extra arm. In three dimensions, a tRNA has the form of a twisted L (Fig. 27-18b).
FIGURE 27-18 General structure of tRNAs. (a) The cloverleaf structure. The large dots on the backbone represent nucleotide residues; the blue lines represent base pairs. Characteristic and/or invariant residues common to all tRNAs are specified. Transfer RNAs vary in length from 73 to 93 nucleotides. Extra nucleotides occur in the extra arm or in the D arm. At the end of the anticodon arm is the anticodon loop, which always contains seven unpaired nucleotides. The D arm contains two or three D (5,6-dihydrouridine) residues, depending on the tRNA. In some tRNAs, the D arm has only three hydrogen-bonded base pairs. Pu represents purine nucleotide; Py, pyrimidine nucleotide; ψ, pseudouridylate; G*, guanylate or -O-methylguanylate. (b) Schematic diagram of the folded tRNA, which resembles a twisted L.
Two of the arms of a tRNA are critical for its adaptor function. The amino acid arm can carry a specific amino acid esterified by its carboxyl group to the - or -hydroxyl group of the A residue at the end of the tRNA. The anticodon arm contains the anticodon. The other major arms are the D arm, which contains the unusual nucleotide dihydrouridine (D), and the TψC arm, which contains ribothymidine (T), not usually present in RNAs, and pseudouridine (ψ), which has an unusual carbon–carbon bond between the base and ribose (see Fig. 26-22). The D and TψC arms contribute important interactions for the overall folding of tRNA molecules, and the TψC arm interacts with the large-subunit rRNA.
Having looked at the structures of ribosomes and tRNAs, we now consider in detail the five stages of protein synthesis.
Stage 1: Aminoacyl-tRNA Synthetases Attach the Correct Amino Acids to Their tRNAs
For the synthesis of a polypeptide with a defined sequence, two fundamental chemical requirements must be met: (1) the carboxyl group of each amino acid must be activated to facilitate formation of a peptide bond, and (2) a link must be established between each new amino acid and the information in the mRNA that encodes it. Both these requirements are met by attaching the amino acid to a tRNA in the first stage of protein synthesis. When attached to their amino acid (aminoacylated), the tRNAs are said to be “charged.”
This first stage of protein synthesis takes place in the cytosol. Aminoacyl-tRNA synthetases esterify the 20 amino acids to their corresponding tRNAs. Each enzyme is specific for one amino acid and one or more corresponding tRNAs. Most organisms have one aminoacyl-tRNA synthetase for each amino acid. For amino acids with two or more corresponding tRNAs, the same enzyme usually aminoacylates all of them.
In all organisms, the aminoacyl-tRNA synthetases fall into two classes (Table 27-7), based on substantial differences in primary and tertiary structure and in reaction mechanism (Fig. 27-19). There is no evidence that the two classes share a common ancestor, and the biological, chemical, or evolutionary reasons for two enzyme classes for essentially identical processes remain obscure.
TABLE 27-7 The Two Classes of Aminoacyl-tRNA Synthetases
Class I
Class II
Arg
Leu
Ala
Lys
Cys
Met
Asn
Phe
Gln
Trp
Asp
Pro
Glu
Tyr
Gly
Ser
Ile
Val
His
Thr
Note: Here, Arg represents arginyl-tRNA synthetase, and so forth. The classification applies to all organisms for which tRNA synthetases have been analyzed and is based on protein structural distinctions and on the mechanistic distinction outlined in Figure 27-19.
MECHANISM FIGURE 27-19 Aminoacylation of tRNA by aminoacyl-tRNA synthetases. Step is formation of an aminoacyl adenylate, which remains bound to the active site. In the second step, the aminoacyl group is transferred to the tRNA. The mechanism of this step is somewhat different for the two classes of aminoacyl-tRNA synthetases. For class I enzymes, the aminoacyl group is transferred first to the -hydroxyl group of the -terminal A residue, then to the -hydroxyl group by a transesterification reaction. For class II enzymes, the aminoacyl group is transferred directly to the -hydroxyl group of the terminal adenylate.
The reaction catalyzed by an aminoacyl-tRNA synthetase is
This reaction occurs in two steps in the enzyme’s active site. In step (Fig. 27-19), an enzyme-bound intermediate, aminoacyl adenylate (aminoacyl-AMP), is formed. In the second step, the aminoacyl group is transferred from enzyme-bound aminoacyl-AMP to its corresponding specific tRNA. The course of this second step depends on the class to which the enzyme belongs, as shown by pathways and in Figure 27-19. The resulting ester linkage between the amino acid and the tRNA (Fig. 27-20) has a highly negative standard free energy of hydrolysis . The pyrophosphate formed in the activation reaction undergoes hydrolysis to phosphate by inorganic pyrophosphatase. Thus, two high-energy phosphate bonds are ultimately expended for each amino acid molecule activated, rendering the overall reaction for amino acid activation essentially irreversible:
FIGURE 27-20 General structure of aminoacyl-tRNAs. The aminoacyl group is esterified to the position of the terminal A residue. The ester linkage that both activates the amino acid and joins it to the tRNA is shaded light red.
Proofreading by Aminoacyl-tRNA Synthetases
The aminoacylation of tRNA accomplishes two ends: (1) it activates an amino acid for peptide bond formation and (2) it ensures appropriate placement of the amino acid in a growing polypeptide. The identity of the amino acid attached to a tRNA is not checked on the ribosome, so attachment of the correct amino acid to the tRNA is essential to the fidelity of protein synthesis.
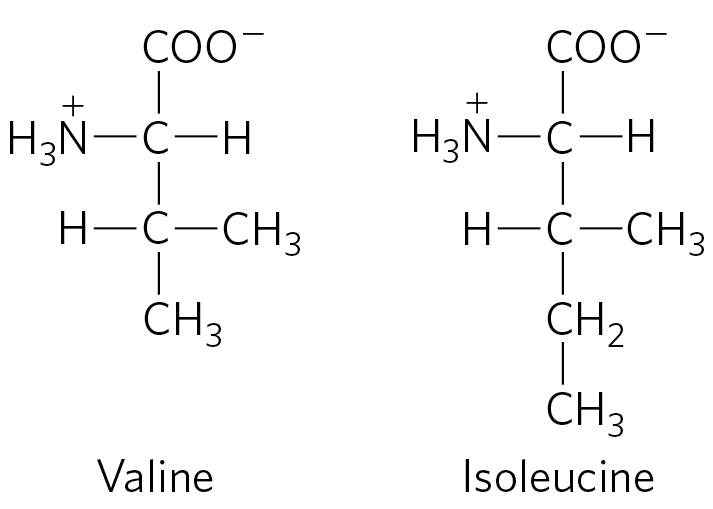
As you will recall from Chapter 6, enzyme specificity is limited by the binding energy available from enzyme-substrate interactions. Discrimination between two similar amino acid substrates has been studied in detail in the case of Ile-tRNA synthetase, which distinguishes between valine and isoleucine, amino acids that differ by only a single methylene group :
Ile-tRNA synthetase favors activation of isoleucine (to form Ile-AMP) over valine by a factor of 200 — as we would expect, given the amount by which a methylene group (in Ile) could enhance substrate binding. Yet valine is erroneously incorporated into proteins in positions normally occupied by an Ile residue at a frequency of only about 1 in 3,000. How is this greater-than-10-fold increase in accuracy brought about? Ile-tRNA synthetase, like some other aminoacyl-tRNA synthetases, has a proofreading function.
Recall a general principle from the discussion of proofreading by DNA polymerases (see Fig. 25-6): if available binding interactions do not provide sufficient discrimination between two substrates, the necessary specificity can be achieved by substrate-specific binding in two successive steps. The effect of forcing the system through two successive filters is multiplicative. In the case of Ile-tRNA synthetase, the first filter is the initial binding of the amino acid to the enzyme and its activation to aminoacyl-AMP. The second is the binding of any incorrect aminoacyl-AMP products to a separate active site on the enzyme; a substrate that binds in this second active site is hydrolyzed. The R group of valine is slightly smaller than that of isoleucine, so Val-AMP fits the hydrolytic (proofreading) site of the Ile-tRNA synthetase, but Ile-AMP does not. Thus Val-AMP is hydrolyzed to valine and AMP in the proofreading active site, and tRNA bound to the synthetase does not become aminoacylated to the wrong amino acid.
In addition to proofreading after formation of the aminoacyl-AMP intermediate, most aminoacyl-tRNA synthetases can hydrolyze the ester linkage between amino acids and tRNAs in the aminoacyl-tRNAs. This hydrolysis is greatly accelerated for incorrectly charged tRNAs, providing yet a third filter to enhance the fidelity of the overall process. The few aminoacyl-tRNA synthetases that activate amino acids with no close structural relatives (Cys-tRNA synthetase, for example) demonstrate little or no proofreading activity; in these cases, the active site for aminoacylation can sufficiently discriminate between the proper substrate and any incorrect amino acid.
The overall error rate of protein synthesis (∼1 mistake per amino acids incorporated) is not nearly as low as that of DNA replication. Because flaws in a protein are eliminated when the protein is degraded and are not passed on to future generations, they have less biological significance. The degree of fidelity in protein synthesis is sufficient to ensure that most proteins contain no mistakes and that the large amount of energy required to synthesize a protein is rarely wasted. One defective protein molecule is usually unimportant when many correct copies of the same protein are present.
A “Second Genetic Code”
An individual aminoacyl-tRNA synthetase must be specific not only for a single amino acid but for certain tRNAs as well. Discriminating among dozens of tRNAs is just as important for the overall fidelity of protein biosynthesis as is distinguishing among amino acids. The interaction between aminoacyl-tRNA synthetases and tRNAs has been referred to as the “second genetic code,” reflecting its critical role in maintaining the accuracy of protein synthesis. The “coding” rules appear to be more complex than those in the “first” code.
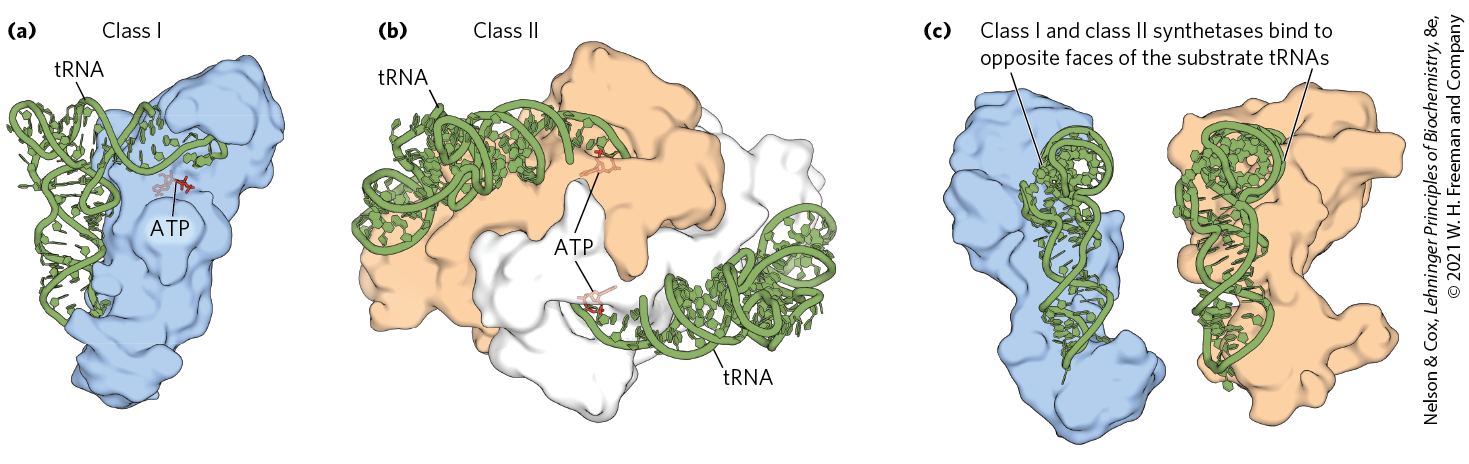
Figure 27-21 summarizes what we know about the nucleotides involved in recognition by some aminoacyl-tRNA synthetases. Some nucleotides are conserved in all tRNAs and therefore cannot be used for discrimination. Nucleotide positions necessary for discrimination by the aminoacyl-tRNA synthetases seem to be concentrated in the amino acid arm and the anticodon arm, including the nucleotides of the anticodon itself. A few are located in other parts of the tRNA molecule. Determination of the crystal structures of aminoacyl-tRNA synthetases complexed with their cognate tRNAs and ATP has added a great deal to our understanding of these interactions (Fig. 27-22).
FIGURE 27-21 Nucleotide positions in a tRNA that are recognized by aminoacyl-tRNA synthetases. (a) Some positions (purple dots) are the same in all tRNAs and therefore cannot be used to discriminate one from another. Other positions are known recognition points for one (orange) or more (blue) aminoacyl-tRNA synthetases. Structural features other than sequence are important for recognition by some of the synthetases. (b) The same structural features are shown in three dimensions, with the orange and blue residues again representing positions recognized by one or more aminoacyl-tRNA synthetases, respectively. [(b) Data from PDB ID 1EHZ, H. Shi and P. B. Moore, RNA 6:1091, 2000.]
FIGURE 27-22 Aminoacyl-tRNA synthetases. The synthetases are complexed with their cognate tRNAs (green). Bound ATP (red) pinpoints the active site near the end of the aminoacyl arm. (a) Gln-tRNA synthetase of E. coli, a typical monomeric class I synthetase. (b) Asp-tRNA synthetase of yeast, a typical dimeric class II synthetase. (c) The two classes of aminoacyl-tRNA synthetases recognize different faces of their tRNA substrates. [Data from (a, c (left)) PDB ID 1QRT, J. G. Arnez and T. A. Steitz, Biochemistry 35:14,725, 1996; (b, c (right)) PDB ID 1ASZ, J. Cavarelli et al., EMBO J. 13:327, 1994.]
Ten or more specific nucleotides may be involved in recognition of a tRNA by its specific aminoacyl-tRNA synthetase. But in a few cases the recognition mechanism is quite simple. Across a range of organisms from bacteria to humans, the primary determinant of tRNA recognition by the Ala-tRNA synthetases is a single base pair in the amino acid arm of (Fig. 27-23a). A short synthetic RNA with as few as 7 bp arranged in a simple hairpin minihelix is efficiently aminoacylated by the Ala-tRNA synthetase, as long as the RNA contains the critical (Fig. 27-23b). This relatively simple alanine system may be an evolutionary relic of a period when RNA oligonucleotides, ancestors to tRNA, were aminoacylated in a primitive system for protein synthesis.
FIGURE 27-23 Structural elements of that are required for recognition by Ala-tRNA synthetase. (a) The structural elements recognized by the Ala-tRNA synthetase are unusually simple. A single base pair (light red) is the only element needed for specific binding and aminoacylation. (b) A short synthetic RNA minihelix, with the critical base pair but lacking most of the remaining tRNA structure. This is aminoacylated specifically with alanine almost as efficiently as the complete .
The interaction of aminoacyl-tRNA synthetases and their cognate tRNAs is critical to accurate reading of the genetic code. Any expansion of the code to include new amino acids would necessarily require a new aminoacyl-tRNA synthetase–tRNA pair. A limited expansion of the genetic code has been observed in nature; a more extensive expansion has been accomplished in the laboratory (Box 27-2).
Stage 2: A Specific Amino Acid Initiates Protein Synthesis
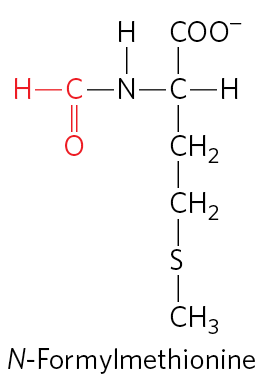
Protein synthesis begins at the amino-terminal end and proceeds by the stepwise addition of amino acids to the carboxyl-terminal end of the growing polypeptide. The AUG initiation codon thus specifies an amino-terminal methionine residue. Although methionine has only one codon, , all organisms have two tRNAs for methionine. One is used exclusively when is the initiation codon for protein synthesis. The other is used to code for a Met residue in an internal position in a polypeptide.
The distinction between an initiating and an internal one is straightforward. In bacteria, the two types of tRNA specific for methionine are designated and . The amino acid incorporated in response to the initiation codon is N-formylmethionine (fMet). It arrives at the ribosome as , which is formed in two successive reactions. First, methionine is attached to by the Met-tRNA synthetase (which in E. coli aminoacylates both and ):
Next, a transformylase transfers a formyl group from -formyltetrahydrofolate to the amino group of the Met residue:
The transformylase is more selective than the Met-tRNA synthetase; it is specific for Met residues attached to , presumably recognizing some unique structural feature of that tRNA. By contrast, inserts methionine in interior positions in polypeptides.
Addition of the N-formyl group to the amino group of methionine by the transformylase prevents fMet from entering interior positions in a polypeptide while also allowing to be bound at a specific ribosomal initiation site that accepts neither nor any other aminoacyl-tRNA.
In eukaryotic cells, all polypeptides synthesized by cytosolic ribosomes begin with a Met residue (rather than fMet), but, again, the cell uses a specialized initiating tRNA that is distinct from the used at codons at interior positions in the mRNA. Polypeptides synthesized by mitochondrial and chloroplast ribosomes, however, begin with N-formylmethionine. This strongly supports the view that mitochondria and chloroplasts originated from bacterial ancestors that were symbiotically incorporated into precursor eukaryotic cells at an early stage of evolution (see Fig. 1-37).
How can the single codon determine whether a starting N-formylmethionine (or methionine, in eukaryotes) or an interior Met residue is ultimately inserted? The details of the initiation process provide the answer.
The Three Steps of Initiation
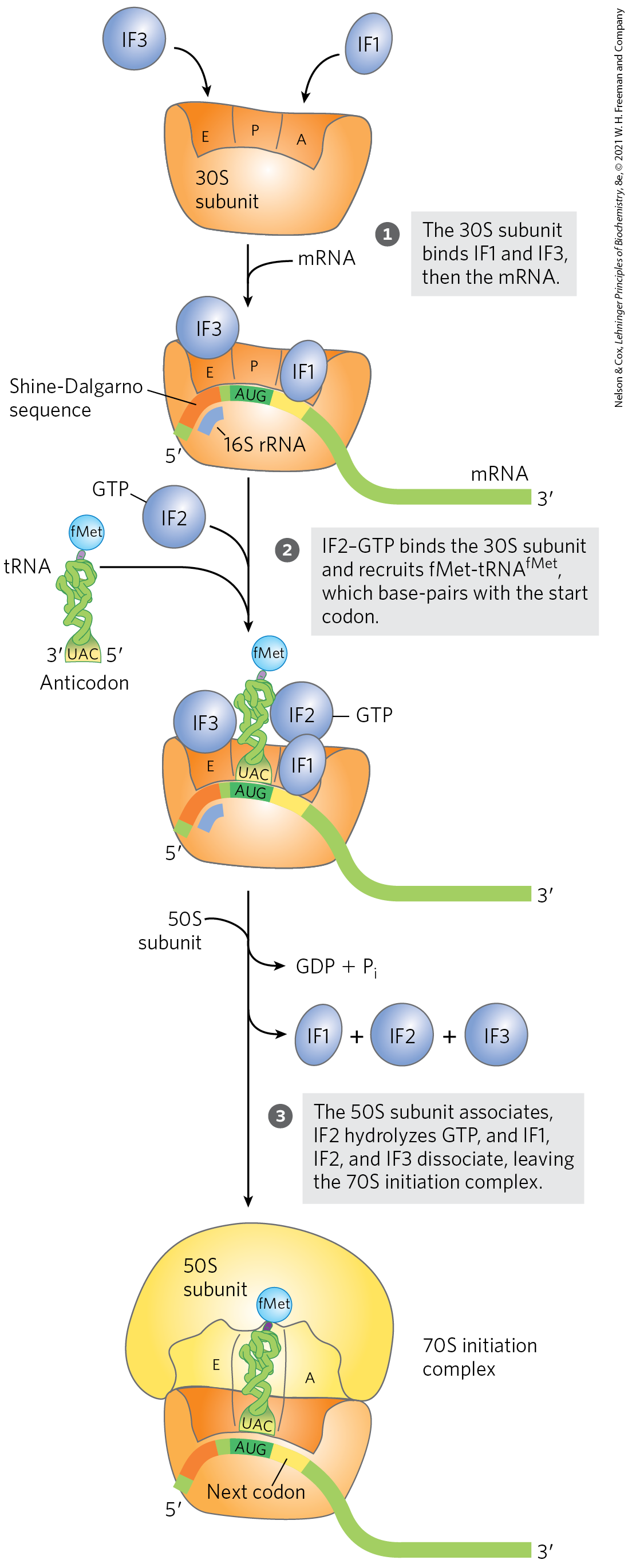
The initiation of polypeptide synthesis in bacteria requires (1) the 30S ribosomal subunit, (2) the mRNA coding for the polypeptide to be made, (3) the initiating , (4) a set of three proteins called initiation factors (IF1, IF2, and IF3), (5) GTP, (6) the 50S ribosomal subunit, and (7) . Formation of the initiation complex takes place in three steps (Fig. 27-24).
FIGURE 27-24 Formation of the initiation complex in bacteria. The complex forms in three steps (described in the text) at the expense of the hydrolysis of GTP to GDP and . IF1, IF2, and IF3 are initiation factors. E designates the exit site; P, the peptidyl site; and A, the aminoacyl site. Here the anticodon of the tRNA is oriented to , left to right, as in Figure 27-8, but opposite to the orientation in Figures 27-21 and 27-23.
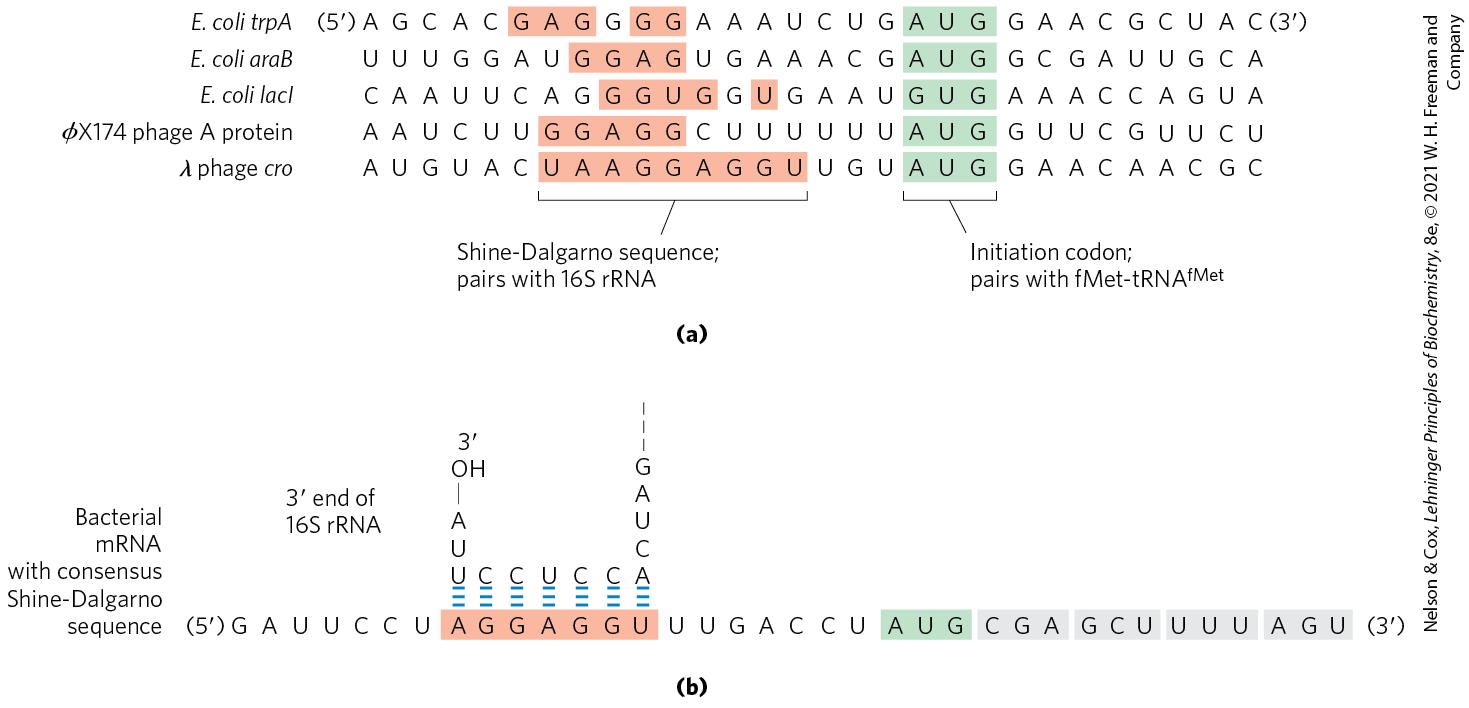
In step , the 30S ribosomal subunit binds two initiation factors, IF1 and IF3. Factor IF3 prevents the 30S and 50S subunits from combining prematurely. The mRNA then binds to the 30S subunit. The initiating is guided to its correct position by the Shine-Dalgarno sequence (named for Australian researchers John Shine and Lynn Dalgarno, who identified it) in the mRNA. This consensus sequence is an initiation signal of four to nine purine residues, 8 to 13 bp to the side of the initiation codon (Fig. 27-25a). The sequence base-pairs with a complementary pyrimidine-rich sequence near the end of the 16S rRNA of the 30S ribosomal subunit (Fig. 27-25b). This mRNA-rRNA interaction positions the initiating sequence of the mRNA in the precise position on the 30S subunit where it is required for initiation of translation. The particular where is to be bound is distinguished from other methionine codons by its proximity to the Shine-Dalgarno sequence in the mRNA.
FIGURE 27-25 Messenger RNA sequences that serve as signals for initiation of protein synthesis in bacteria. (a) Alignment of the initiating AUG (shaded in green) at its correct location on the 30S ribosomal subunit depends in part on upstream Shine-Dalgarno sequences (light red). Portions of the mRNA transcripts of five bacterial genes are shown. Note the unusual example of the E. coli LacI protein, which initiates with a GUG (Val) codon. In E. coli, AUG is the start codon in approximately 91% of genes, with GUG (7%) and UUG (2%) assuming this role more rarely. (b) The Shine-Dalgarno sequence of the mRNA pairs with a sequence near the end of the 16S rRNA.
Bacterial ribosomes have three sites that bind tRNAs, the aminoacyl (A) site, the peptidyl (P) site, and the exit (E) site. The A and P sites bind aminoacyl-tRNAs, whereas the E site binds only uncharged tRNAs that have completed their task on the ribosome. Factor IF1 binds at the A site and prevents tRNA binding at this site during initiation. The initiating is positioned at the P site, the only site to which can bind (Fig. 27-24). The is the only aminoacyl-tRNA that binds first to the P site; during the subsequent elongation stage, all other incoming aminoacyl-tRNAs (including the that binds to interior AUG codons) bind first to the A site and only subsequently to the P and E sites. The E site is the site from which the “uncharged” tRNAs leave during elongation. Both the 30S and the 50S subunits contribute to the characteristics of the A and P sites, whereas the E site is largely confined to the 50S subunit.
In step of the initiation process (Fig. 27-24), the complex consisting of the 30S ribosomal subunit, IF3, and mRNA is joined by both GTP-bound IF2 and the initiating . The anticodon of this tRNA now pairs correctly with the mRNA’s initiation codon.
In step , this large complex combines with the 50S ribosomal subunit; simultaneously, the GTP bound to IF2 is hydrolyzed to GDP and , which are released from the complex. All three initiation factors leave the ribosome at this point.
Completion of the steps in Figure 27-24 produces a functional 70S ribosome called the initiation complex, containing the mRNA and the initiating . The correct binding of the to the P site in the complete 70S initiation complex is ensured by at least three points of recognition and attachment: the codon-anticodon interaction involving the initiation AUG fixed in the P site, the interaction between the Shine-Dalgarno sequence in the mRNA and the 16S rRNA, and the binding interactions between the ribosomal P site and the . The initiation complex is now ready for elongation.
Initiation in Eukaryotic Cells
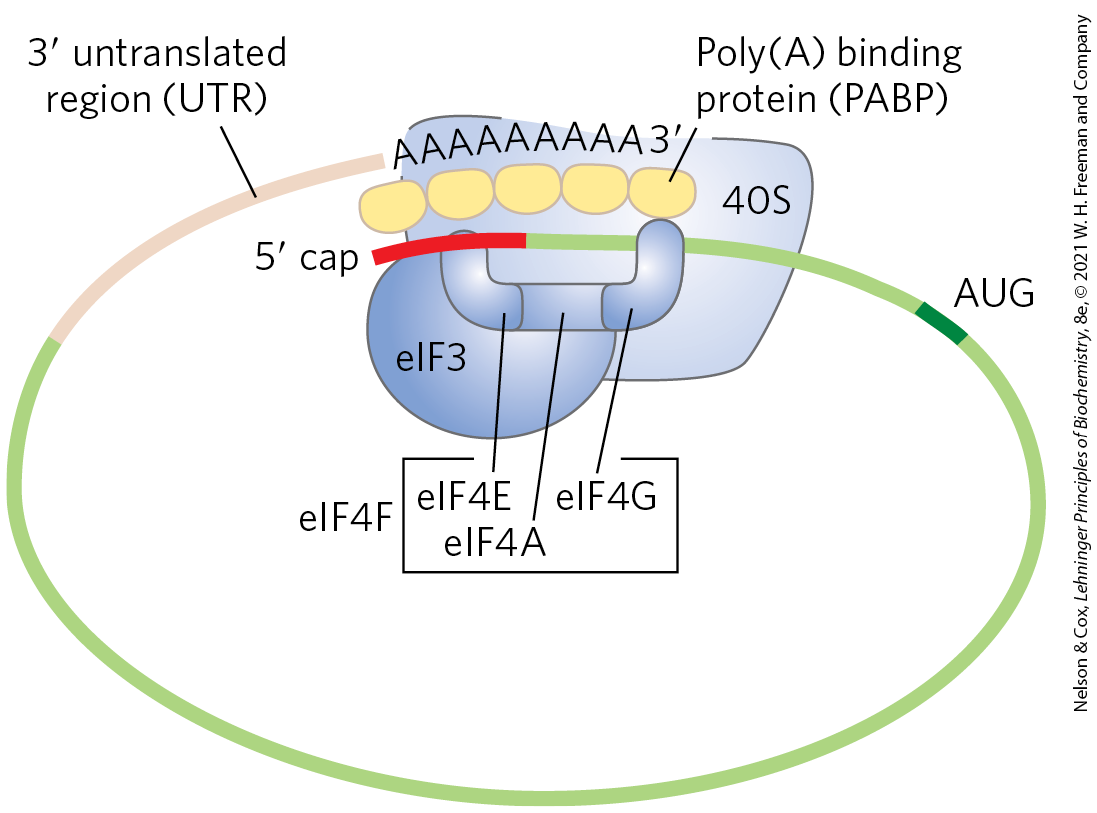
Translation is generally similar in eukaryotic and bacterial cells; most of the significant differences are in the number of components and the mechanistic details. The initiation process in eukaryotes is outlined in Figure 27-26. Eukaryotic mRNAs are bound to the ribosome as a complex with a number of specific binding proteins. Eukaryotic cells have at least 12 initiation factors. Initiation factors eIF1A and eIF3 are the functional homologs of the bacterial IF1 and IF3, binding to the 40S subunit in step , blocking tRNA binding to the A site and premature joining of the large and small ribosomal subunits, respectively. The factor eIF1 binds to the E site. The charged initiator tRNA is bound by the initiation factor eIF2, which also has bound GTP. In step , this ternary complex binds to the 40S ribosomal subunit, along with two other proteins involved in later steps, eIF5 (not shown in Fig. 27-26) and eIF5B. This creates a 43S preinitiation complex. The mRNA binds to the eIF4F complex, which, in step , mediates its association with the 43S preinitiation complex. The eIF4F complex is made up of eIF4E (binding to the cap), eIF4A (an ATPase and RNA helicase), and eIF4G (a linker protein). The eIF4G protein binds to eIF3 and eIF4E to provide the first link between the 43S preinitiation complex and the mRNA. The eIF4G also binds to the poly(A) binding protein (PABP) at the end of the mRNA, circularizing the mRNA (Fig. 27-27) and facilitating the translational regulation of gene expression, as described in Chapter 28.
FIGURE 27-26 Initiation of protein synthesis in eukaryotes. The five steps are described in the text. Eukaryotic initiation factors mediate the association of, first, the charged initiator tRNA to form a 43S preinitiation complex, and then the mRNA (with the cap shown in red) to form a 48S complex. The final 80S initiation complex is formed as the 60S subunit associates, coupled with release of most of the initiation factors.
FIGURE 27-27 Circularization of mRNA in the eukaryotic initiation complex. The and ends of eukaryotic mRNAs are linked by the eIF4F complex of proteins. The eIF4E subunit binds to the cap, and the eIF4G protein binds to the poly(A) binding protein (PABP) at the end of the mRNA. The eIF4G protein also binds to eIF3, linking the circularized mRNA to the 40S subunit of the ribosome.
Addition of the mRNA and its associated factors creates a 48S complex. This complex scans the bound mRNA, starting at the cap, until an AUG codon is encountered. The scanning process (step in Fig. 27-26) may be facilitated by the RNA helicase of eIF4A, which unwinds RNA secondary structures while in a transient complex with another factor, eIF4B (not shown in Fig. 27-26).
Once the initiating AUG site is encountered, the 60S ribosomal subunit associates with the complex in step , which is accompanied by release of many of the initiation factors. This requires the activity of eIF5 and eIF5B. The eIF5 protein promotes the GTPase activity of eIF2, producing an eIF2-GDP complex with reduced affinity for the initiator tRNA. The eIF5B protein is homologous to the bacterial IF2. It hydrolyzes its bound GTP and triggers dissociation of eIF2-GDP and other initiation factors, followed closely by association of the 60S subunit. This completes formation of the initiation complex.
The roles of the various bacterial and eukaryotic initiation factors in the overall process are summarized in Table 27-8. The mechanism by which these proteins act is an important area of investigation.
TABLE 27-8 Protein Factors Required for Initiation of Translation in Bacterial and Eukaryotic Cells
Factor
Function
Bacterial
IF1
Prevents premature binding of tRNAs to A site
IF2
Facilitates binding of to 30S ribosomal subunit
IF3
Binds to 30S subunit; prevents premature association of 50S subunit; enhances specificity of P site for
Eukaryotic
eIF1
Binds to the E site of the 40S subunit; facilitates interaction between elF2-tRNA-GTP ternary complex and the 40S subunit
elF1A
Homolog of bacterial IF1; prevents premature binding of tRNAs to A site
eIF2
GTPase; facilitates binding of initiating to 40S ribosomal subunit
Stage 3: Peptide Bonds Are Formed in the Elongation Stage
The third stage of protein synthesis is elongation. Again, we begin with bacterial cells. Elongation requires (1) the initiation complex described above, (2) aminoacyl-tRNAs, (3) a set of three soluble cytosolic proteins called elongation factors (EF-Tu, EF-Ts, and EF-G in bacteria), and (4) GTP. Cells use three steps to add each amino acid residue, and the steps are repeated as many times as there are residues to be added.
Elongation Step 1: Binding of an Incoming Aminoacyl-tRNA
In the first step of the elongation cycle (Fig. 27-28), the appropriate incoming aminoacyl-tRNA binds to a complex of GTP-bound EF-Tu. The resulting aminoacyl-tRNA–EF-Tu–GTP complex binds to the A site of the 70S initiation complex. The GTP is hydrolyzed and an EF-Tu–GDP complex is released from the 70S ribosome. The bound GDP is released when the EF-Tu–GDP complex binds to EF-Ts, and EF-Ts is subsequently released when another molecule of GTP binds to EF-Tu, recycling it.
FIGURE 27-28 First elongation step in bacteria: binding of the second aminoacyl-tRNA. The second aminoacyl-tRNA enters the A site of the ribosome bound to GTP-bound EF-Tu (shown here as Tu). Binding of the second aminoacyl-tRNA to the A site is accompanied by hydrolysis of the GTP to GDP and and release of the EF-Tu–GDP complex from the ribosome. The EF-Tu–GTP complex is regenerated in a process requiring EF-Ts and GTP. “Accommodation” involves a change in the conformation of the second tRNA that pulls its aminoacyl end into the peptidyl transferase site.
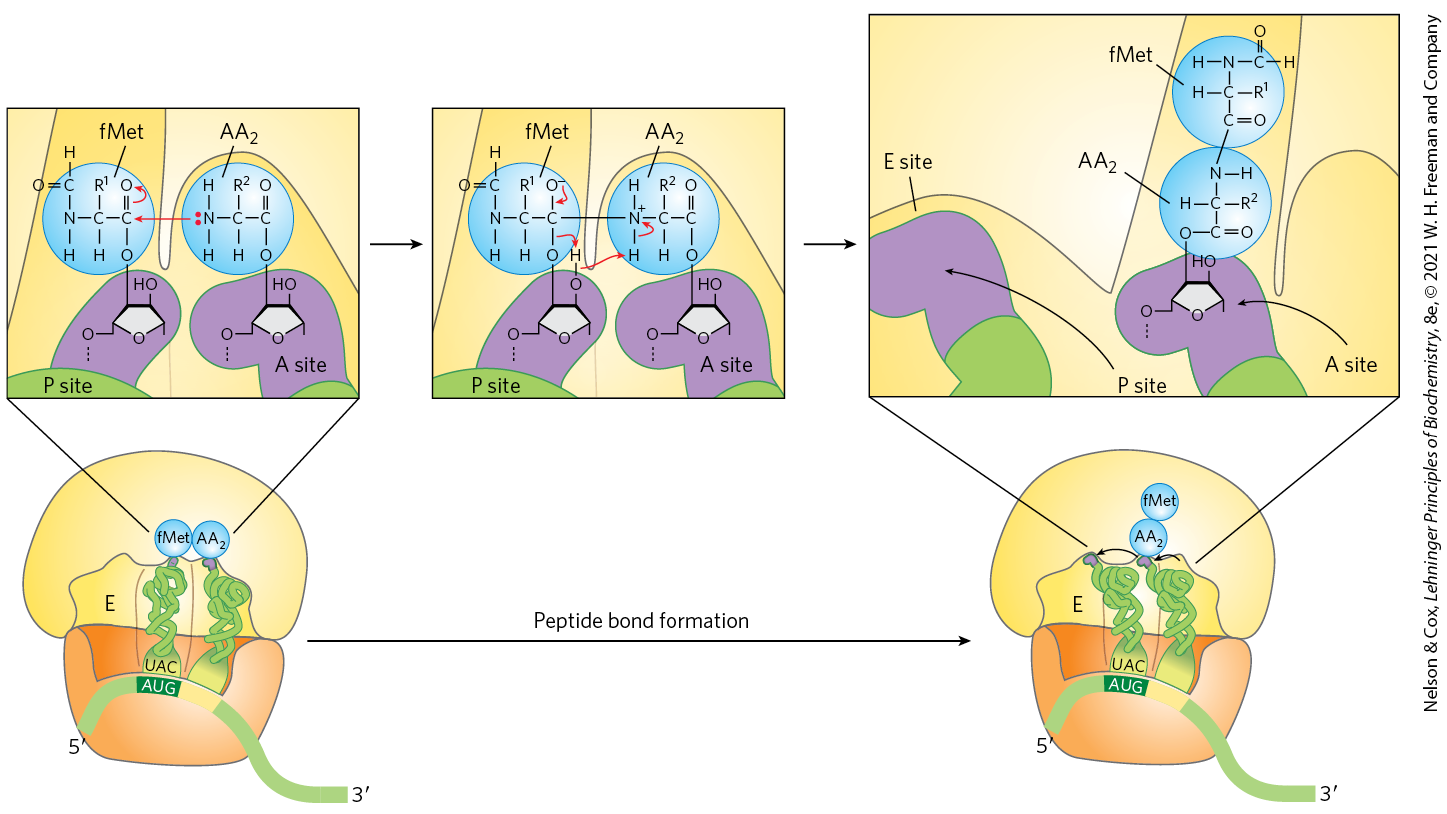
Elongation Step 2: Peptide Bond Formation
A peptide bond is now formed between the two amino acids bound by their tRNAs to the A and P sites on the ribosome. This occurs by transfer of the initiating N-formylmethionyl group from its tRNA to the amino group of the second amino acid, now in the A site (Fig. 27-29). The α-amino group of the amino acid in the A site acts as a nucleophile, displacing the tRNA in the P site to form a peptide bond. The constrained structure of the proline side chain interferes with the alignment needed for peptide bonds to form properly. A special system binds to the ribosome to facilitate peptide bonds between two proline residues whenever that is necessary (Box 27-3). The reaction produces a dipeptidyl-tRNA in the A site, and the now “uncharged” (deacylated) remains bound to the P site. The tRNAs then shift to a hybrid binding state, with elements of each spanning two different sites on the ribosome, as shown in Figure 27-29.
FIGURE 27-29 Second elongation step in bacteria: formation of the first peptide bond. The N-formylmethionyl group is transferred to the amino group of the second aminoacyl-tRNA in the A site, forming a dipeptidyl-tRNA. At this stage, both tRNAs bound to the ribosome shift position in the 50S subunit to take up a hybrid binding state. The uncharged tRNA shifts so that its and ends are in the E site. Similarly, the and ends of the peptidyl-tRNA shift to the P site. The anticodons remain in the P and A sites. Note the involvement of the -hydroxyl group of the -terminal adenosine as a general acid-base catalyst in this reaction.
The peptidyl transferase activity that catalyzes peptide bond formation resides in the 23S rRNA rather than in any of the protein components of ribosomes. The ribosomal 23S rRNA catalyzes the reaction by binding and aligning the tRNAs in the A and P sites in the proper orientations for reaction. A highly conserved active site adenosine residue in the 23S rRNA (A2451 in E. coli) may facilitate the reaction by general base catalysis and transition state stabilization utilizing N-3 in the purine ring and/or the -hydroxyl group. This addition to the known catalytic repertoire of ribozymes has interesting implications for the evolution of life (see Section 26.4).
Elongation Step 3: Translocation
In the final step of the elongation cycle, translocation, the ribosome moves one codon toward the end of the mRNA (Fig. 27-30a). This movement shifts the anticodon of the dipeptidyl-tRNA, which is still attached to the second codon of the mRNA, from the A site to the P site, and shifts the deacylated tRNA from the P site to the E site, from where the tRNA is released into the cytosol. The third codon of the mRNA now lies in the A site and the second codon lies in the P site. Movement of the ribosome along the mRNA requires EF-G (also known as translocase) and the energy provided by hydrolysis of another molecule of GTP. Because the structure of EF-G mimics the structure of the EF-Tu–tRNA complex (Fig. 27-30b), EF-G can bind the A site and, presumably, displace the peptidyl-tRNA.
FIGURE 27-30 Third elongation step in bacteria: translocation. (a) The ribosome moves one codon toward the end of the mRNA, using energy provided by hydrolysis of GTP bound to EF-G (translocase). The dipeptidyl-tRNA is now entirely in the P site, leaving the A site open for an incoming (third) aminoacyl-tRNA. The uncharged tRNA later dissociates from the E site, and the elongation cycle begins again. (b) The structure of EF-G (left) mimics the structure of EF-Tu complexed with tRNA (right). The carboxyl-terminal part of EF-G mimics the structure of the anticodon loop of tRNA in both shape and charge distribution. [(b) Data from (left) PDB ID 1DAR, S. al-Karadaghi et al., Structure 4:555, 1996; (right) PDB ID 1B23, P. Nissen et al., Structure 7:143, 1999.]
After translocation, the ribosome, with its attached dipeptidyl-tRNA and mRNA, is ready for the next elongation cycle and attachment of a third amino acid residue. This process occurs in the same way as addition of the second residue (as shown in Figs. 27-28, 27-29, and 27-30). For each amino acid residue correctly added to the growing polypeptide, two GTPs are hydrolyzed to GDP and as the ribosome moves from codon to codon along the mRNA toward the end.
The polypeptide remains attached to the tRNA of the most recent amino acid to be inserted. This association maintains the functional connection between the information in the mRNA and its decoded polypeptide output. At the same time, the ester linkage between this tRNA and the carboxyl terminus of the growing polypeptide activates the terminal carboxyl group for nucleophilic attack by the incoming amino acid to form a new peptide bond (Fig. 27-29). As the existing ester linkage between the polypeptide and tRNA is broken during peptide bond formation, the linkage between the polypeptide and the information in the mRNA persists, because each newly added amino acid is still attached to its tRNA.
The elongation cycle in eukaryotes is similar to that in bacteria. Three eukaryotic elongation factors (eEF1α, eEF1βγ, and eEF2) have functions analogous to those of the bacterial elongation factors (EF-Tu, EF-Ts, and EF-G, respectively). When a new aminoacyl-tRNA binds to the A site, an allosteric interaction leads to ejection of the uncharged tRNA from the E site.
Proofreading on the Ribosome
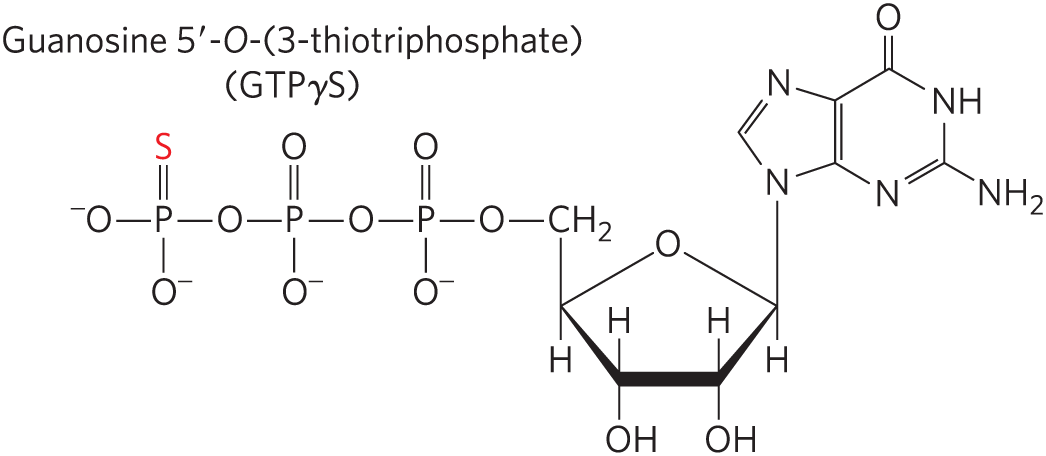
The GTPase activity of EF-Tu during the first step of elongation in bacterial cells (Fig. 27-28) makes an important contribution to the rate and fidelity of the overall biosynthetic process. Both the EF-Tu–GTP and EF-Tu–GDP complexes exist for a few milliseconds before they dissociate. These two intervals provide opportunities for the codon-anticodon interactions to be proofread. Incorrect aminoacyl-tRNAs normally dissociate from the A site during one of these periods. If the GTP analog guanosine -O-(3-thiotriphosphate) (GTPγS) is used in place of GTP, hydrolysis is slowed, improving the fidelity (by increasing the proofreading intervals) but reducing the rate of protein synthesis.
The process of protein synthesis (including the characteristics of codon-anticodon pairing already described) has clearly been optimized through evolution to balance the requirements for speed and fidelity. Improved fidelity might diminish speed, whereas increases in speed would probably compromise fidelity. And, recall that the proofreading mechanism on the ribosome establishes only that the proper codon-anticodon pairing has taken place, not that the correct amino acid is attached to the tRNA. If a tRNA is successfully aminoacylated with the wrong amino acid (as can be done experimentally), this incorrect amino acid is efficiently incorporated into a protein in response to whatever codon is normally recognized by the tRNA.
Stage 4: Termination of Polypeptide Synthesis Requires a Special Signal
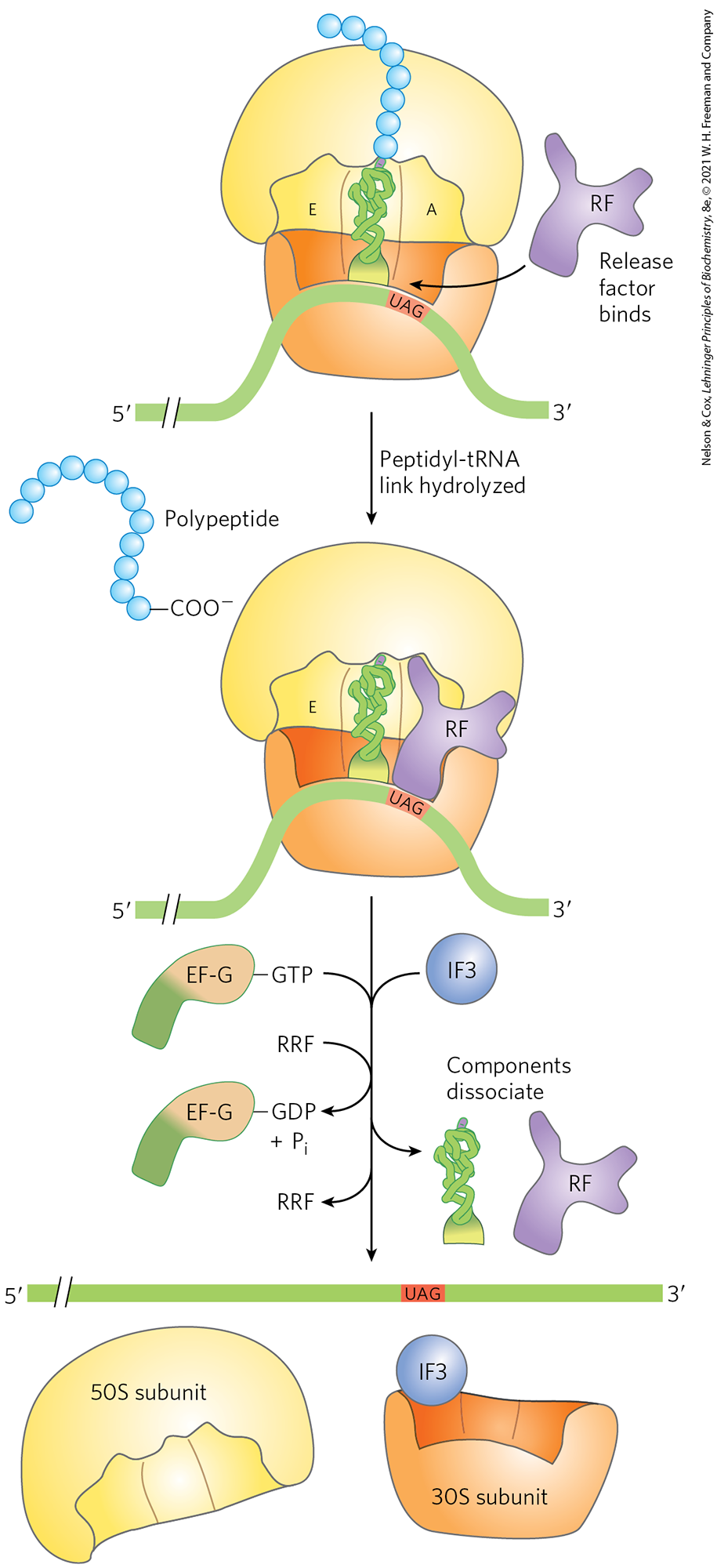
Elongation continues until the ribosome adds the last amino acid coded by the mRNA. Termination, the fourth stage of polypeptide synthesis, is signaled by the presence of one of three termination codons in the mRNA (UAA, UAG, UGA), immediately following the final coded amino acid. Mutations in a tRNA anticodon that allow an amino acid to be inserted at a termination codon are generally deleterious to the cell. In bacteria, once a termination codon occupies the ribosomal A site, three termination factors, or release factors — the proteins RF1, RF2, and RF3 — contribute to (1) hydrolysis of the terminal peptidyl-tRNA bond; (2) release of the free polypeptide and the last tRNA, now uncharged, from the P site; and (3) dissociation of the 70S ribosome into its 30S and 50S subunits, ready to start a new cycle of polypeptide synthesis (Fig. 27-31). RF1 recognizes the termination codons UAG and UAA, and RF2 recognizes UGA and UAA. Either RF1 or RF2 (depending on which codon is present) binds at a termination codon and induces peptidyl transferase to transfer the growing polypeptide to a water molecule rather than to another amino acid. The release factors have domains thought to mimic the structure of tRNA, as shown for the elongation factor EF-G in Figure 27-30b. The specific function of RF3 has not been firmly established, although it is thought to release the ribosomal subunit. In eukaryotes, a single release factor, eRF, recognizes all three termination codons.
FIGURE 27-31 Termination of protein synthesis in bacteria. Synthesis is terminated in response to a termination codon in the A site. First, a release factor, RF (RF1 or RF2, depending on which termination codon is present), binds to the A site. This leads to hydrolysis of the ester linkage between the nascent polypeptide and the tRNA in the P site and release of the completed polypeptide. Finally, the mRNA, deacylated tRNA, and release factor leave the ribosome, which dissociates into its 30S and 50S subunits, aided by ribosome recycling factor (RRF), IF3, and energy provided by EF-G–mediated GTP hydrolysis. The 30S subunit complex with IF3 is ready to begin another cycle of translation.
Dissociation of the translation components leads to ribosome recycling. The release factors dissociate from the posttermination complex (with an uncharged tRNA in the P site) and are replaced by EF-G and a protein called ribosome recycling factor (RRF; ). Hydrolysis of GTP by EF-G leads to dissociation of the 50S subunit from the 30S–tRNA–mRNA complex. EF-G and RRF are replaced by IF3, which promotes dissociation of the tRNA. The mRNA is then released. The complex of IF3 and the 30S subunit is then ready to initiate another round of protein synthesis (Fig. 27-24).
Energy Cost of Fidelity in Protein Synthesis
Synthesis of a protein true to the information specified in its mRNA requires energy well beyond what would be required to synthesize peptide bonds linking a random sequence of amino acids. Formation of each aminoacyl-tRNA uses two high-energy phosphate groups. An additional ATP is consumed each time an incorrectly activated amino acid is hydrolyzed by the deacylation activity of an aminoacyl-tRNA synthetase as part of its proofreading activity. A GTP is cleaved to GDP and during the first elongation step, and another during the translocation step. Thus, on average, the energy derived from the hydrolysis of more than four NTPs to NDPs is required for the formation of each peptide bond of a polypeptide.
This represents an exceedingly large thermodynamic “push” in the direction of synthesis: at least of phosphodiester bond energy to generate a peptide bond, which has a standard free energy of hydrolysis of only about −21 kJ/mol. The net free-energy change during peptide bond synthesis is thus −101 kJ/mol. Proteins are information-containing polymers. The biochemical goal is not simply the formation of a peptide bond but the formation of a peptide bond between two specified amino acids. Each of the high-energy phosphate compounds expended in this process plays a critical role in maintaining proper alignment between each new codon in the mRNA and its associated amino acid at the growing end of the polypeptide. This energy permits very high fidelity in the biological translation of the genetic message of mRNA into the amino acid sequence of proteins.
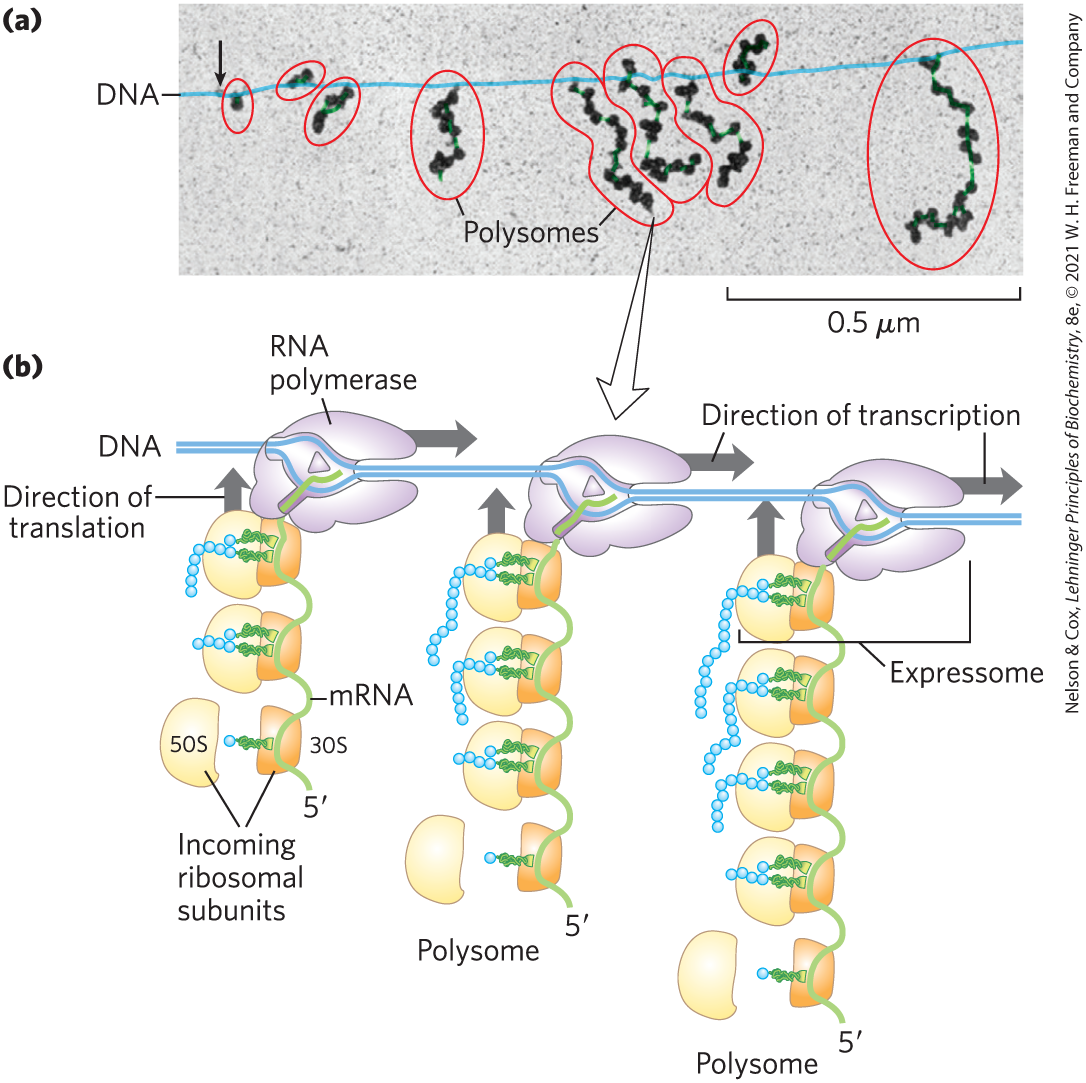
Rapid Translation of a Single Message by Polysomes
Large clusters of 10 to 100 ribosomes that are very active in protein synthesis can be isolated from both eukaryotic and bacterial cells. Electron micrographs show a fiber between adjacent ribosomes in the cluster, which is called a polysome (Fig. 27-32a). The connecting strand is a single molecule of mRNA that is being translated simultaneously by many closely spaced ribosomes, allowing the highly efficient use of the mRNA.
In bacteria, transcription and translation are tightly coupled. Messenger RNAs are synthesized and translated in the same direction. As soon as the end of the mRNA appears, ribosomes and the RNA polymerase form a complex, the expressome, beginning translation long before transcription is complete (Fig. 27-32b). As the end of the mRNA exits one ribosome, additional ribosomes are loaded in succession to form a polysome. The situation is quite different in eukaryotic cells, where newly transcribed mRNAs must leave the nucleus before they can be translated (see Fig. 27-17).
Bacterial mRNAs generally exist for just a few minutes (p. 986) before they are degraded by nucleases. To maintain high rates of protein synthesis, the mRNA for a given protein or set of proteins must be made continuously and translated with maximum efficiency. The short lifetime of mRNAs in bacteria allows a rapid cessation of synthesis when the protein is no longer needed.
Stage 5: Newly Synthesized Polypeptide Chains Undergo Folding and Processing
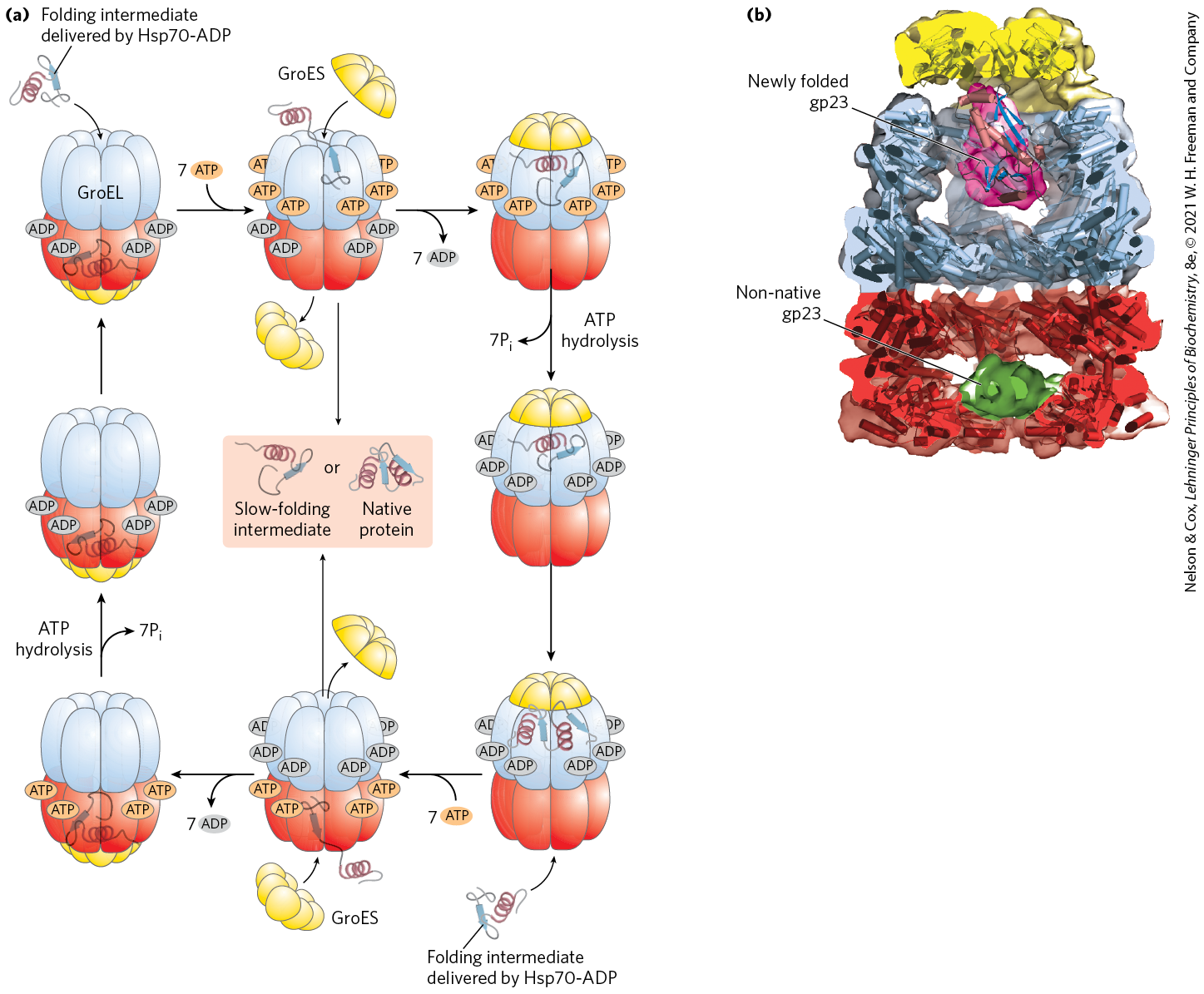
In the final stage of protein synthesis, the nascent polypeptide chain is folded and processed into its biologically active form. During or after its synthesis, the polypeptide progressively assumes its native conformation. As introduced in Chapter 4, protein chaperones, chaperonins, and specific enzymes (e.g., protein disulfide isomerase and peptide prolyl cis-trans isomerase) play an important role in the correct folding of many proteins in all cells. Chaperones and chaperonins, exemplified by GroEL/GroES in bacteria (Fig. 27-33) and Hsp60 in eukaryotes, assist folding in part by restricting formation of unproductive aggregates and limiting the conformational space that a polypeptide may explore as it folds. ATP is hydrolyzed as part of this process. The GroEL/GroES system is required for the folding of about 10%–15% of the proteins in E. coli.
FIGURE 27-33 Chaperonins in protein folding. (a) A proposed pathway for the action of the E. coli chaperonins GroEL (a member of the Hsp60 protein family) and GroES. Each GroEL complex consists of two large chambers formed by two heptameric rings (each subunit ). GroES, also a heptamer (subunit ), blocks one of the GroEL chambers after an unfolded protein is bound inside. The chamber with the unfolded protein is referred to as cis; the opposite one is trans. Folding occurs within the cis chamber, during the time it takes to hydrolyze the seven ATP that are bound to the subunits in the heptameric ring. The GroES and the ADP molecules then dissociate, and the protein is released. The two chambers of the GroEL/Hsp60 systems alternate in the binding and facilitated folding of client proteins. (b) A cutaway image of the GroEL/GroES complex. The α-helical secondary structure is represented as cylinders within a transparent surface structure. A folded protein (gp23) is shown within the large interior space of the upper chamber; an unfolded version of gp23 is shown in the lower chamber. [(a) Information from F. U. Hartl et al., Nature 475:324, 2011, Fig. 3. (b) Data from EMDB-1548, D. K. Clare et al., Nature 457:107, 2009; PDB ID 2CGT, D. K. Clare et al., J. Mol. Biol. 358:905, 2006; PDB ID 1YUE, A. Fokine et al., Proc. Natl. Acad. Sci. USA 102:7163, 2005.]
Some newly made proteins, bacterial, archaeal, and eukaryotic, do not attain their final biologically active conformation until they have been altered by one or more posttranslational modifications. Protein modifications of one type or another have been described in almost every chapter of this text, and some prominent examples are summarized here.
Amino-Terminal and Carboxyl-Terminal Modifications
The first residue inserted in all polypeptides is N-formylmethionine (in bacteria) or methionine (in eukaryotes). However, the formyl group, the amino-terminal Met residue, and often additional amino-terminal (and, in some cases, carboxyl-terminal) residues may be removed enzymatically in formation of the final functional protein. In as many as 50% of eukaryotic proteins, the amino group of the amino-terminal residue is N-acetylated after translation. Carboxyl-terminal residues are also sometimes modified.
Loss of Signal Sequences
As we shall see in Section 27.3, the 15 to 30 residues at the amino-terminal end of some proteins play a role in directing the protein to its ultimate destination in the cell. Such signal sequences are eventually removed by specific peptidases.
Modification of Individual Amino Acid Residues
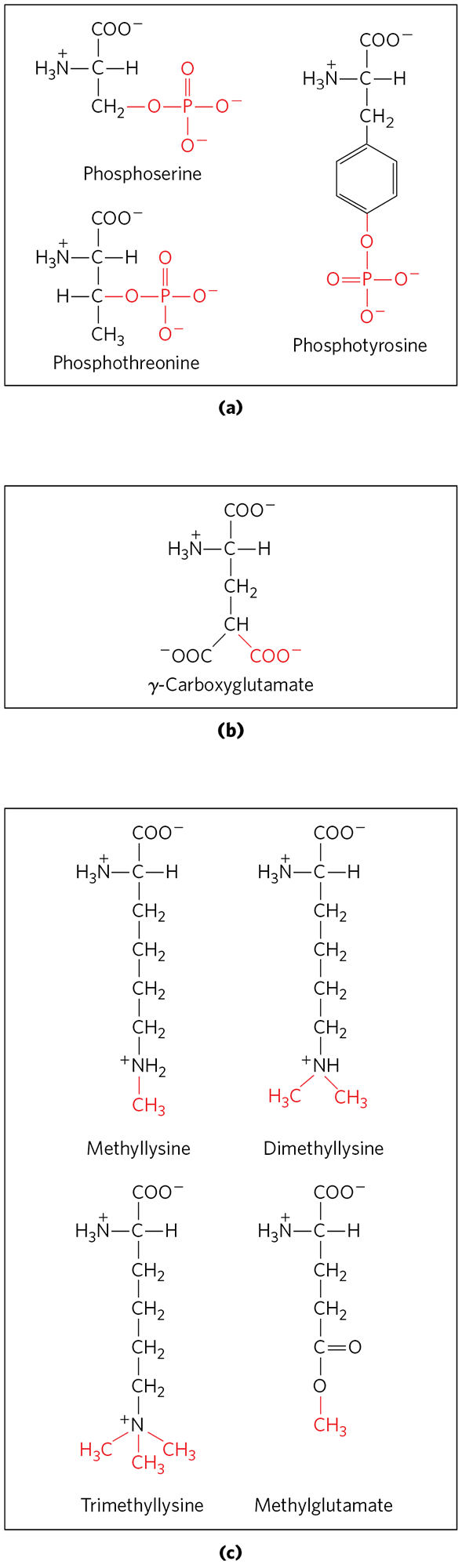
The hydroxyl groups of certain Ser, Thr, and Tyr residues of some proteins are enzymatically phosphorylated by ATP (Fig. 27-34a); the phosphate groups add negative charges to these polypeptides. The functional significance of this modification varies from one protein to the next. For example, the milk protein casein has many phosphoserine groups that bind . Calcium, phosphate, and amino acids are all valuable to suckling young, so casein efficiently provides three essential nutrients. And as we have seen in numerous instances, phosphorylation-dephosphorylation cycles regulate the activity of many enzymes and regulatory proteins.
FIGURE 27-34 Some modified amino acid residues. (a) Phosphorylated amino acids. (b) A carboxylated amino acid. (c) Some methylated amino acids.
Extra carboxyl groups may be added to Glu residues of some proteins. For example, the blood-clotting protein prothrombin contains γ-carboxyglutamate residues (Fig. 27-34b) in its amino-terminal region; the γ-carboxyl groups are introduced by an enzyme that requires vitamin K. These carboxyl groups bind , which is required to initiate the clotting mechanism.
Monomethyl- and dimethyllysine residues (Fig. 27-34c) occur in some muscle proteins and in cytochrome c. The calmodulin of most species contains one trimethyllysine residue at a specific position. In other proteins, the carboxyl groups of some Glu residues undergo methylation, removing their negative charge.
Attachment of Carbohydrate Side Chains
The carbohydrate side chains of glycoproteins are attached covalently during or after synthesis of the polypeptide. In some glycoproteins, the carbohydrate side chain is attached enzymatically to Asn residues (N-linked oligosaccharides), in others to Ser or Thr residues (O-linked oligosaccharides; see Fig. 7-27). Many proteins that function extracellularly, as well as the lubricating proteoglycans that coat mucous membranes, contain oligosaccharide side chains (see Fig. 7-25).
Addition of Isoprenyl Groups
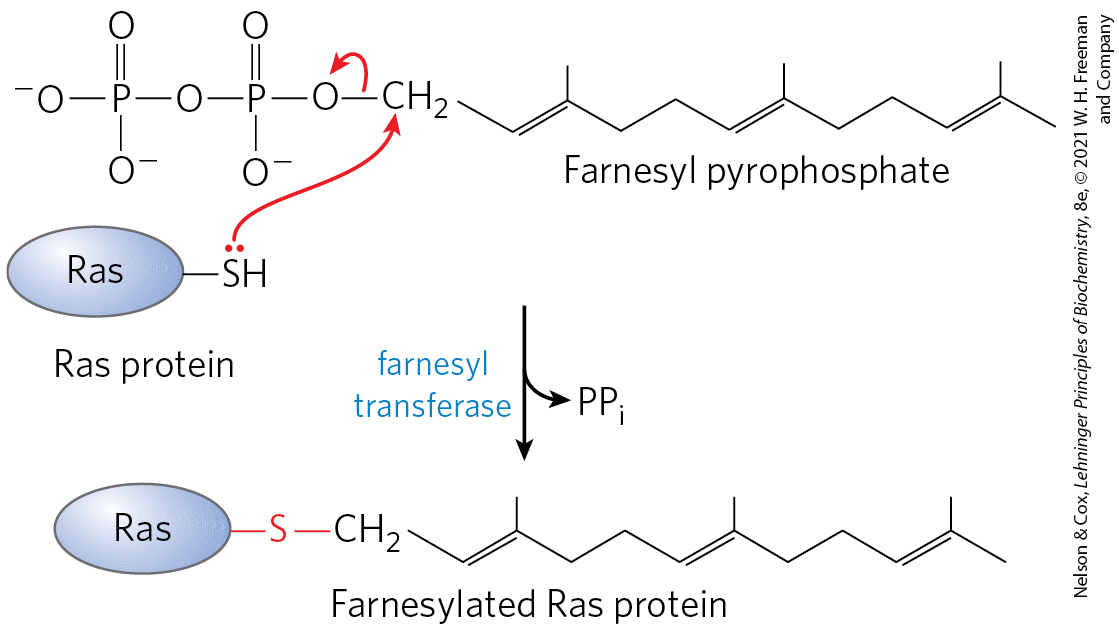
Some eukaryotic proteins are modified by the addition of groups derived from isoprene (isoprenyl groups). A thioether bond is formed between the isoprenyl group and a Cys residue of the protein (see Fig. 11-16). The isoprenyl groups are derived from pyrophosphorylated intermediates of the cholesterol biosynthetic pathway (see Fig. 21-36), such as farnesyl pyrophosphate (Fig. 27-35). Proteins modified in this way include the Ras proteins (small G proteins), which are products of the ras oncogenes and proto-oncogenes, and the trimeric G proteins (both discussed in Chapter 12), as well as lamins, proteins found in the nuclear matrix. The isoprenyl group helps to anchor the protein in a membrane. The transforming (carcinogenic) activity of the ras oncogene is lost when isoprenylation of the Ras protein is blocked, a finding that has stimulated interest in identifying inhibitors of this posttranslational modification pathway for use in cancer chemotherapy.
FIGURE 27-35 Farnesylation of a Cys residue. The thioether linkage is shown in red. The Ras protein is the product of the ras oncogene.
Addition of Prosthetic Groups
Many proteins require for their activity covalently bound prosthetic groups. Two examples are the biotin molecule of acetyl-CoA carboxylase and the heme group of hemoglobin or cytochrome c.
Proteolytic Processing
Many proteins are initially synthesized as large, inactive precursor polypeptides that are proteolytically trimmed to form their smaller, active forms. Examples include proinsulin (Fig. 23-4), some viral proteins (Fig. 26-30), and proteases such as chymotrypsinogen and trypsinogen (Fig. 6-42).
Formation of Disulfide Cross-Links
After folding into their native conformations, some proteins form intrachain or interchain disulfide bridges between Cys residues. In eukaryotes, disulfide bonds are common in proteins to be exported from cells. The cross-links formed in this way help to protect the native conformation of the protein molecule from denaturation in the extracellular environment, which can differ greatly from intracellular conditions and is generally oxidizing.
Protein Synthesis Is Inhibited by Many Antibiotics and Toxins
Protein synthesis is a central function in cellular physiology and is the primary target of many naturally occurring antibiotics and toxins. Except as noted otherwise, these antibiotics inhibit protein synthesis in bacteria. The differences between bacterial and eukaryotic protein synthesis, though in some cases subtle, are such that most of the compounds discussed below are relatively harmless to eukaryotic cells. Natural selection has favored the evolution of compounds that exploit minor differences in order to affect bacterial systems selectively, so that these biochemical weapons are synthesized by some microorganisms and are extremely toxic to others. Because nearly every step in protein synthesis can be specifically inhibited by one antibiotic or another, antibiotics have become valuable tools in the study of protein biosynthesis.
Puromycin, made by the mold Streptomyces alboniger, is one of the best-understood inhibitory antibiotics. Its structure is very similar to the end of an aminoacyl-tRNA, enabling it to bind to the ribosomal A site and participate in peptide bond formation, producing peptidylpuromycin (Fig. 27-36). However, because puromycin resembles only the end of the tRNA, it does not engage in translocation and dissociates from the ribosome shortly after it is linked to the carboxyl terminus of the peptide. This prematurely terminates polypeptide synthesis.
FIGURE 27-36 Disruption of peptide bond formation by puromycin. The antibiotic puromycin resembles the aminoacyl end of a charged tRNA, and it can bind to the ribosomal A site and participate in peptide bond formation. The product of this reaction, peptidyl puromycin, is not translocated to the P site. Instead, it dissociates from the ribosome, causing premature chain termination.
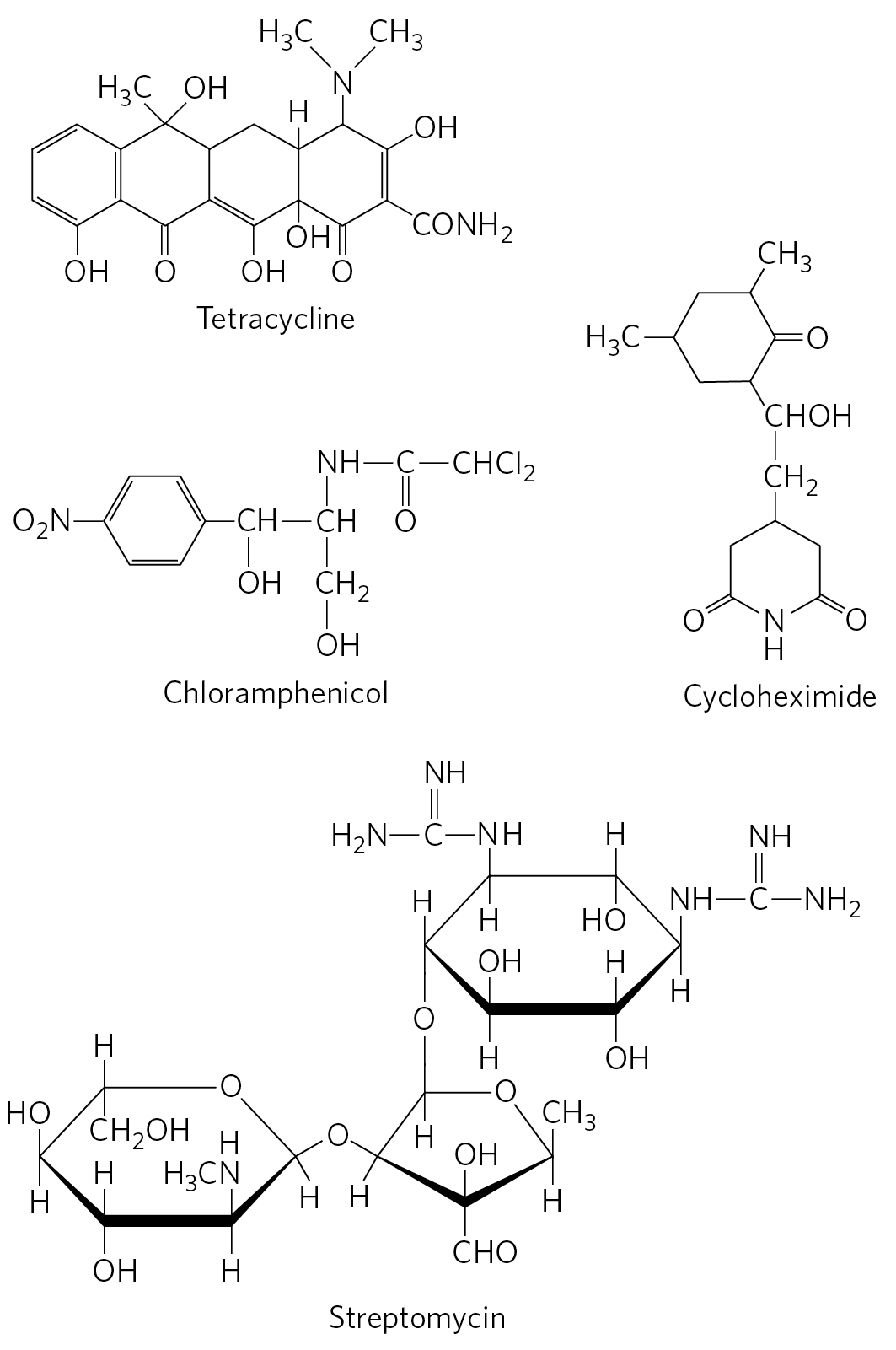
Tetracyclines inhibit protein synthesis in bacteria by blocking the A site on the ribosome, preventing the binding of aminoacyl-tRNAs. Chloramphenicol inhibits protein synthesis by bacterial (and mitochondrial and chloroplast) ribosomes by blocking peptidyl transfer; it does not affect cytosolic protein synthesis in eukaryotes. Conversely, cycloheximide blocks the peptidyl transferase of 80S eukaryotic ribosomes but not that of 70S bacterial (and mitochondrial and chloroplast) ribosomes. Streptomycin, a basic trisaccharide, causes misreading of the genetic code (in bacteria) at relatively low concentrations and inhibits initiation at higher concentrations.
Several other inhibitors of protein synthesis are notable because of their toxicity to humans and other mammals. Diphtheria is a serious bacterial illness that causes sore throat, swollen glands, breathing difficulties, and often death. Although it has been largely eradicated in the developed world, a few thousand cases still occur each year in countries where vaccination is limited. The bacterium Corynebacterium diphtheriae releases the diphtheria toxin , which catalyzes the ADP-ribosylation of a diphthamide (a modified histidine) residue of eukaryotic elongation factor eEF2, thereby inactivating it. The resulting dead cells form a thick, gray membrane that covers the throat and tonsils, creating a putrid odor that is one hallmark of the disease. Ricin , an extremely toxic protein of the castor bean, inactivates the 60S subunit of eukaryotic ribosomes by depurinating a specific adenosine residue in 28S rRNA. Ricin was used in the infamous 1978 murder of BBC journalist and Bulgarian dissident Georgi Markov, presumably by the Bulgarian secret police. Using a syringe hidden at the end of an umbrella, a member of the secret police injected Markov in the leg with a ricin-infused pellet. He died four days later.
SUMMARY 27.2 Protein Synthesis
Protein synthesis occurs on the ribosomes, which consist of protein and rRNA. Bacteria have 70S ribosomes, with a large (50S) and a small (30S) subunit. Eukaryotic ribosomes are significantly larger (80S) and contain more proteins. The growth of polypeptides on ribosomes begins with the amino-terminal amino acid and proceeds by successive additions of new residues to the carboxyl-terminal end.
Transfer RNAs have 73 to 93 nucleotide residues, some of which have modified bases. Each tRNA has an amino acid arm with the terminal sequence to which an amino acid is esterified, an anticodon arm, a TψC arm, and a D arm; some tRNAs have a fifth arm. The anticodon is responsible for the specificity of interaction between the aminoacyl-tRNA and the complementary mRNA codon.
In stage 1 of the five stages of protein synthesis, amino acids are activated by specific aminoacyl-tRNA synthetases in the cytosol. These enzymes catalyze the formation of aminoacyl-tRNAs, with simultaneous cleavage of ATP to AMP and . The fidelity of protein synthesis depends on the accuracy of this reaction, and some of these enzymes carry out proofreading steps at separate active sites.
Stage 2 is initiation. In bacteria, the initiating aminoacyl-tRNA in all proteins is Initiation of protein synthesis involves formation of a complex between the 30S ribosomal subunit, mRNA, GTP, , three initiation factors, and the 50S subunit; GTP is hydrolyzed to GDP and .
Stage 3 is elongation. In the elongation steps, GTP and elongation factors are required for binding the incoming aminoacyl-tRNA to the A site on the ribosome. In the first peptidyl transfer reaction, the fMet residue is transferred to the amino group of the incoming aminoacyl-tRNA. Movement of the ribosome along the mRNA then translocates the dipeptidyl-tRNA from the A site to the P site, a process requiring hydrolysis of GTP. Deacylated tRNAs dissociate from the ribosomal E site.
Stage 4 is termination. After many such elongation cycles, synthesis of the polypeptide is terminated with the aid of release factors. At least four high-energy phosphate equivalents (from ATP and GTP) are required to generate each peptide bond, an energy investment required to guarantee fidelity of translation.
Stage 5 is protein processing. Polypeptides fold into their active, three-dimensional forms. Many proteins are further processed by posttranslational modification reactions.
Many well-studied antibiotics and toxins inhibit some aspect of protein synthesis.
 The cellular components involved in the five stages of protein synthesis in E. coli and other bacteria are listed in
The cellular components involved in the five stages of protein synthesis in E. coli and other bacteria are listed in 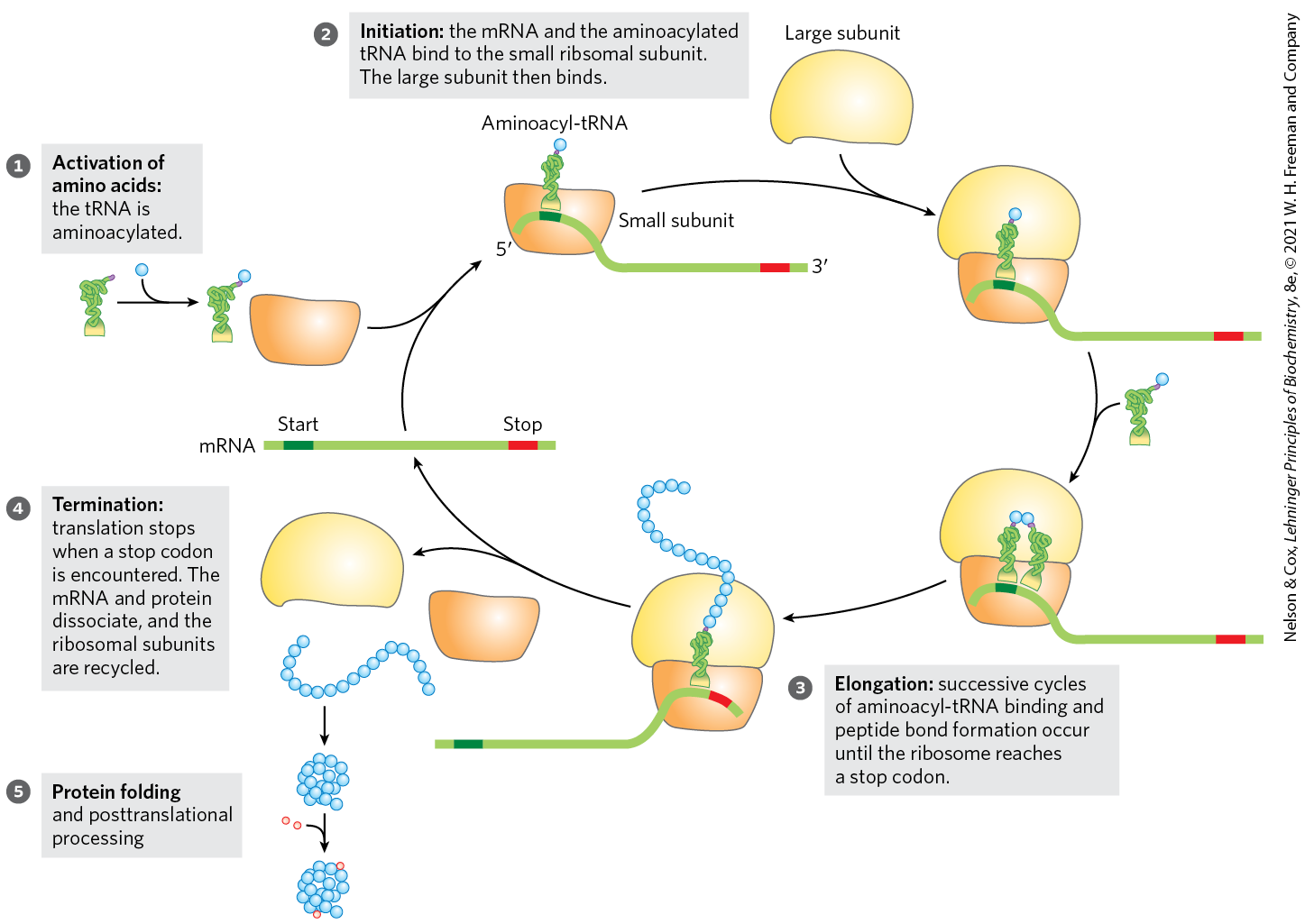
 The high-resolution structure thus confirms what Noller had predicted much earlier: the ribosome is a ribozyme. In addition to the insight that the detailed structures of the ribosome and its subunits provide into the mechanism of protein synthesis (as elaborated below), these findings have stimulated a new look at the evolution of life (
The high-resolution structure thus confirms what Noller had predicted much earlier: the ribosome is a ribozyme. In addition to the insight that the detailed structures of the ribosome and its subunits provide into the mechanism of protein synthesis (as elaborated below), these findings have stimulated a new look at the evolution of life (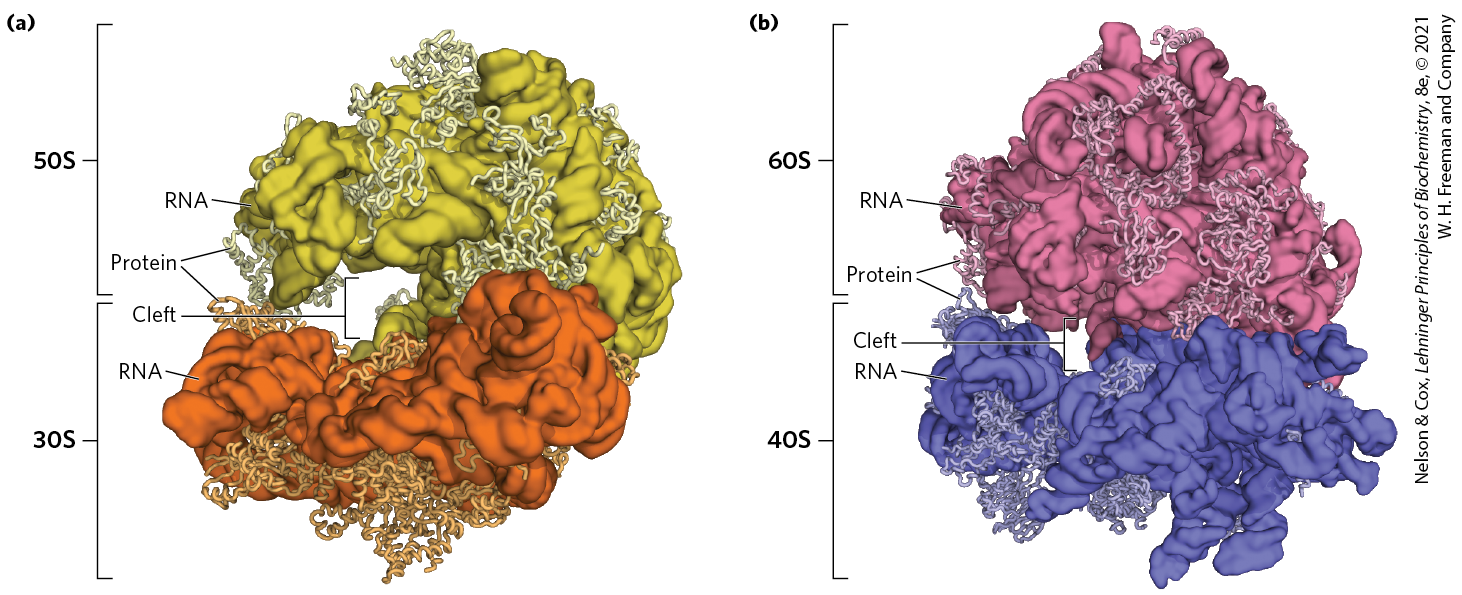
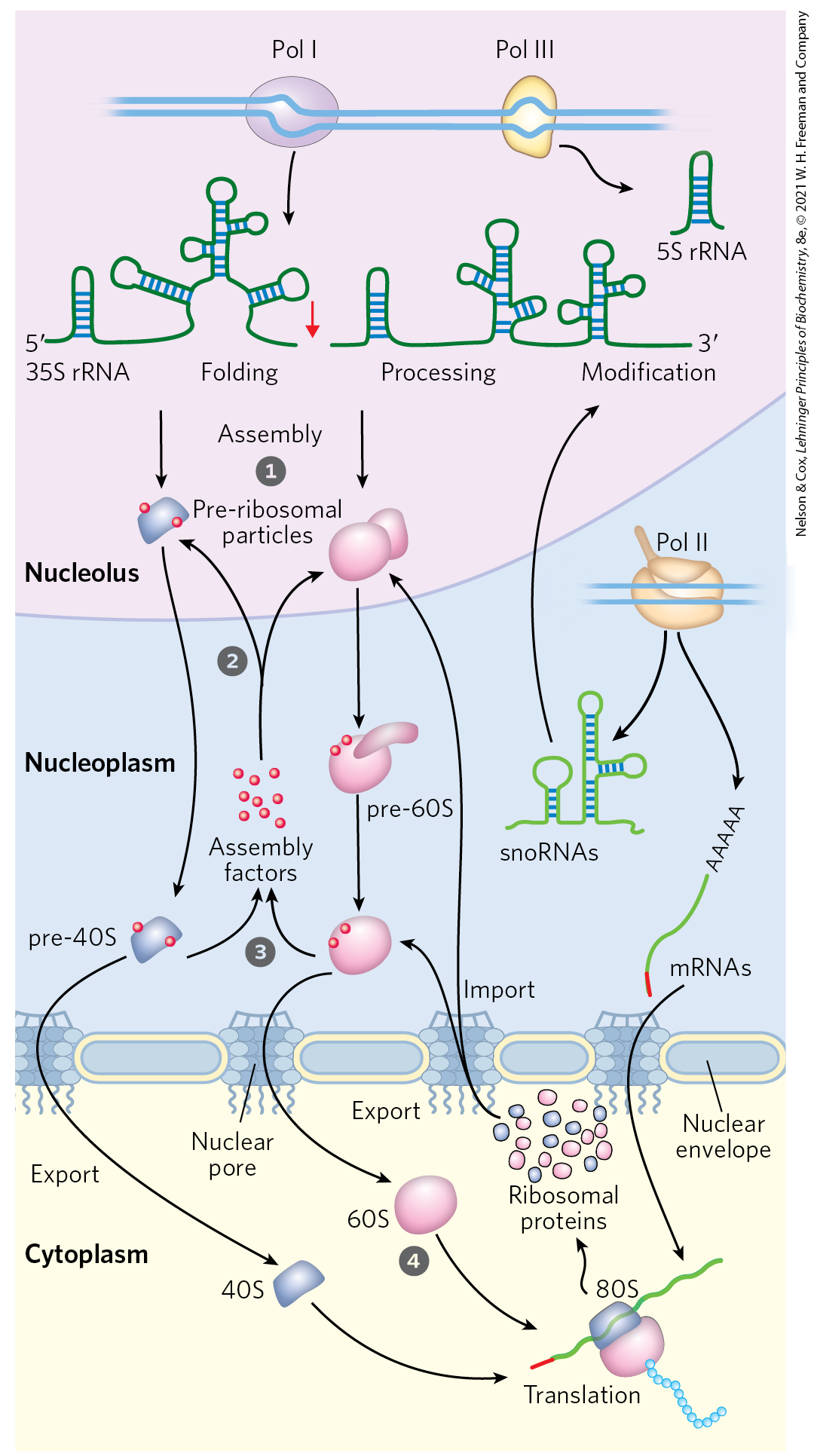
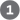 Most of the early steps of ribosome assembly occur in the nucleolus, an organelle inside the nucleus. Ribonucleases and specialized RNAs, including some snoRNAs, process the initial rRNA transcript.
Most of the early steps of ribosome assembly occur in the nucleolus, an organelle inside the nucleus. Ribonucleases and specialized RNAs, including some snoRNAs, process the initial rRNA transcript.  Large pre-ribosomal particles are formed and additional processing of the large complex occurs with the aid of proteins called assembly factors. The pre-40S and pre-60S complexes move into the nucleoplasm.
Large pre-ribosomal particles are formed and additional processing of the large complex occurs with the aid of proteins called assembly factors. The pre-40S and pre-60S complexes move into the nucleoplasm.  The 40S and 60S subunits are exported to the cytoplasm, coupled with the ejection of assembly factors.
The 40S and 60S subunits are exported to the cytoplasm, coupled with the ejection of assembly factors.  Final maturation of the ribosome occurs in the cytoplasm.
Final maturation of the ribosome occurs in the cytoplasm.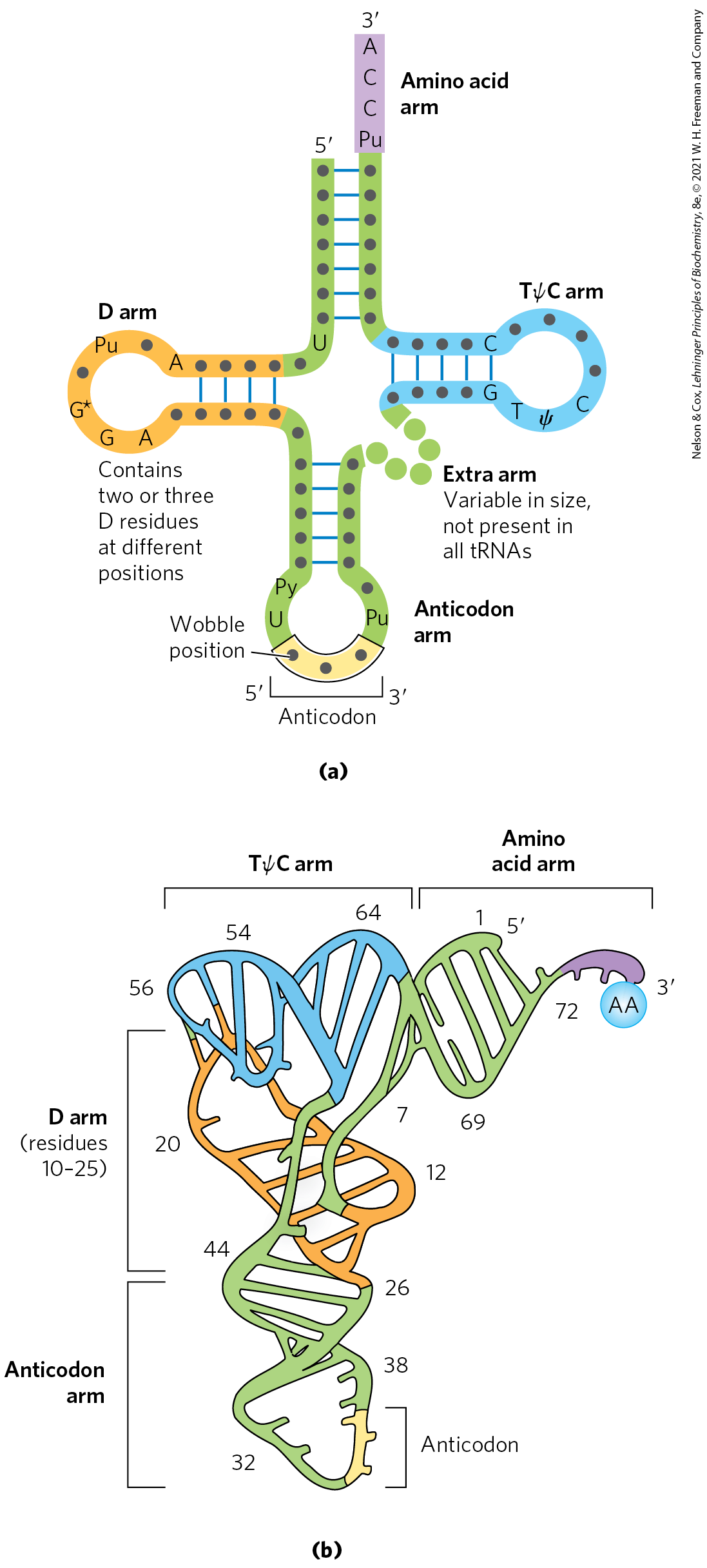
 Two of the arms of a tRNA are critical for its adaptor function. The amino acid arm can carry a specific amino acid esterified by its carboxyl group to the - or -hydroxyl group of the A residue at the end of the tRNA. The anticodon arm contains the anticodon. The other major arms are the D arm, which contains the unusual nucleotide dihydrouridine (D), and the TψC arm, which contains ribothymidine (T), not usually present in RNAs, and pseudouridine (ψ), which has an unusual carbon–carbon bond between the base and ribose (see
Two of the arms of a tRNA are critical for its adaptor function. The amino acid arm can carry a specific amino acid esterified by its carboxyl group to the - or -hydroxyl group of the A residue at the end of the tRNA. The anticodon arm contains the anticodon. The other major arms are the D arm, which contains the unusual nucleotide dihydrouridine (D), and the TψC arm, which contains ribothymidine (T), not usually present in RNAs, and pseudouridine (ψ), which has an unusual carbon–carbon bond between the base and ribose (see 
 the aminoacyl group is transferred first to the -hydroxyl group of the -terminal A residue, then
the aminoacyl group is transferred first to the -hydroxyl group of the -terminal A residue, then  to the -hydroxyl group by a transesterification reaction. For class II enzymes,
to the -hydroxyl group by a transesterification reaction. For class II enzymes,  the aminoacyl group is transferred directly to the -hydroxyl group of the terminal adenylate.
the aminoacyl group is transferred directly to the -hydroxyl group of the terminal adenylate.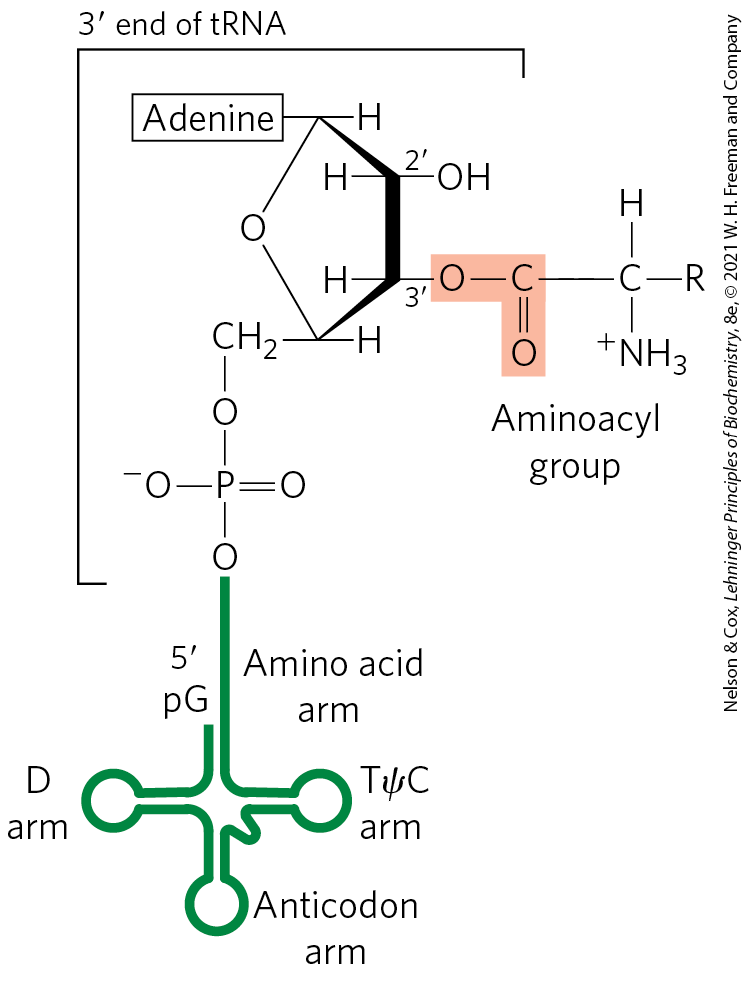
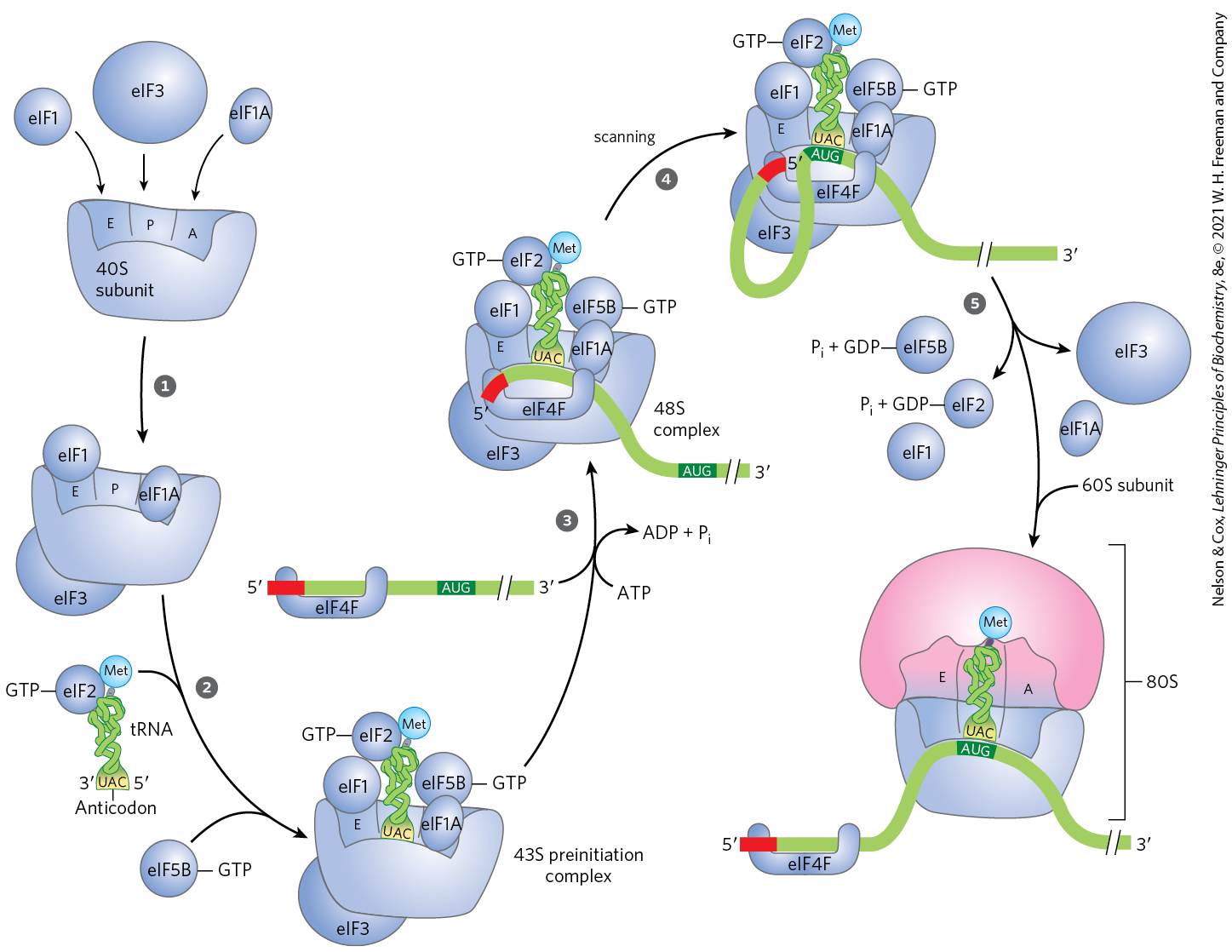
 , which is accompanied by release of many of the initiation factors. This requires the activity of eIF5 and eIF5B. The eIF5 protein promotes the GTPase activity of eIF2, producing an eIF2-GDP complex with reduced affinity for the initiator tRNA. The eIF5B protein is homologous to the bacterial IF2. It hydrolyzes its bound GTP and triggers dissociation of eIF2-GDP and other initiation factors, followed closely by association of the 60S subunit. This completes formation of the initiation complex.
, which is accompanied by release of many of the initiation factors. This requires the activity of eIF5 and eIF5B. The eIF5 protein promotes the GTPase activity of eIF2, producing an eIF2-GDP complex with reduced affinity for the initiator tRNA. The eIF5B protein is homologous to the bacterial IF2. It hydrolyzes its bound GTP and triggers dissociation of eIF2-GDP and other initiation factors, followed closely by association of the 60S subunit. This completes formation of the initiation complex.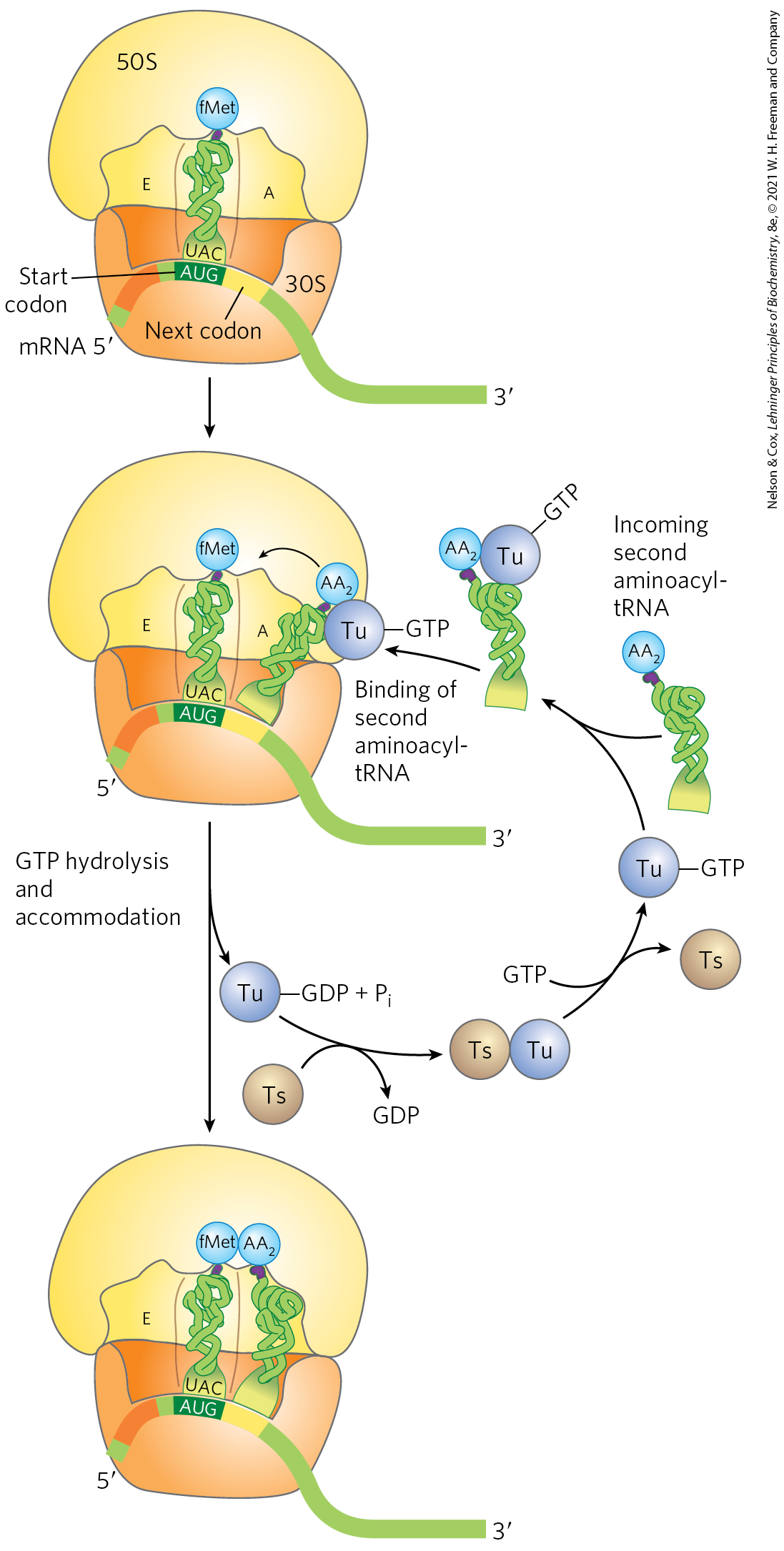
 The
The 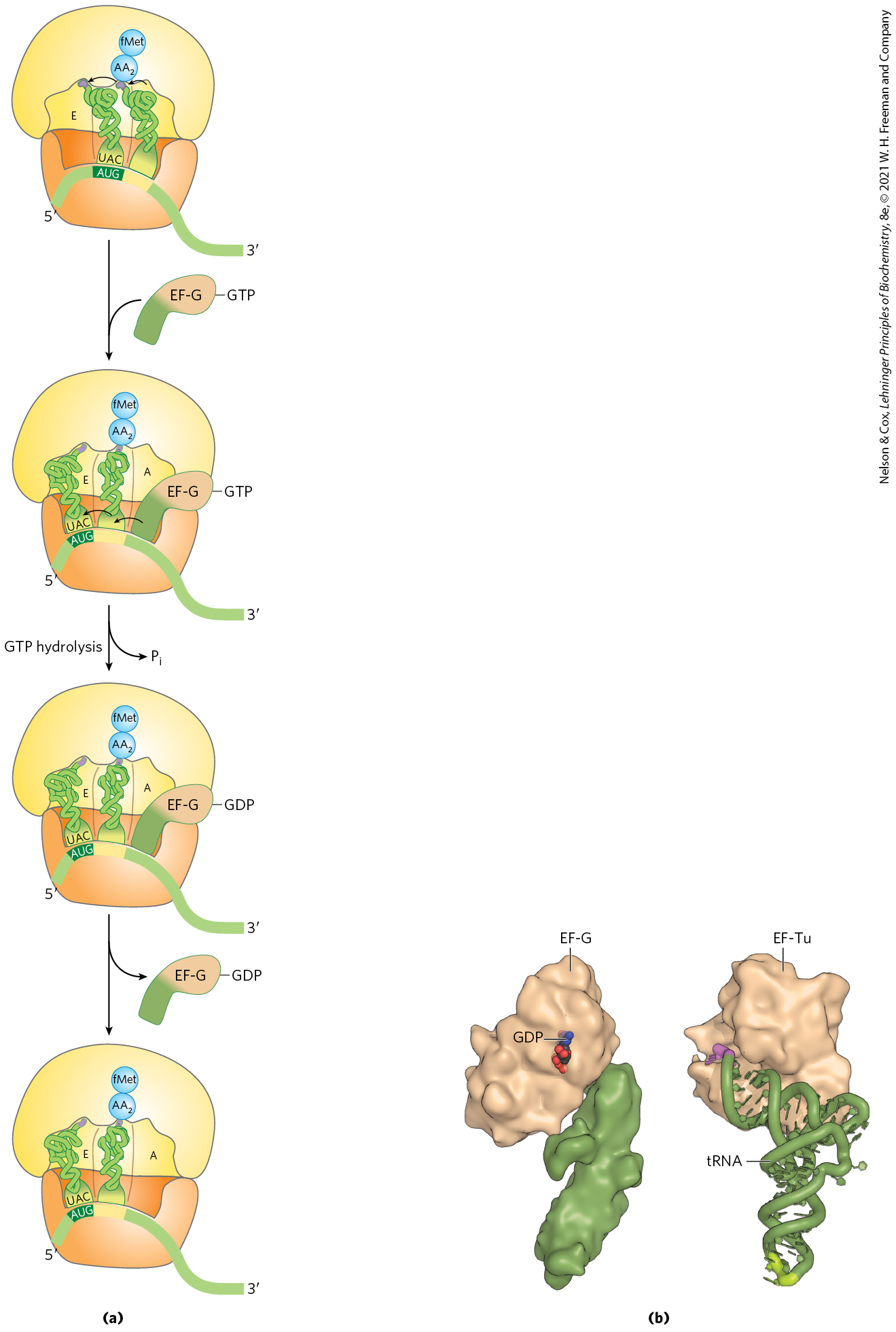
 Protein synthesis is a central function in cellular physiology and is the primary target of many naturally occurring antibiotics and toxins. Except as noted otherwise, these antibiotics inhibit protein synthesis in bacteria. The differences between bacterial and eukaryotic protein synthesis, though in some cases subtle, are such that most of the compounds discussed below are relatively harmless to eukaryotic cells. Natural selection has favored the evolution of compounds that exploit minor differences in order to affect bacterial systems selectively, so that these biochemical weapons are synthesized by some microorganisms and are extremely toxic to others. Because nearly every step in protein synthesis can be specifically inhibited by one antibiotic or another, antibiotics have become valuable tools in the study of protein biosynthesis.
Protein synthesis is a central function in cellular physiology and is the primary target of many naturally occurring antibiotics and toxins. Except as noted otherwise, these antibiotics inhibit protein synthesis in bacteria. The differences between bacterial and eukaryotic protein synthesis, though in some cases subtle, are such that most of the compounds discussed below are relatively harmless to eukaryotic cells. Natural selection has favored the evolution of compounds that exploit minor differences in order to affect bacterial systems selectively, so that these biochemical weapons are synthesized by some microorganisms and are extremely toxic to others. Because nearly every step in protein synthesis can be specifically inhibited by one antibiotic or another, antibiotics have become valuable tools in the study of protein biosynthesis.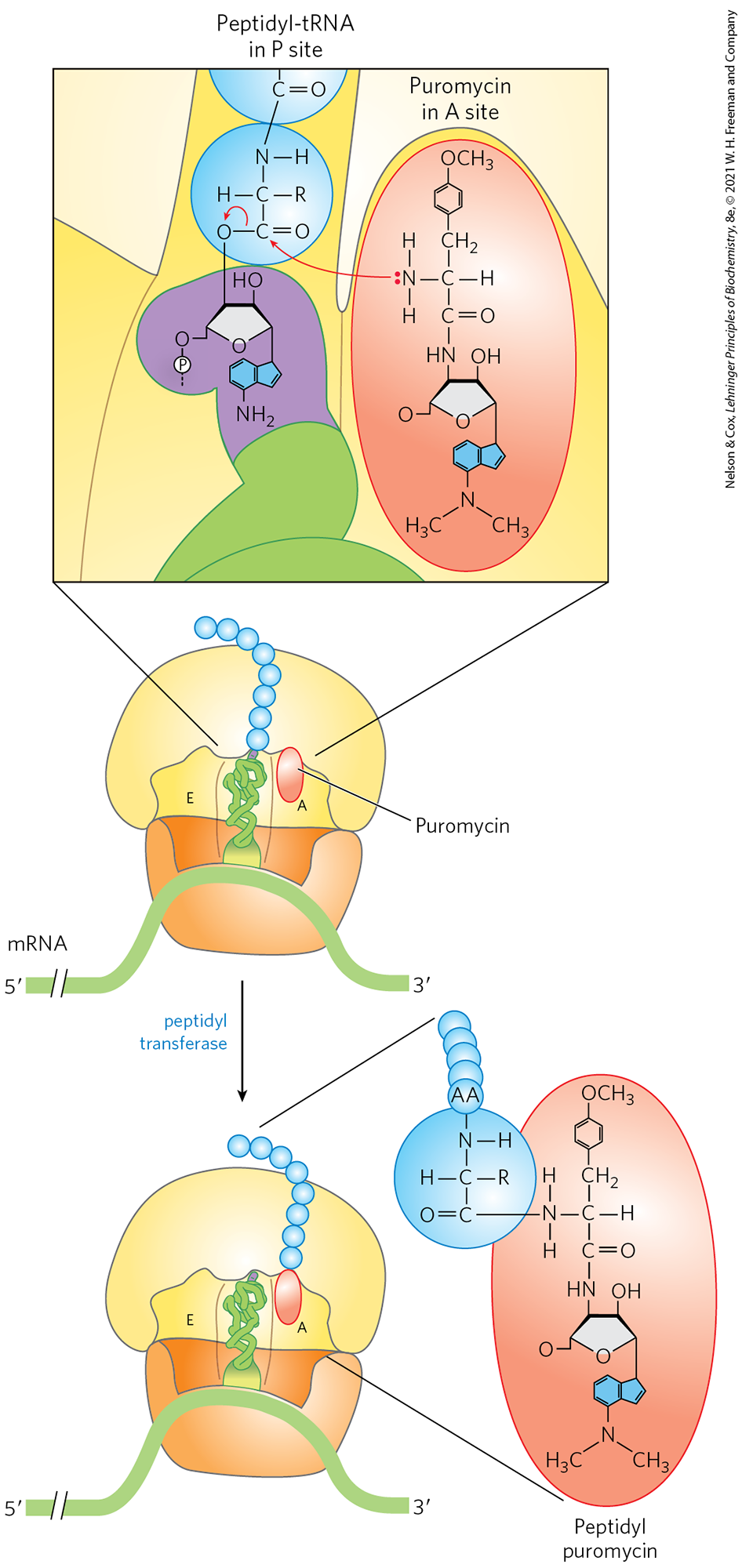

 Protein synthesis occurs on the ribosomes, which consist of protein and rRNA. Bacteria have 70S ribosomes, with a large (50S) and a small (30S) subunit. Eukaryotic ribosomes are significantly larger (80S) and contain more proteins. The growth of polypeptides on ribosomes begins with the amino-terminal amino acid and proceeds by successive additions of new residues to the carboxyl-terminal end.
Protein synthesis occurs on the ribosomes, which consist of protein and rRNA. Bacteria have 70S ribosomes, with a large (50S) and a small (30S) subunit. Eukaryotic ribosomes are significantly larger (80S) and contain more proteins. The growth of polypeptides on ribosomes begins with the amino-terminal amino acid and proceeds by successive additions of new residues to the carboxyl-terminal end.