26.1 DNA-Dependent Synthesis of RNA
Our discussion of RNA synthesis begins with a comparison between transcription and DNA replication (Chapter 25). Transcription resembles replication in its fundamental chemical mechanism, its polarity (direction of synthesis), and its use of a template. And like replication, transcription has initiation, elongation, and termination phases. Transcription differs from replication in that it does not require a primer and, generally, involves only limited segments of a DNA molecule. Additionally, only one DNA strand serves as a template for a particular RNA molecule.
RNA Is Synthesized by RNA Polymerases
The discovery of DNA polymerase and its dependence on a DNA template spurred a search for an enzyme that synthesizes RNA complementary to a DNA strand. By 1960, four research groups had independently detected an enzyme in cellular extracts that could form an RNA polymer from ribonucleoside -triphosphates. Subsequent work on the purified Escherichia coli RNA polymerase helped to define the fundamental properties of transcription (Fig. 26-1). DNA-dependent RNA polymerase requires, in addition to a DNA template, all four ribonucleoside -triphosphates (ATP, GTP, UTP, and CTP) as precursors of the nucleotide units of RNA, as well as . The chemistry and mechanism of RNA synthesis closely resemble those used by DNA polymerases (see Fig. 25-3). RNA polymerase elongates an RNA strand by adding ribonucleotide units to the -hydroxyl end, building RNA in the direction. The -hydroxyl group acts as a nucleophile, attacking the α phosphate of the incoming ribonucleoside triphosphate (Fig. 26-1a) and releasing pyrophosphate. The overall reaction is

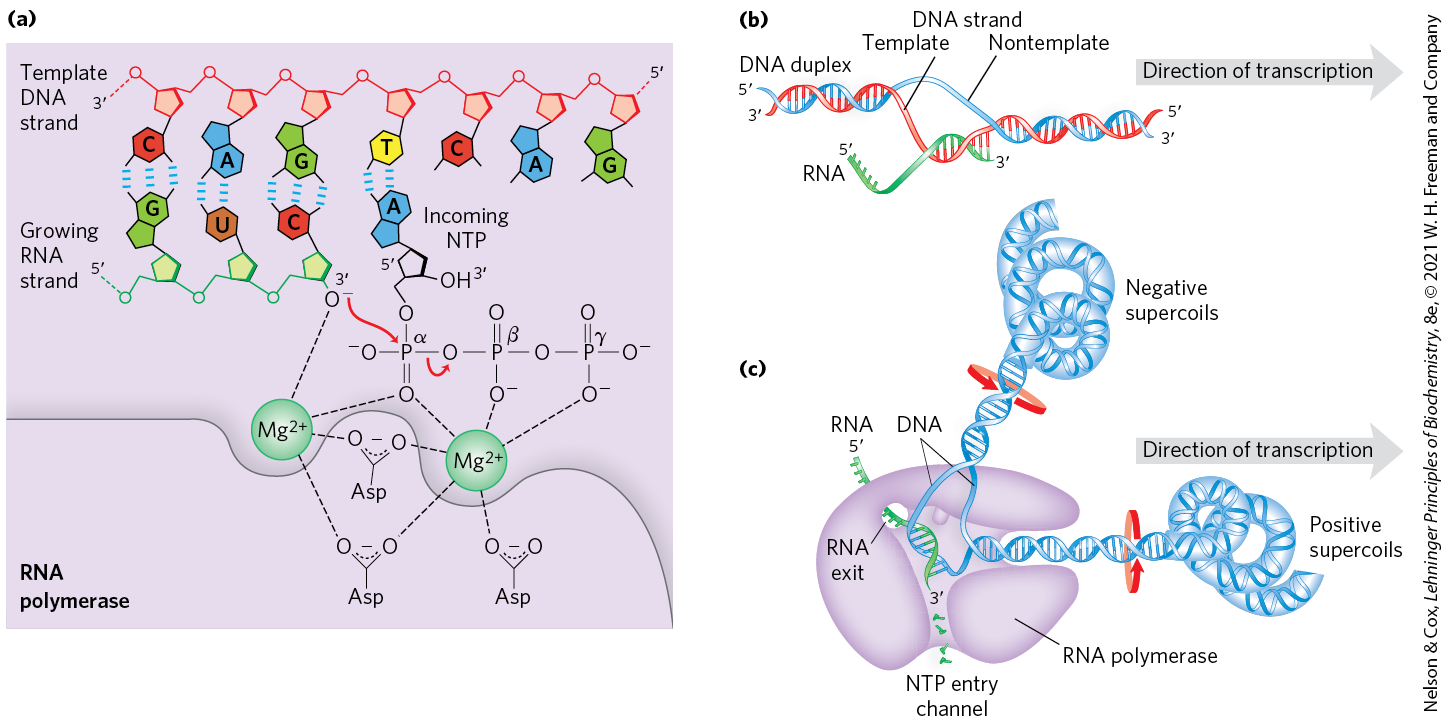
FIGURE 26-1 Transcription by RNA polymerase in E. coli. For synthesis of an RNA strand complementary to one of two DNA strands in a double helix, the DNA is transiently unwound. (a) Catalytic mechanism of RNA synthesis by RNA polymerase. Notice that this is essentially the same mechanism used by DNA polymerases. The reaction involves two ions coordinated to the phosphate groups of the incoming nucleoside triphosphates (NTPs) and to three Asp residues, which are highly conserved in the RNA polymerases of all species. One ion facilitates attack by the -hydroxyl group on the α phosphate of the NTP; the other ion facilitates displacement of the pyrophosphate. Both metal ions stabilize the pentacovalent transition state. (b) About 17 bp of DNA are unwound at any given time. RNA polymerase and the transcription bubble move from left to right along the DNA as shown, facilitating RNA synthesis. The DNA is unwound ahead and rewound behind as RNA is transcribed. As the DNA is rewound, the RNA-DNA hybrid is displaced and the RNA strand is extruded. (c) Movement of an RNA polymerase along DNA tends to create positive supercoils (overwound DNA) ahead of the transcription bubble and negative supercoils (underwound DNA) behind it. The RNA polymerase is in close contact with the DNA ahead of the transcription bubble as well as with the separated DNA strands and the RNA within and immediately behind the bubble. A channel in the protein funnels new NTPs to the polymerase active site. The polymerase footprint encompasses about 35 bp of DNA during elongation.
RNA polymerase requires DNA for activity and is most active when bound to a double-stranded DNA. As noted above, only one of the two DNA strands serves as a template. The template DNA strand is copied in the direction (antiparallel to the new RNA strand), just as in DNA replication. Each nucleotide in the newly formed RNA is selected by Watson-Crick base-pairing interactions: U residues are inserted in the RNA to pair with A residues in the DNA template, G residues are inserted to pair with C residues, and so on. Base-pair geometry (see Fig. 25-5) may also play a role in base selection.
Unlike DNA polymerase, RNA polymerase does not require a primer to initiate synthesis. Initiation occurs when RNA polymerase binds at specific DNA sequences called promoters (described below). The -triphosphate group of the first residue in a nascent (newly formed) RNA molecule is not cleaved to release , but instead remains intact and functions in eukaryotes as a substrate for the RNA-capping machinery (see Fig. 26-13). During the elongation phase of transcription, the growing end of the new RNA strand base-pairs temporarily with the DNA template to form a short hybrid RNA-DNA double helix, about 8 bp long (Fig. 26-1b). The RNA in this hybrid duplex “peels off” shortly after its formation, and the DNA duplex re-forms.
To enable RNA polymerase to synthesize an RNA strand complementary to one of the DNA strands, the DNA duplex must unwind over a short distance, forming a transcription “bubble.” During transcription, the E. coli RNA polymerase generally keeps about 17 bp unwound. The 8 bp RNA-DNA hybrid occurs in this unwound region. Elongation of a transcript by E. coli RNA polymerase proceeds at a rate of 50 to 90 nucleotides/s. Because DNA is a helix, movement of a transcription bubble requires considerable strand rotation of the nucleic acid molecules. DNA strand rotation is restricted in most DNAs by DNA-binding proteins and other structural barriers. As a result, a moving RNA polymerase generates waves of positive supercoils ahead of the transcription bubble and negative supercoils behind (Fig. 26-1c). This has been observed both in vitro and in vivo (in bacteria). In the cell, the topological problems caused by transcription are relieved through the action of topoisomerases (Chapter 24).
Key Convention
The two complementary DNA strands have different roles in transcription. The strand that serves as template for RNA synthesis is called the template strand. The DNA strand complementary to the template, the nontemplate strand, or coding strand, is identical in base sequence to the RNA transcribed from the gene, with U in the RNA in place of T in the DNA (Fig. 26-2). The coding strand for a particular gene may be located in either strand of a given chromosome (as shown in Fig. 26-3 for a virus). By convention, the regulatory sequences that control transcription (described later in this chapter) are designated by the sequences in the coding strand.


FIGURE 26-2 Template and nontemplate (coding) DNA strands. The two complementary strands of DNA are defined by their function in transcription. The RNA transcript is synthesized on the template strand and is identical in sequence (with U in place of T) to the nontemplate strand, or coding strand.
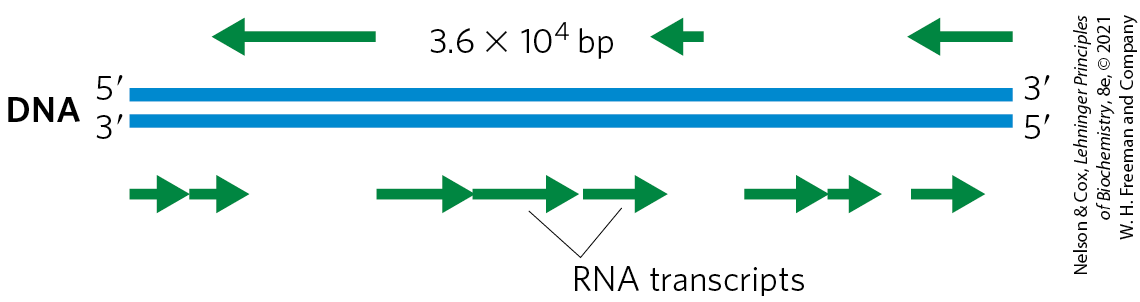
FIGURE 26-3 Organization of coding information in the adenovirus genome. The genetic information of the adenovirus genome is encoded by a double-stranded DNA molecule of 36,000 bp, both strands of which encode proteins. The information for most proteins is encoded by (that is, identical to) the top strand — by convention, the strand is oriented to from left to right. The bottom strand acts as template for these transcripts. However, a few proteins are encoded by the bottom strand, which is transcribed in the opposite direction (and uses the top strand as template).
The DNA-dependent RNA polymerase of E. coli is a large, complex enzyme with five core subunits ; and a sixth subunit, one of a group designated , with variants designated by size (molecular weight). The subunit binds transiently to the core and directs the enzyme to specific binding sites on the DNA (described below). These six subunits constitute the RNA polymerase holoenzyme (Fig. 26-4). The RNA polymerase holoenzyme of E. coli thus exists in several forms, depending on the type of subunit. The most common subunit is , and the upcoming discussion focuses on the corresponding RNA polymerase holoenzyme.
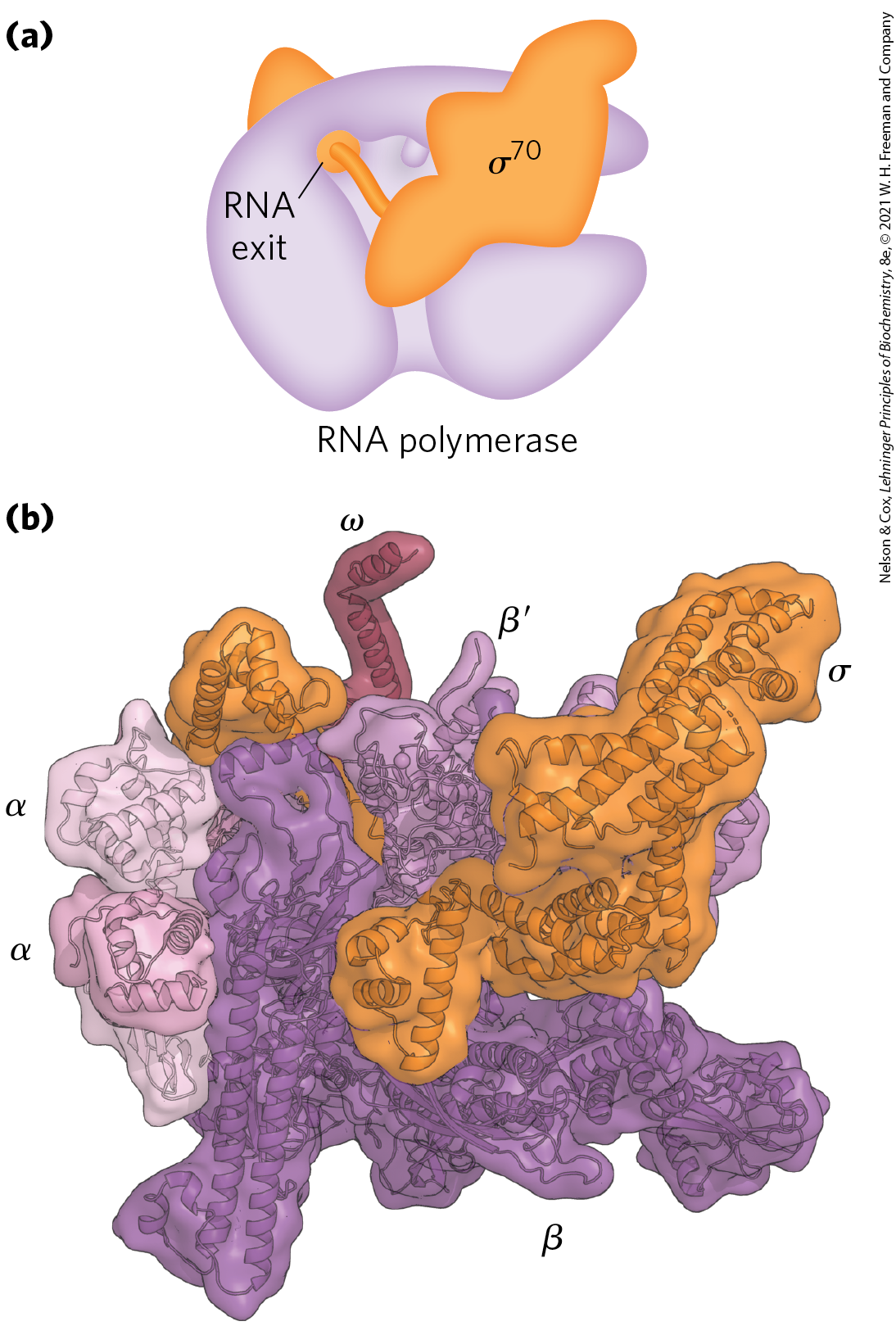
FIGURE 26-4 Structure of the RNA polymerase holoenzyme of E. coli. (a) The several subunits of the bacterial RNA polymerase give the enzyme the shape of a crab claw (purple). The subunit rests on top of the crab claw and threads through the RNA exit channel. (b) In this crystal structure of the RNA polymerase holoenzyme, each of the six subunits ( and ) can be identified. The pincers of the crab claw are formed by the β and subunits. [Data from PDB ID 4MEY, D. Degen et al., eLife 3:e02451, 2014.]
RNA polymerases lack a separate proofreading exonuclease active site (such as that of many DNA polymerases), and the error rate for transcription is higher than that for chromosomal DNA replication — approximately one error for every to ribonucleotides incorporated into RNA. Because many copies of an RNA are generally produced from a single gene, and nearly all RNAs are eventually degraded and replaced, a mistake in an RNA molecule is of less consequence to the cell than a mistake in the permanent information stored in DNA. Many RNA polymerases, including bacterial RNA polymerase and the eukaryotic RNA polymerase II (discussed below), do pause when a mispaired base is added during transcription, and they can remove mismatched nucleotides from the end of a transcript by direct reversal of the polymerase reaction. But we do not yet know whether this activity is a true proofreading function and to what extent it may contribute to the fidelity of transcription.
RNA Synthesis Begins at Promoters
Initiation of RNA synthesis at random points in a DNA molecule would be an extraordinarily wasteful process. Instead, an RNA polymerase binds to specific sequences in the DNA called cMm6zGWrbSpromoters, which direct the transcription of adjacent segments of DNA (genes). The sequences where RNA polymerases bind are variable, and much research has focused on identifying the particular sequences that are critical to promoter function.
In E. coli, RNA polymerase binding occurs within a region stretching from about 70 bp before the transcription start site to about 30 bp beyond it. By convention, the DNA base pairs that correspond to the beginning of an RNA molecule are given positive numbers, and those preceding the RNA start site are given negative numbers. The promoter region thus extends between positions and . Analyses and comparisons of the most common class of bacterial promoters (those recognized by an RNA polymerase holoenzyme containing ) have revealed consensus sequences centered about positions and (Fig. 26-5a). Although the sequences are not identical for all bacterial promoters in this class, certain nucleotides that are particularly common at each position form a consensus sequence. The consensus sequence at the region is TATAAT; at the region it is TTGACA. A third AT-rich recognition element, called the UP (upstream promoter) element, occurs between positions and in the promoters of certain highly expressed genes. The UP element is bound by the α subunit of RNA polymerase. The efficiency with which an RNA polymerase containing binds to a promoter and initiates transcription is determined in large measure by these sequences, the spacing between them, and their distance from the transcription start site. A change in only one base pair in the promoter can decrease the rate of binding by several orders of magnitude. The promoter sequence thus establishes a basal level of expression that can vary greatly from one E. coli gene to the next. The x-ray crystal structure of the RNA polymerase holoenzyme bound to its promoter shows how the factor recognizes both the RNA polymerase and the and regions by introducing a large bend in the DNA (Fig. 26-5b). Information about these interactions can also be obtained using the method illustrated in Box 26-1.
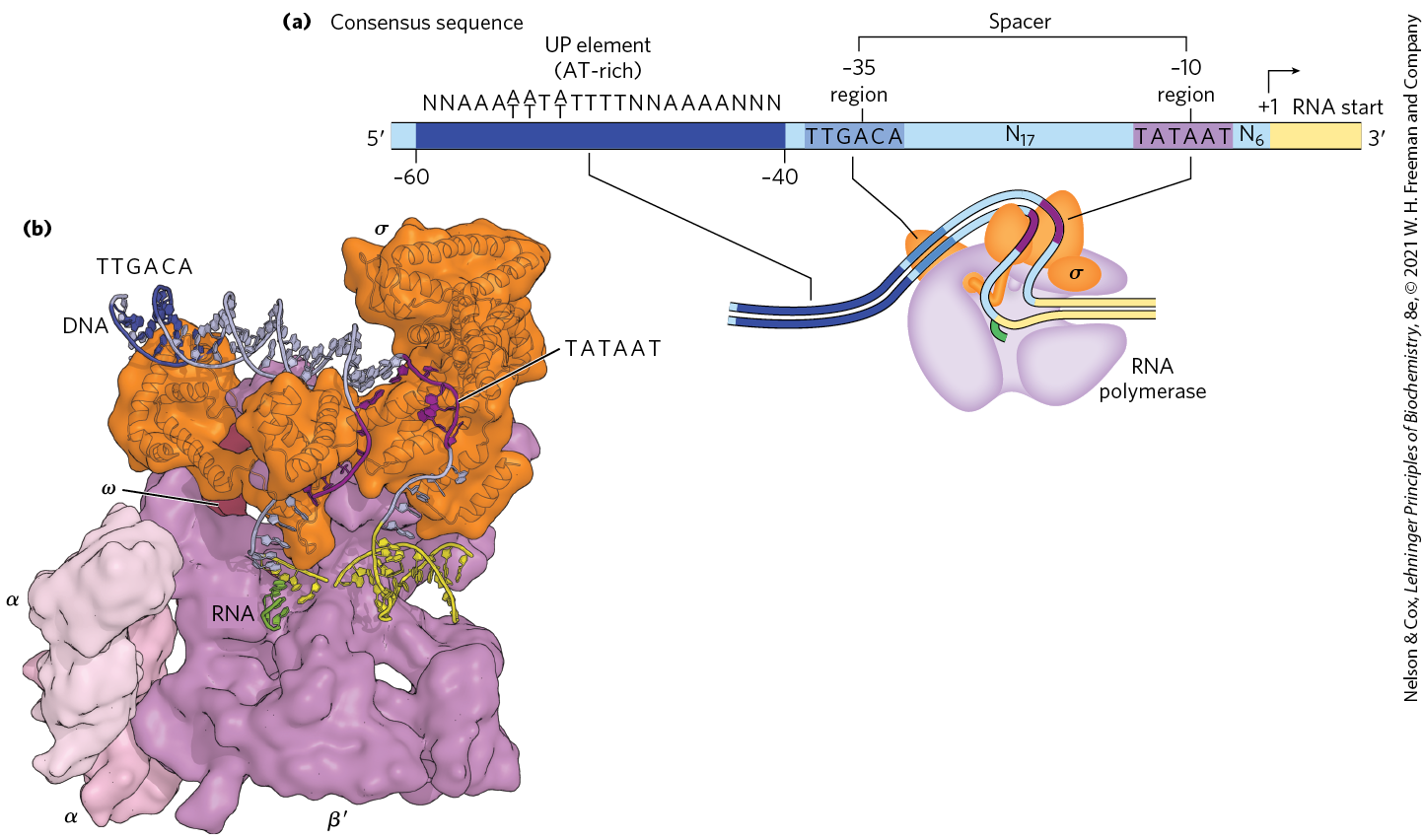
FIGURE 26-5 Promoter recognition by RNA polymerase holoenzymes containing . (a) The nontemplate strand of the consensus sequence for E. coli promoters recognized by is shown, read in the direction, as is the convention for representations of this kind. The sequences differ from one promoter to the next, but comparisons of many promoters reveal similarities, particularly in the and regions. The sequence element UP, not present in all E. coli promoters, generally occurs in the region between and and strongly stimulates transcription at the promoters that contain them. Spacer regions contain slightly variable numbers of nucleotides (N). Only the first nucleotide coding the RNA transcript (at position ) is shown. (b) This x-ray crystallographic structure of the E. coli holoenzyme bound to a promoter shows that the subunit introduces a sharp bend in the DNA template, allowing it to simultaneously contact the and regions as well as the RNA polymerase core. In this view the β subunit was omitted to allow the path of the DNA through the polymerase to be more easily seen. Due to the low resolution of the structure (5.5 Å) not all of the DNA backbone could be modeled, and these unmodeled regions are missing from the DNA shown in the figure. A cartoon schematic of the structure is also shown below (a), aligned with consensus promoter elements. [Data from PDB ID 4YLN, Y. Zuo and T. A. Steitz, Mol. Cell 58:534, 2015.]
The pathway of transcription initiation and the fate of the subunit are illustrated in Figure 26-6. The pathway consists of two major parts, binding and initiation, each with multiple steps. First, the polymerase, directed by its bound factor, binds to the promoter. A closed complex (in which the bound DNA remains double-stranded) and an open complex (in which the bound DNA is partially unwound near the sequence) form in succession. Second, transcription is initiated within the complex, leading to a conformational change that converts the complex to the elongation form, followed by movement of the transcription complex away from the promoter (promoter clearance). Any of these steps can be affected by the specific makeup of the promoter sequences. The subunit dissociates at random as the polymerase enters the elongation phase of transcription. The protein NusA () binds to the elongating RNA polymerase, competitively with the subunit. Once transcription is complete, NusA dissociates from the enzyme, the RNA polymerase dissociates from the DNA, and a factor ( or another) can again bind to the enzyme to initiate transcription.
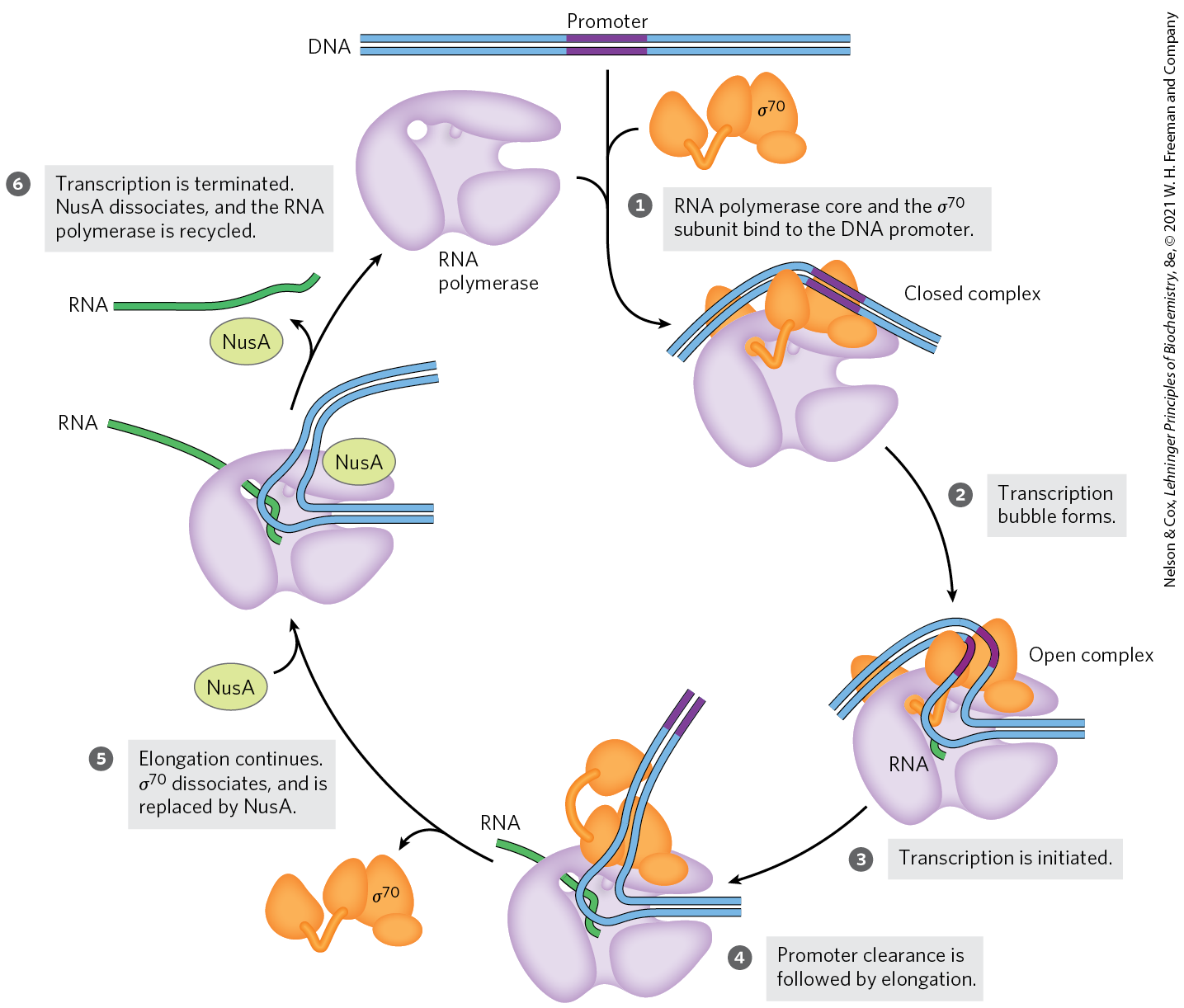
FIGURE 26-6 Transcription initiation and elongation by E. coli RNA polymerase. Initiation of transcription requires several steps generally divided into two phases: binding and initiation. In the binding phase, the initial interaction of the RNA polymerase with the promoter leads to formation of a closed complex, in which the promoter DNA is stably bound but not unwound. A 12 to 15 bp region of DNA — from within the region to position or — is then unwound to form an open complex. Additional intermediates (not shown) have been detected in the pathways leading to the closed and open complexes, along with several changes in protein conformation. The initiation phase encompasses promoter binding, transcription initiation, and promoter clearance (steps through here). Once elongation commences, the subunit is released and is replaced by the protein NusA. The polymerase leaves the promoter and becomes committed to elongation of the RNA (step ). When transcription is complete, the RNA is released, the NusA protein dissociates, and the RNA polymerase dissociates from the DNA (step ). Another subunit binds to the RNA polymerase and the process begins again.
 through
through  here). Once elongation commences, the subunit is released and is replaced by the protein NusA. The polymerase leaves the promoter and becomes committed to elongation of the RNA (step
here). Once elongation commences, the subunit is released and is replaced by the protein NusA. The polymerase leaves the promoter and becomes committed to elongation of the RNA (step  ). When transcription is complete, the RNA is released, the NusA protein dissociates, and the RNA polymerase dissociates from the DNA (step
). When transcription is complete, the RNA is released, the NusA protein dissociates, and the RNA polymerase dissociates from the DNA (step  ). Another subunit binds to the RNA polymerase and the process begins again.
). Another subunit binds to the RNA polymerase and the process begins again.E. coli has other classes of promoters bound by RNA polymerase holoenzymes with different subunits, such as the promoters of the heat shock genes. The products of this set of genes are made at higher levels when the cell is exposed to environmental stress, such as a sudden increase in temperature. RNA polymerase binds to the promoters of these genes only when is replaced with the () subunit, which is specific for the heat shock promoters (see Fig. 28-3). By using different subunits, the cell can coordinate the expression of sets of genes, permitting major changes in cell physiology. Which sets of genes are expressed is determined by the availability of the various subunits. This, in turn, is determined by several factors: regulated rates of synthesis and degradation, posttranslational modifications that switch individual subunits between active and inactive forms, and a specialized class of anti- proteins, each type binding to and sequestering a particular subunit to render it unavailable for transcription initiation.
Transcription Is Regulated at Several Levels
Requirements for any gene product vary with cellular conditions or developmental stage, and transcription of each gene is carefully regulated to form gene products only in the proportions needed. Regulation can occur at any step of transcription, including elongation and termination. However, much of the regulation is directed at the polymerase binding and transcription initiation steps outlined in Figure 26-6. Differences in promoter sequences are just one of several levels of control.
The binding of proteins to sequences both near to and distant from the promoter can also affect levels of gene expression. Protein binding can activate transcription by facilitating either RNA polymerase binding or steps farther along in the initiation process, or it can repress transcription by blocking the activity of the polymerase. In E. coli, one protein that activates transcription is the cAMP receptor protein (CRP), which increases the transcription of genes coding for enzymes that metabolize sugars other than glucose when cells are grown in the absence of glucose. Repressors are proteins that block the synthesis of RNA at specific genes. In the case of the Lac repressor, transcription of the genes for the enzymes of lactose metabolism is blocked when lactose is unavailable.
As described further in Chapter 27, transcription of mRNAs and their translation are tightly coupled in bacteria. As a protein-coding gene is being transcribed, ribosomes rapidly bind to and begin to translate the mRNA before its synthesis is complete. Another protein, NusG, binds directly to both the ribosome and RNA polymerase, linking the two complexes. The rate of translation directly affects the rate of transcription. In contrast, eukaryotes carry out transcription in the nucleus and translation in the cytoplasm, making it impossible for these two steps to be physically coupled.
Specific Sequences Signal Termination of RNA Synthesis
RNA synthesis is processive; that is, the RNA polymerase introduces a large number of nucleotides into a growing RNA molecule before dissociating (p. 917). This is necessary because, if the polymerase released an RNA transcript prematurely, it could not resume synthesis of the same RNA and would have to start again from the beginning of the gene. However, an encounter with certain DNA sequences results in a pause in RNA synthesis, and at some of these sequences transcription is terminated. Our focus here is again on the well-studied systems in bacteria. E. coli has at least two classes of termination signals: one class relies on a protein factor called (rho), and the other is -independent.
Most -independent terminators have two distinguishing features. The first is a region that produces an RNA transcript with self-complementary sequences, permitting the formation of a hairpin structure (see Fig. 8-19a) centered 15 to 20 nucleotides before the projected end of the RNA strand. The second feature is a highly conserved string of three A residues in the template strand that are transcribed into U residues near the end of the hairpin. When a polymerase arrives at a termination site with this structure, it pauses (Fig. 26-7a). Formation of the hairpin structure in the RNA disrupts several base pairs in the RNA-DNA hybrid segment and may disrupt important interactions between RNA and the RNA polymerase, facilitating dissociation of the transcript.
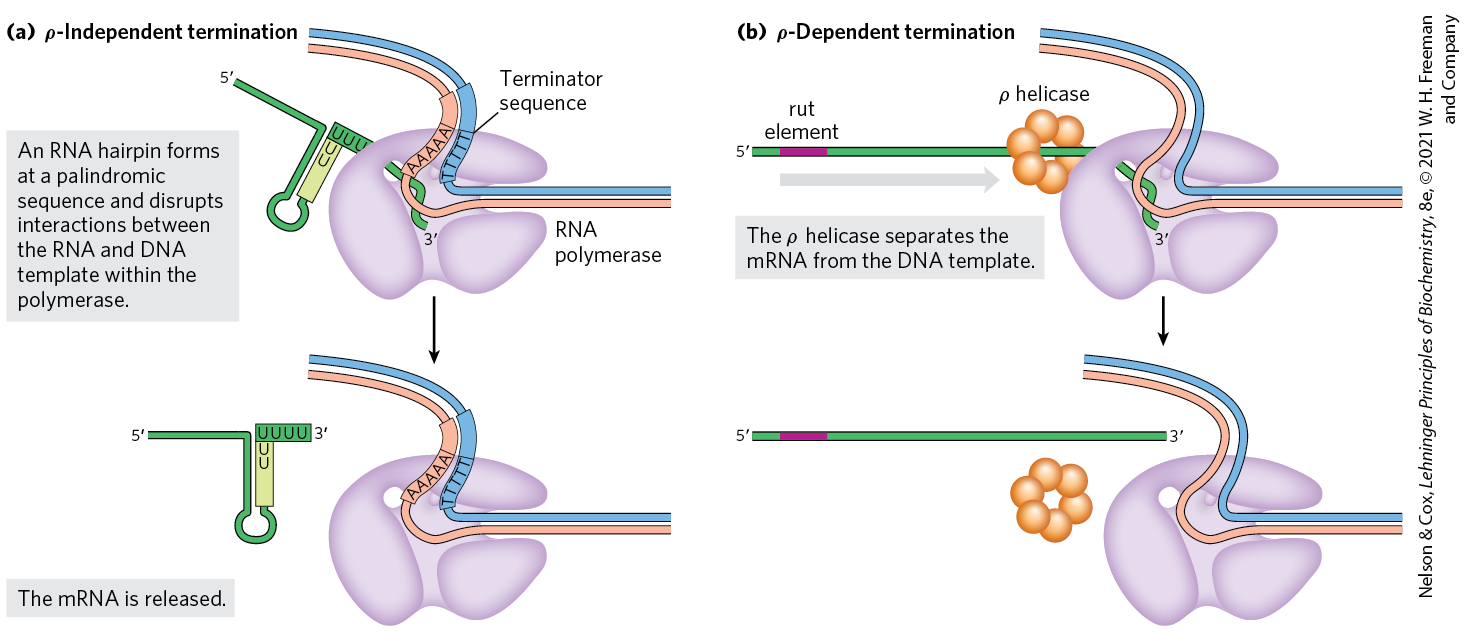
FIGURE 26-7 Termination of transcription in E. coli. (a) -Independent termination. RNA polymerase pauses at a variety of DNA sequences, some of which are terminators. One of two outcomes is then possible: either the polymerase bypasses the site and continues on its way, or the complex undergoes a conformational change (isomerization). During isomerization, intramolecular pairing of complementary sequences in the newly formed RNA transcript may form a hairpin that disrupts the RNA-DNA hybrid, the interactions between RNA and polymerase, or both. An hybrid region at the end of the new transcript is relatively unstable, and the RNA dissociates from the complex completely, leading to termination. At nonterminating pause sites, the complex may escape after the isomerization step to continue RNA synthesis. (b) -Dependent termination. RNAs that include a rut element recruit the helicase. The helicase migrates along the mRNA in the direction and separates it from the polymerase.
The -dependent terminators lack the sequence of repeated A residues in the template strand but usually include a CA-rich sequence called a rut (rho utilization) element. The protein associates with the RNA at specific binding sites and migrates in the direction until it reaches the transcription complex that is paused at a termination site (Fig. 26-7b). Here it promotes release of the RNA transcript. The protein has an ATP-dependent RNA-DNA helicase activity that permits translocation of the protein along the RNA, and ATP is hydrolyzed by the protein during the termination process. The detailed mechanism by which the protein promotes the release of the RNA transcript is not known.
Eukaryotic Cells Have Three Kinds of Nuclear RNA Polymerases
The transcriptional machinery in the nucleus of a eukaryotic cell is much more complex than that in bacteria. Eukaryotes have three nuclear RNA polymerases, designated I, II, and III, which are distinct complexes but have certain subunits in common. Each polymerase has a specific function (Table 26-1) and is recruited to a specific promoter sequence. In addition, eukaryotic mitochondria and chloroplasts have their own RNA polymerases for transcription of genes encoded in their own DNA (see Fig. 19-40). The RNA polymerases in these organelles are similar to bacterial RNA polymerases and less elaborate than the nuclear transcription machinery discussed below.
| RNA polymerase | Types of RNA synthesized |
|---|---|
I |
Pre-ribosomal RNA |
II |
mRNA ncRNA |
III |
tRNA 5S rRNA ncRNA |
RNA polymerase I (Pol I) is responsible for the synthesis of only one type of RNA, a transcript called pre-ribosomal RNA (or pre-rRNA), which contains the precursor for the 18S, 5.8S, and 28S rRNAs. The principal function of RNA polymerase II (Pol II) is the synthesis of mRNAs and many ncRNAs. This enzyme can recognize thousands of promoters that vary greatly in sequence. Some Pol II promoters have a few sequence features in common, including a TATA box (eukaryotic consensus sequence TATA(A/T)A(A/T)(A/G)) near base pair and an Inr sequence (initiator) near the RNA start site at (Fig. 26-8). However, such promoters are in the minority, and elaborate interactions with regulatory proteins guide Pol II function at many promoters that lack these features.
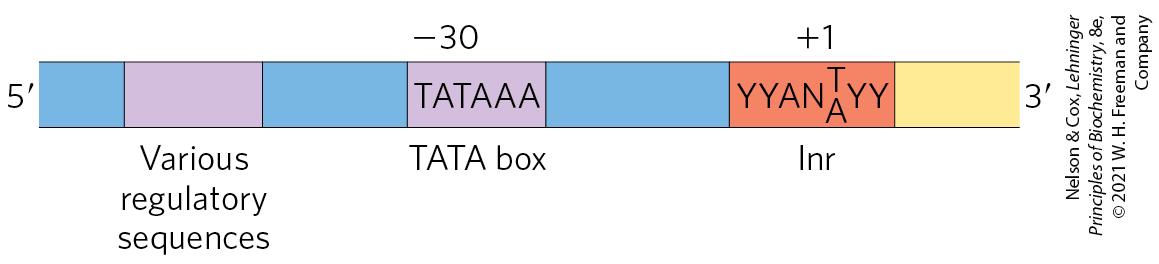
FIGURE 26-8 Some common features of TATA box promoters recognized by eukaryotic RNA polymerase II. The TATA box is the major assembly point for the proteins of the preinitiation complexes of Pol II. The DNA is unwound at the initiator sequence (Inr), and the transcription start site is usually within or very near this sequence. In the Inr consensus sequence shown here, N represents any nucleotide and Y represents a pyrimidine nucleotide. Additional sequences around the TATA box and downstream (to the right as shown here) of Inr may be recognized by one or more transcription factors. The sequence elements of Pol II promoters summarized here are much more variable and complex in comparison to E. coli promoters (see Fig. 26-5).
RNA polymerase III (Pol III) makes tRNAs, the 5S rRNA, and other small, specialized ncRNAs, including the U6 RNA component of the spliceosome, which we will discuss in Section 26.2. The promoters recognized by Pol III are well characterized. Some of the sequences required for the regulated initiation of transcription by Pol III are located within the gene itself, whereas others are in more conventional locations upstream of the RNA start site (Chapter 28).
RNA Polymerase II Requires Many Other Protein Factors for Its Activity
RNA polymerase II is central to eukaryotic gene expression and has been studied extensively. Although this polymerase is strikingly more complex than its bacterial counterpart, the complexity masks a remarkable conservation of structure, function, and mechanism. Pol II isolated from either yeast or human cells is a 12-subunit enzyme with an aggregate molecular weight of more than 510,000. The largest subunit (RBP1) exhibits a high degree of homology to the subunit of bacterial RNA polymerase. Another subunit (RBP2) is structurally similar to the bacterial β subunit, and two others (RBP3 and RBP11) show some structural homology to the two bacterial α subunits. Pol II must function with genomes that are more complex and with DNA molecules more elaborately packaged than in bacteria. The need for protein-protein contacts with the numerous other protein factors required to navigate this labyrinth accounts in large measure for the added complexity of the eukaryotic polymerase.
The largest subunit of Pol II (RBP1) also has an unusual feature, a long carboxyl-terminal tail consisting of many repeats of a consensus heptad amino acid sequence, —YSPTSPS—. There are 26 repeats in the yeast enzyme (19 exactly matching the consensus) and 52 (21 exact) in the mouse and human enzymes. This carboxyl-terminal domain (CTD) is separated from the main body of the enzyme by an intrinsically disordered linker sequence. The CTD has many important roles in Pol II function, as outlined below.
RNA polymerase II requires an array of other proteins, called transcription factors, to form the active transcription complex. The general transcription factors required at every Pol II promoter (factors usually designated TFII with an additional identifier) are highly conserved in all eukaryotes (Table 26-2). The process of transcription by Pol II can be described in terms of several phases — assembly, initiation, elongation, termination — each associated with characteristic proteins (Fig. 26-9). The step-by-step pathway described below leads to active transcription in vitro. In the cell, many of the proteins may be present in larger, preassembled complexes, simplifying the pathways for assembly on promoters. As you read about this process, consult Figure 26-9 and Table 26-2 to help keep track of the many participants.
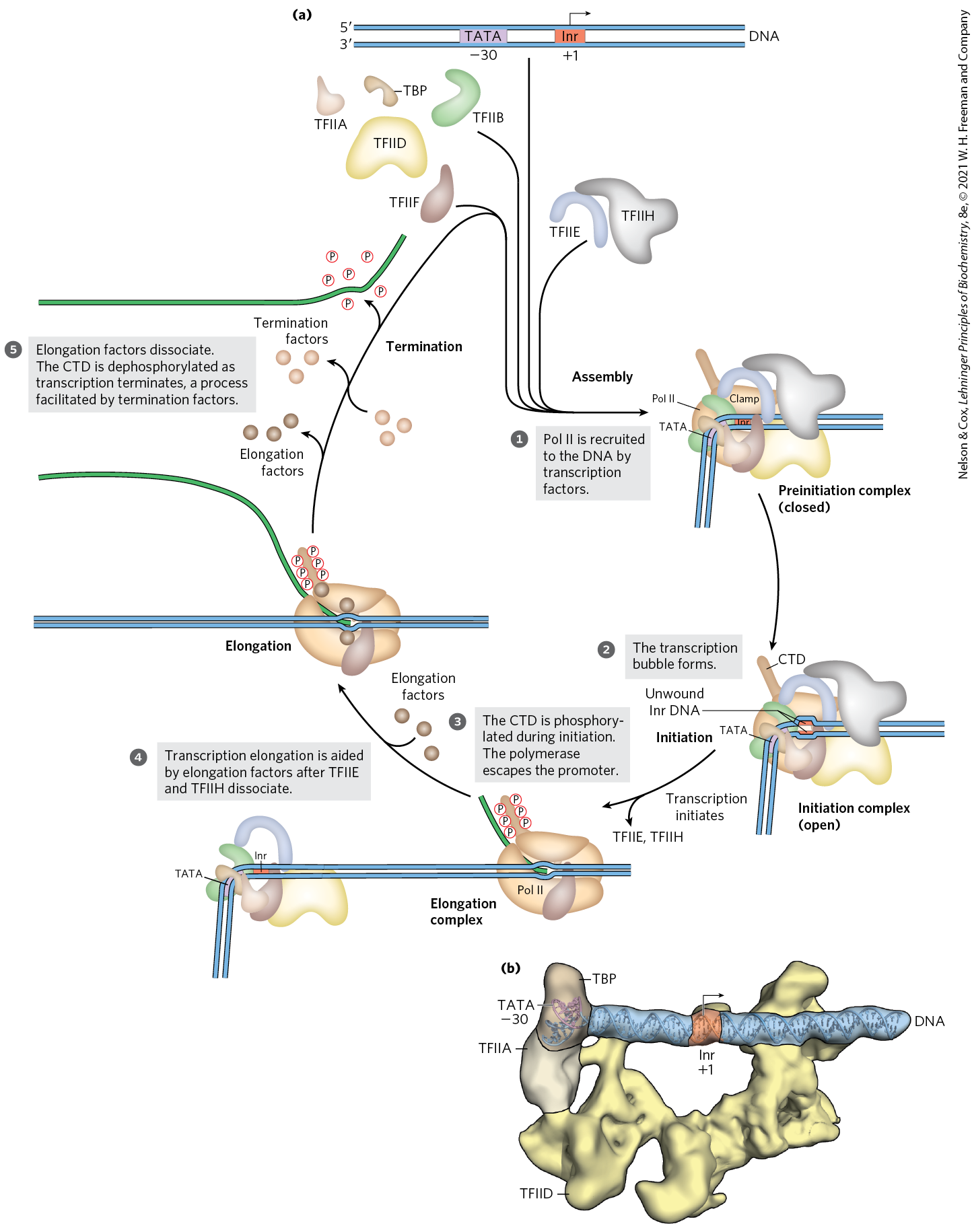
FIGURE 26-9 Transcription at RNA polymerase II promoters. (a) TBP (often with TFIIA and sometimes with TFIID) and TFIIB bind sequentially to a promoter. TFIIF plus Pol II are then recruited to that complex. The further addition of TFIIE and TFIIH results in a closed complex. Within the complex, the DNA is unwound at the Inr region by the helicase activity of TFIIH and perhaps of TFIIE, creating an open complex that completes assembly. The carboxyl-terminal domain of the largest Pol II subunit is phosphorylated by TFIIH, and the polymerase then escapes the promoter and initiates transcription. Elongation is accompanied by the release of many transcription factors and is also enhanced by elongation factors (see Table 26-2). After termination, Pol II is released, dephosphorylated, and recycled. (b) Structure of the human TFIIA/TFIID/TBP complex bound to promoter DNA, determined by cryo-EM. The DNA is stretched linearly over 70 base pairs, with the Inr sequence positioned roughly in the middle of TFIID, anchored by TBP/TATA-box interactions on the end. [(a) Information from E. Nogales et al., Curr. Opin. Struct. Biol. 47:60, 2017, Fig. 4. (b) Data from PDB ID 5FUR, R. K. Louder et al., Nature 531:604, 2016.]
| Transcription protein | Number of different subunits | Subunit(s) a | Function(s) |
|---|---|---|---|
| Initiation | |||
Pol II |
12 |
7,000–220,000 |
Catalyzes RNA synthesis |
TBP (TATA-binding protein) |
1 |
38,000 |
Specifically recognizes the TATA box |
TFIIA |
2 |
13,000, 42,000 |
Stabilizes binding of TFIIB and TBP to the promoter |
TFIIB |
1 |
35,000 |
Binds to TBP; recruits Pol II–TFIIF complex |
TFIIDb |
13–14 |
14,000–213,000 |
Required for initiation at promoters lacking a TATA box |
TFIIE |
2 |
33,000, 50,000 |
Recruits TFIIH; has ATPase and helicase activities |
TFIIF |
2–3 |
29,000–58,000 |
Binds tightly to Pol II; binds to TFIIB and prevents binding of Pol II to nonspecific DNA sequences |
TFIIH |
10 |
35,000–89,000 |
Unwinds DNA at promoter (helicase activity); phosphorylates Pol II CTD; recruits nucleotide-excision repair proteins |
| Elongationc | |||
ELLd |
1 |
80,000 |
|
pTEFb |
2 |
43,000, 124,000 |
Phosphorylates Pol II CTD |
SII (TFIIS) |
1 |
38,000 |
|
Elongin (SIII) |
3 |
15,000, 18,000, 110,000 |
|
a reflects the subunits present in the complexes of human cells. bThe presence of multiple copies of some TFIID subunits brings the total subunit composition of the complex to 21–22. cThe function of all elongation factors is to suppress the pausing or arrest of transcription by the Pol II–TFIIF complex. dName derived from eleven-nineteen lysine-rich leukemia. The gene for ELL is the site of chromosomal recombination events frequently associated with acute myeloid leukemia. |
|||
Assembly of RNA Polymerase and Transcription Factors at a Promoter
The formation of a closed complex begins when the TATA-binding protein (TBP) binds to the TATA box (Fig. 26-9a, step ). At promoters lacking a TATA box, TBP arrives as part of a multisubunit complex called TFIID. TBP is bound, in turn, by the transcription factor TFIIB. TFIIA then binds and, along with TFIIB, helps to stabilize the TBP-DNA complex. The TFIIB-TBP complex is next bound by another complex consisting of TFIIF and Pol II. TFIIF helps target Pol II to its promoters, both by interacting with TFIIB and by reducing the binding of the polymerase to nonspecific sites on the DNA. Finally, TFIIE and TFIIH bind to create the closed, preinitiation complex (PIC).
A key function of TFIID in the PIC is to position TBP on the promoter, which in turn dictates the location of Pol II loading and transcription initiation. Because most human promoters (~80%) lack a TATA box, how TFIID correctly positions TBP and Pol II relative to the transcription start site was poorly understood until their structures were determined by cryo-EM (Fig. 26-9b). These structures showed that TFIID binds the promoter DNA in an elongated complex that is anchored by TBP–DNA interactions on one end and extends linearly over 70 base pairs. The Inr sequence is positioned roughly in the middle, straddled on both ends by TFIID subunits. TFIID thus acts as a scaffold to direct binding of Pol II and other PIC components and uses its structure and interactions with TBP to help define the transcription start site.
TFIIH has multiple subunits and includes a DNA helicase activity that promotes the unwinding of DNA near the RNA start site (a process requiring the hydrolysis of ATP), thereby creating an open initiation complex (Fig. 26-9a, step ). Counting all the subunits of the various factors (including TFIIA and the subunits of TFIID), this active initiation complex can have more than 50 polypeptides.
 ). Counting all the subunits of the various factors (including TFIIA and the subunits of TFIID), this active initiation complex can have more than 50 polypeptides.
). Counting all the subunits of the various factors (including TFIIA and the subunits of TFIID), this active initiation complex can have more than 50 polypeptides.RNA Strand Initiation and Promoter Clearance
TFIIH has an additional function during the initiation phase. A kinase activity in one of its subunits phosphorylates Pol II at many places in the CTD (Fig. 26-9a, step ). Several other protein kinases, including CDK9 (cyclin-dependent kinase 9), which is part of the complex pTEFb (positive transcription elongation factor b), also phosphorylate the CTD, primarily on Ser residues of the CTD repeat sequence. CTD phosphorylation causes a conformational change in the overall complex, initiating transcription. During the subsequent elongation phase of transcription, the phosphorylation state of the CTD changes, affecting which RNA processing components are bound to the transcription complexes (Fig. 26-10).
 ). Several other protein kinases, including CDK9 (cyclin-dependent kinase 9), which is part of the complex pTEFb (positive transcription elongation factor b), also phosphorylate the CTD, primarily on Ser residues of the CTD repeat sequence. CTD phosphorylation causes a conformational change in the overall complex, initiating transcription. During the subsequent elongation phase of transcription, the phosphorylation state of the CTD changes, affecting which RNA processing components are bound to the transcription complexes (
). Several other protein kinases, including CDK9 (cyclin-dependent kinase 9), which is part of the complex pTEFb (positive transcription elongation factor b), also phosphorylate the CTD, primarily on Ser residues of the CTD repeat sequence. CTD phosphorylation causes a conformational change in the overall complex, initiating transcription. During the subsequent elongation phase of transcription, the phosphorylation state of the CTD changes, affecting which RNA processing components are bound to the transcription complexes (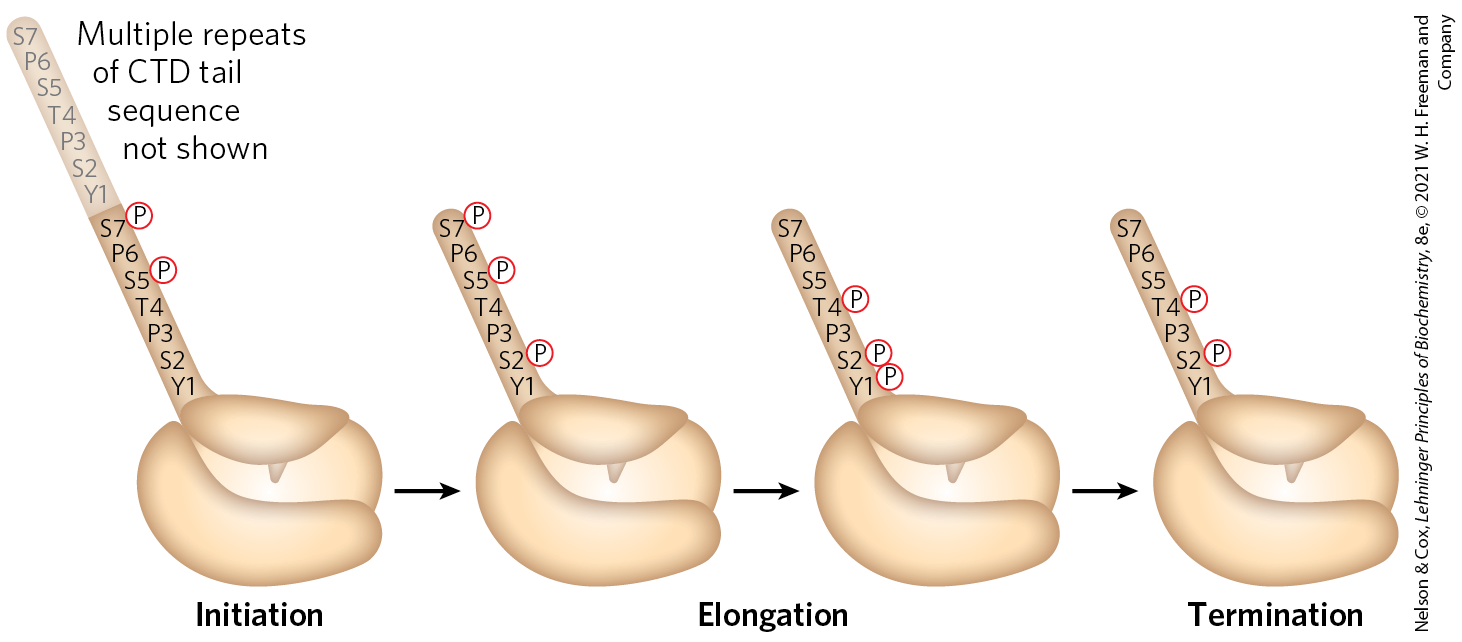
FIGURE 26-10 Phosphorylation of the carboxyl-terminal domain (CTD) of RNA polymerase II. The phosphorylation pattern of the CTD changes during different phases of transcription due to the action of kinases and phosphorylases associated with the transcription machinery. Multiple repeats of the CTD tail are phosphorylated with the patterns shown here during each stage; however, these are not shown for clarity. Understanding the patterns and heterogeneity of CTD tail phosphorylation at different stages of transcription and on different genes is an active area of transcription research.
During synthesis of the initial 60 to 70 nucleotides of RNA, first TFIIE, then TFIIH is released, and Pol II enters the elongation phase of transcription (Fig. 26-9a, step ).
Elongation, Termination, and Release
TFIIF remains associated with Pol II throughout elongation. During this stage, polymerase activity is greatly enhanced by protein elongation factors (Table 26-2). The elongation factors, some bound to the phosphorylated CTD, suppress pausing during transcription and also coordinate interactions between the supramolecular complexes involved in the posttranscriptional processing of mRNAs. Once the RNA transcript is completed, transcription is terminated (Fig. 26-9a, step ). The Pol II CTD is dephosphorylated and the transcription machinery recycled, ready to initiate another transcript.
Regulation of transcription at Pol II promoters is an elaborate process. It involves the interaction of a wide variety of other proteins with the preinitiation complex. Some of these regulatory proteins interact with transcription factors, others with Pol II itself. The regulation of eukaryotic transcription is described in more detail in Chapter 28.
RNA Polymerases Are Drug Targets
Both bacterial and eukaryotic RNA polymerases are the targets of a large number of chemical inhibitors. Some of these molecules inhibit transcription of both types of RNA polymerases; others selectively inhibit only certain types of polymerase.
The elongation of RNA strands by RNA polymerase in both bacteria and eukaryotes is inhibited by the antibiotic actinomycin D. The planar portion of this molecule inserts (intercalates) into the double-helical DNA between successive G≡C base pairs, deforming the DNA duplex. This prevents movement of the polymerase along the DNA during transcription. Because actinomycin D inhibits RNA elongation in intact cells as well as in cell extracts, it can be used to identify cell processes that depend on RNA synthesis.
Rifampin (Fig. 26-11a) inhibits bacterial RNA synthesis by preventing the promoter clearance step of transcription. Rifampin is an important antibiotic for the treatment of tuberculosis (TB), which is caused by the bacterium Mycobacterium tuberculosis and kills approximately 1.8 million people each year. The antibiotic binds near the active site of RNA polymerase and prevents extension of the RNA product beyond 2 to 3 nucleotides. Unfortunately, M. tuberculosis can develop resistance to rifampin; more than 600,000 cases of rifampin-resistant TB are reported each year. In many cases, resistance is due to mutation in the rifampin binding site (Fig. 26-11b), particularly at , , and of the β subunit. New drugs that inhibit M. tuberculosis RNA polymerase are desperately needed for treatment of drug-resistant TB.

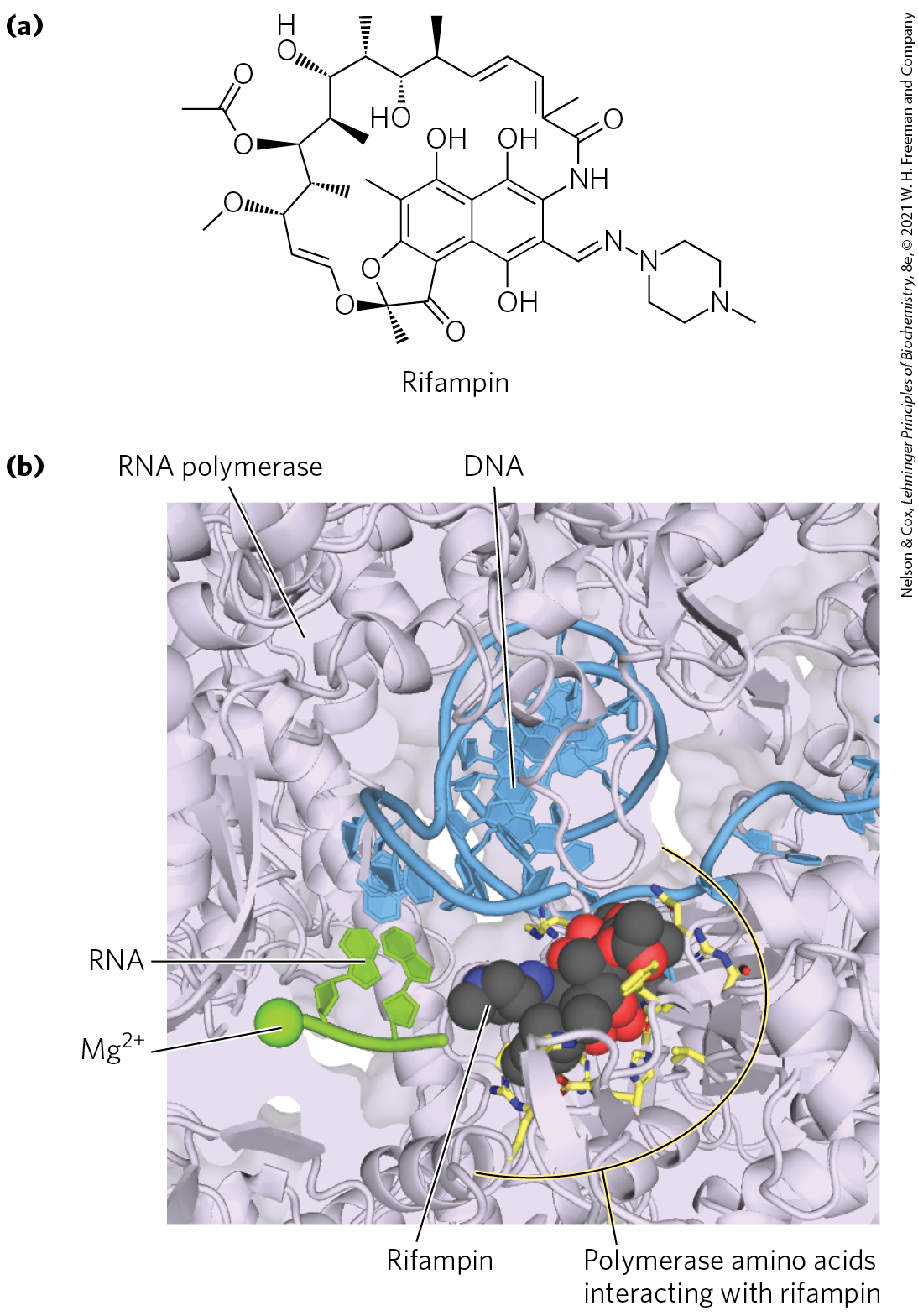
FIGURE 26-11 Inhibition of RNA polymerase by rifampin. (a) Chemical structure of rifampin. (b) X-ray crystallographic structure of rifampin bound to the active site of M. tuberculosis RNA polymerase. In this slab view, much of the surrounding polymerase has been removed so that active site details, including one of the essential ions, can be highlighted. Rifampin (shown in spacefill) binds within the active site and blocks extension of the RNA transcript. Many RNA polymerase amino acids make direct contact with rifampin, and mutation of these amino acids can result in rifampicin-resistant RNA polymerase and TB infection. [(b) Data from PDB ID 5UH6 and information from W. Lin et al., Mol. Cell 66:169, 2017.]
The death cap mushroom Amanita phalloides has a very effective defense mechanism against predators. It produces α-amanitin, which disrupts transcription in animal cells by blocking Pol II and, at higher concentrations, Pol III. Neither Pol I nor bacterial RNA polymerase is sensitive to α-amanitin — nor is the RNA polymerase II of A. phalloides itself. Because α-amanitin is selective for inhibiting the function of only certain RNA polymerases, it has proven useful for identifying the functions of different polymerases in the cell. Mitochondrial and bacterial RNA polymerases share significant similarities to one another, including α-amanitin resistance. By exposing eukaryotic cells to α-amanitin, it is possible to detect newly synthesized mRNAs that arise only from mitochondrial and not nuclear transcription. Researchers using α-amanitin need to exercise abundant caution because it is highly toxic to humans. An amount of -amanitin the size of a grain of rice contains a lethal dose.


Amanita phalloides, the death cap mushroom
SUMMARY 26.1 DNA-Dependent Synthesis of RNA
- Transcription is catalyzed by DNA-dependent RNA polymerases, which use ribonucleoside -triphosphates to synthesize RNA in the direction, complementary to the template strand of duplex DNA. Transcription occurs in several phases: binding of RNA polymerase to a DNA site called a promoter, initiation of transcript synthesis, elongation, and termination.
- RNA polymerases bind regions of DNA called promoters to initiate transcription of nearby genes. Promoter sequences help to establish the level of gene expression and in E. coli are recognized by variable RNA polymerase subunits called factors. Transcription initiation involves formation of the closed and open complexes. DNA is unwound in the open complex to allow it to serve as the transcription template.
- As the first committed steps in transcription, binding of RNA polymerase to the promoter and initiation of transcription are closely regulated.
- Bacterial transcription stops at sequences called terminators. E. coli commonly uses two types of termination signals: -dependent and -independent.
- Eukaryotic cells have three types of nuclear RNA polymerases. The vast majority of cellular mRNAs and ncRNAs are synthesized by Pol II.
- Binding of Pol II to its promoters requires an array of proteins called transcription factors. Ultimately, a large molecular complex called the preinitiation complex, PIC, forms at the promoter. Elongation factors participate in the elongation phase of transcription. The phosphorylation state of the long carboxyl-terminal domain of the largest Pol II subunit changes in the initiation and elongation phases and determines what components are part of the initiation and elongation complexes.
- RNA polymerases can be inhibited by a number of drugs, some of which are specific to either bacterial or eukaryotic polymerases. Drugs that inhibit bacterial RNA polymerase are commonly used to treat infections such as tuberculosis.
 Transcription is catalyzed by DNA-dependent RNA polymerases, which use ribonucleoside -triphosphates to synthesize RNA in the direction, complementary to the template strand of duplex DNA. Transcription occurs in several phases: binding of RNA polymerase to a DNA site called a promoter, initiation of transcript synthesis, elongation, and termination.
Transcription is catalyzed by DNA-dependent RNA polymerases, which use ribonucleoside -triphosphates to synthesize RNA in the direction, complementary to the template strand of duplex DNA. Transcription occurs in several phases: binding of RNA polymerase to a DNA site called a promoter, initiation of transcript synthesis, elongation, and termination.