28.1 The Proteins and RNAs of Gene Regulation
Transcription is mediated and regulated by protein-DNA interactions, especially those involving the protein components of RNA polymerase (Chapter 26). We first consider how the activity of RNA polymerase is regulated. Next, we proceed to a general description of the proteins participating in this regulation. We then examine the molecular basis for the recognition of specific DNA sequences by DNA-binding proteins. Regulatory RNAs are encountered most often in the regulation of mRNA translation in eukaryotes, but also play a role in the life of some bacterial mRNAs. We consider them briefly in this section, and in more detail in Section 28.3.
RNA Polymerase Binds to DNA at Promoters
RNA polymerases bind to DNA and initiate transcription at promoters (see Fig. 26-5), sites generally found near points at which RNA synthesis begins on the DNA template. The regulation of transcription initiation often entails changes in how RNA polymerase interacts with a promoter.
The nucleotide sequences of promoters vary considerably, affecting the binding affinity of RNA polymerases and thus the frequency of transcription initiation. Some Escherichia coli genes are transcribed once per second, others less than once per cell generation. Much of this variation is due to differences in promoter sequence. In the absence of regulatory proteins, differences in promoter sequence may affect the frequency of transcription initiation by a factor of 1,000 or more. Most E. coli promoters have a sequence close to a consensus (Fig. 28-2). Mutations that result in a shift away from the consensus sequence usually decrease the function of bacterial promoters; conversely, mutations toward consensus usually enhance promoter function.

FIGURE 28-2 Consensus sequence for many E. coli promoters. Most base substitutions in the and regions have a negative effect on promoter function. Some promoters also include the UP (upstream promoter) element.
Key convention
By convention, DNA sequences are shown as they exist in the nontemplate strand, with the terminus on the left. Nucleotides are numbered from the transcription start site, with positive numbers to the right (in the direction of transcription) and negative numbers to the left. N indicates any nucleotide.

Genes for products that are required at all times, such as those for the enzymes of central metabolic pathways, are expressed continuously, with little variation in virtually every cell of a species or organism. Such genes are often referred to as housekeeping genes. Expression of a gene at approximately constant levels is called constitutive gene expression. Although housekeeping genes are expressed constitutively, the cellular concentrations of the proteins they encode vary widely. For these genes, the RNA polymerase–promoter interaction strongly influences the rate of transcription initiation. Differences in promoter sequence may be the only level of regulation for a housekeeping gene, allowing the cell to synthesize the appropriate level of each housekeeping gene product.
The basal rate of transcription initiation at the promoters of nonhousekeeping genes is also determined by the promoter sequence, but expression of these genes is further modulated by regulatory proteins. Many of these proteins work by enhancing or interfering with the interaction between RNA polymerase and the promoter.
The sequences of eukaryotic promoters are much more variable than their bacterial counterparts. The three eukaryotic RNA polymerases usually require an array of general transcription factors in order to bind to a promoter, and these can heavily influence basal transcription rates. Yet, as with bacterial gene expression, the basal level of transcription is determined in part by the effect of promoter sequences on the function of RNA polymerase and its associated transcription factors.
Transcription Initiation Is Regulated by Proteins and RNAs
At least three types of regulatory proteins regulate transcription initiation by RNA polymerase: specificity factors alter the specificity of RNA polymerase for a given promoter or set of promoters, repressors impede access of RNA polymerase to the promoter, and activators enhance the RNA polymerase–promoter interaction.
 At least three types of regulatory proteins regulate transcription initiation by RNA polymerase: specificity factors alter the specificity of RNA polymerase for a given promoter or set of promoters, repressors impede access of RNA polymerase to the promoter, and
At least three types of regulatory proteins regulate transcription initiation by RNA polymerase: specificity factors alter the specificity of RNA polymerase for a given promoter or set of promoters, repressors impede access of RNA polymerase to the promoter, and As our understanding of the roles of protein regulators slowly matures, many new roles for gene regulation by noncoding RNAs (ncRNAs) are also beginning to emerge. Among these are the long noncoding RNAs (lncRNAs), generally defined as noncoding RNAs more than 200 nucleotides long that lack an open reading frame (ORF) that encodes a protein — thus distinguishing them from the small, functional ncRNAs (miRNA, snoRNA, snRNA, etc.) described in Chapter 26. The lncRNAs are found in all types of organisms, with tens of thousands expressed in mammalian cells. Known functions of lncRNAs include regulation of nucleosome positioning and chromatin structure, control of DNA methylation and posttranscriptional histone modifications, transcriptional gene silencing, multiple roles in transcriptional activation and repression, and much more.
We introduced bacterial specificity factors in Chapter 26, although we did not refer to these proteins by that name. The σ subunit of the E. coli RNA polymerase holoenzyme is a specificity factor that mediates promoter recognition and binding. Most E. coli promoters are recognized by a single σ subunit , (see Fig. 26-5). Under some conditions, some of the subunits are replaced by one of six other specificity factors. One notable case arises when bacteria are subjected to heat stress, leading to the replacement of by . When bound to , RNA polymerase is directed to a specialized set of promoters with a different consensus sequence (Fig. 28-3). These promoters control the expression of a set of genes that encode proteins, including some protein chaperones (p. 132), that are part of a stress-induced system called the heat shock response. Thus, through changes in the binding affinity of the polymerase that direct the enzyme to different promoters, a set of genes involved in related processes is coordinately regulated. In eukaryotic cells, some of the general transcription factors, in particular the TATA-binding protein (TBP; see Fig. 26-9), may be considered specificity factors.

FIGURE 28-3 Consensus sequence for promoters that regulate expression of the E. coli heat shock genes. This system responds to temperature increases as well as some other environmental stresses, resulting in the induction of a set of proteins. Binding of RNA polymerase to heat shock promoters is mediated by a specialized σ subunit of the polymerase, , which replaces in the RNA polymerase initiation complex.
Repressors bind to specific sites on the DNA. In bacterial cells, such binding sites, called operators, are generally near a promoter. RNA polymerase binding, or its movement along the DNA after binding, is blocked when the repressor is present. Regulation by means of a repressor protein that blocks transcription is referred to as negative regulation. Repressor binding to DNA is regulated by a molecular signal, or effector, usually a small molecule or a protein that binds to the repressor and causes a conformational change. The interaction between repressor and signal molecule either increases or decreases transcription. In some cases, the conformational change results in dissociation of a DNA-bound repressor from the operator (Fig. 28-4a). Transcription initiation can then proceed unhindered. In other cases, interaction between an inactive repressor and the signal molecule causes the repressor to bind to the operator (Fig. 28-4b). In eukaryotic cells, gene regulation by a repressor is less common. Where it does occur (more often in lower eukaryotes such as yeast), the binding site for a repressor may be some distance from the promoter. Binding of these repressors to their binding sites has the same effect as in bacterial cells: inhibiting the assembly or activity of a transcription complex at the promoter.
 Regulation by means of a repressor protein that blocks transcription is referred to as negative regulation. Repressor binding to DNA is regulated by a molecular signal, or effector, usually a small molecule or a protein that binds to the repressor and causes a conformational change. The interaction between repressor and signal molecule either increases or decreases transcription. In some cases, the conformational change results in dissociation of a DNA-bound repressor from the operator (
Regulation by means of a repressor protein that blocks transcription is referred to as negative regulation. Repressor binding to DNA is regulated by a molecular signal, or effector, usually a small molecule or a protein that binds to the repressor and causes a conformational change. The interaction between repressor and signal molecule either increases or decreases transcription. In some cases, the conformational change results in dissociation of a DNA-bound repressor from the operator ( In eukaryotic cells, gene regulation by a repressor is less common. Where it does occur (more often in lower eukaryotes such as yeast), the binding site for a repressor may be some distance from the promoter. Binding of these repressors to their binding sites has the same effect as in bacterial cells: inhibiting the assembly or activity of a transcription complex at the promoter.
In eukaryotic cells, gene regulation by a repressor is less common. Where it does occur (more often in lower eukaryotes such as yeast), the binding site for a repressor may be some distance from the promoter. Binding of these repressors to their binding sites has the same effect as in bacterial cells: inhibiting the assembly or activity of a transcription complex at the promoter.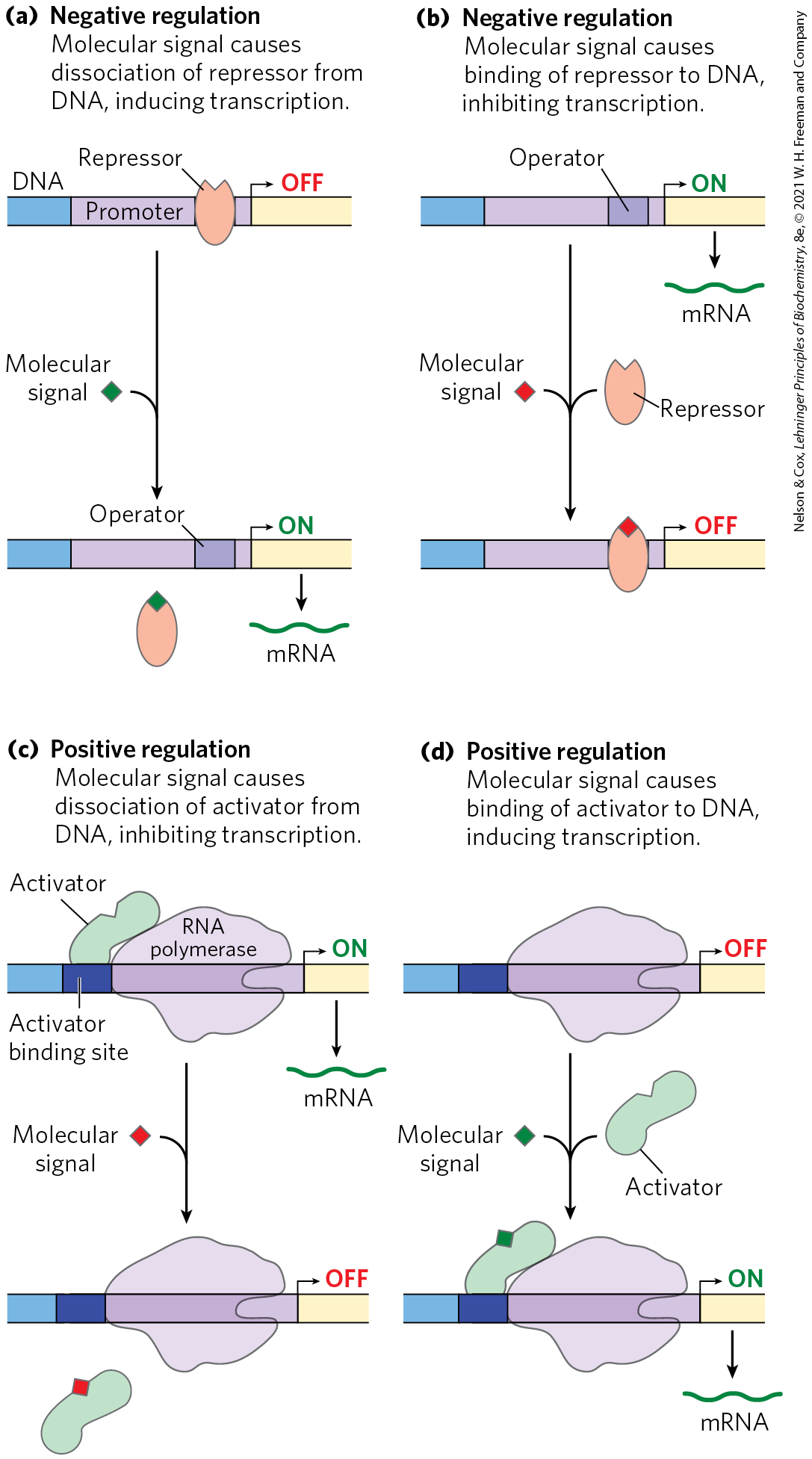
FIGURE 28-4 Common patterns of regulation of transcription initiation. Two types of negative regulation are illustrated. (a) Repressor binds to the operator in the absence of the molecular signal; the external signal causes dissociation of the repressor to permit transcription. (b) Repressor binds in the presence of the signal; the repressor dissociates, and transcription ensues when the signal is removed. Positive regulation is mediated by gene activators. Again, two types are shown. (c) Activator binds in the absence of the molecular signal and transcription proceeds; when the signal is added, the activator dissociates and transcription is inhibited. (d) Activator binds in the presence of the signal; it dissociates only when the signal is removed. Note that “positive” regulation and “negative” regulation refer to the type of regulatory protein involved: the bound protein either facilitates or inhibits transcription. In either case, addition of the molecular signal may increase or decrease transcription, depending on its effect on the regulatory protein.
Activators provide a molecular counterpoint to repressors; they bind to DNA and enhance the activity of RNA polymerase at a promoter; this is positive regulation. In bacteria, activator-binding sites are often adjacent to promoters that are bound weakly or not at all by RNA polymerase alone, such that little transcription occurs in the absence of the activator. Some activators are usually bound to DNA, enhancing transcription until dissociation of the activator is triggered by the binding of a signal molecule (Fig. 28-4c). In other cases the activator binds to DNA only after interaction with a signal molecule (Fig. 28-4d). Signal molecules can therefore increase or decrease transcription, depending on how they affect the activator.
Positive regulation by activators is particularly common in eukaryotes. Many eukaryotic activators bind to DNA sites, called enhancers, that are distant from the promoter, affecting the rate of transcription at a promoter that may be located thousands of base pairs away.
The distance between a promoter and the binding site of an activator or repressor is bridged by looping out of the DNA between the two sites (Fig. 28-5). The looping is facilitated in some cases by proteins called architectural regulators that bind to intervening sites. Interaction between activators and the RNA polymerase at the promoter is often mediated by intermediary proteins called coactivators. In some instances, protein repressors may take the place of coactivators, binding to the activators and preventing the activating interaction.
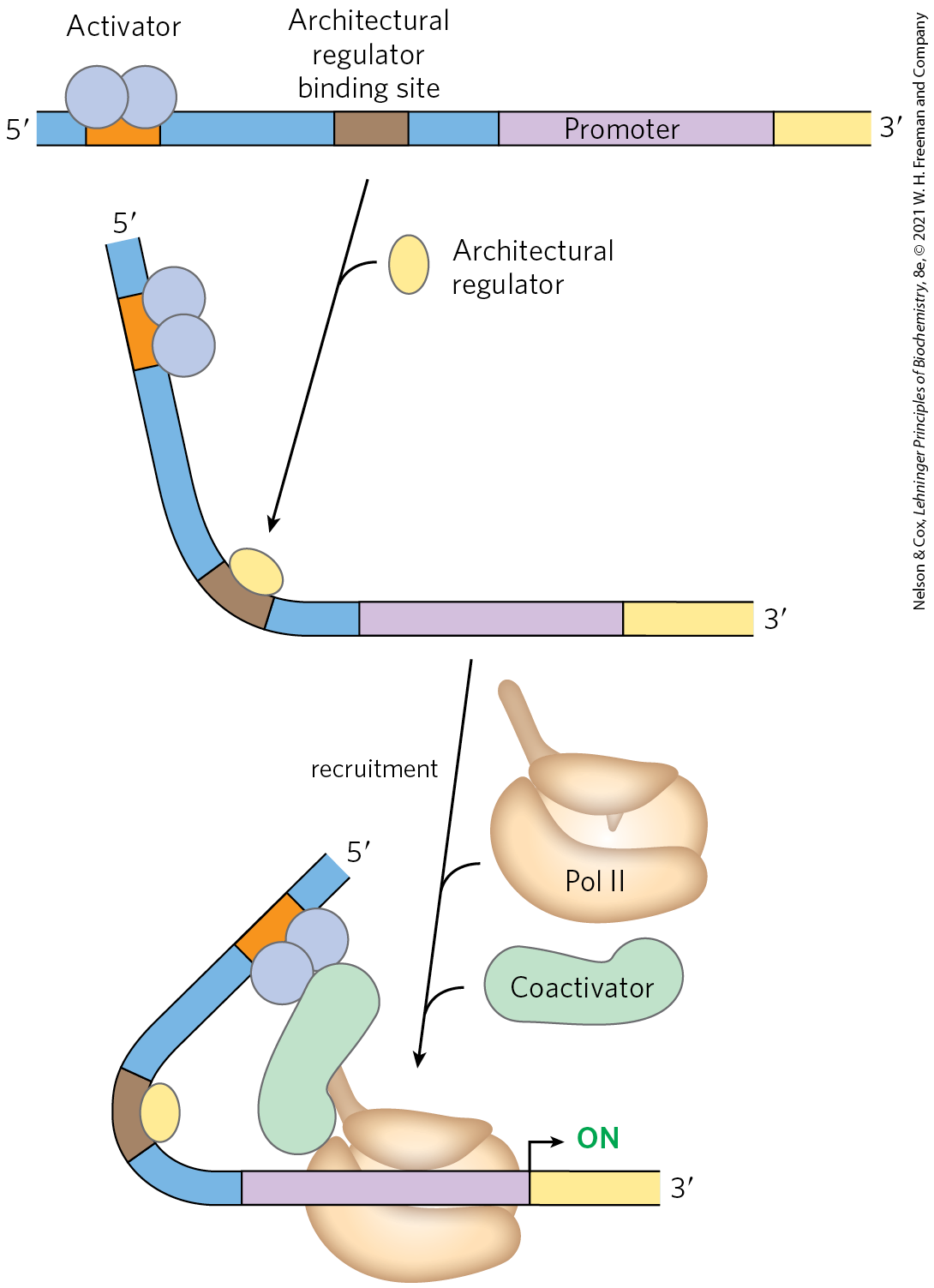
FIGURE 28-5 Interaction between activators/repressors and RNA polymerase in eukaryotes. Eukaryotic activators and repressors frequently bind sites thousands of base pairs distant from the promoters they regulate. DNA looping, often facilitated by architectural regulators, brings the sites together. The interaction between activators and RNA polymerase may be mediated by coactivators, as shown. Repression is sometimes mediated by repressors (described later) that bind to activators, thereby preventing the activating interaction with RNA polymerase.
Many Bacterial Genes Are Clustered and Regulated in Operons
Bacteria have a simple general mechanism for coordinating the regulation of multiple genes: these genes are clustered on the chromosome and are transcribed together. Many bacterial mRNAs are polycistronic — multiple genes on a single transcript — and the single promoter that initiates transcription of the cluster is the site of regulation for expression of all the genes in the cluster. The gene cluster and promoter, plus additional sequences that function together in regulation, are called an operon (Fig. 28-6). Operons that include two to six genes transcribed as a unit are common; some operons contain 20 or more genes. The identity and order of the genes in an operon are not random. In many cases, genes in the same operon encode subunits of a larger protein complex, and cotranslation directly enables assembly of the complex. Some operons organize genes involved in related processes that require coordinated regulation. In other cases, the genes may seem to be unrelated, but they encode products required by the cell under similar conditions.

FIGURE 28-6 Representative bacterial operon. Genes A, B, and C are transcribed on one polycistronic mRNA. Typical regulatory sequences include binding sites for proteins that either activate or repress transcription from the promoter.
Many of the principles of bacterial gene expression were first defined by studies of lactose metabolism in E. coli, which can use lactose as its sole carbon source. In 1960, François Jacob and Jacques Monod published a short paper in the Proceedings of the French Academy of Sciences that described how two adjacent genes involved in lactose metabolism were coordinately regulated by a genetic element located at one end of the gene cluster. The genes were those for β-galactosidase, which cleaves lactose to galactose and glucose, and for galactoside permease, which transports lactose into the cell (Fig. 28-7). The terms “operon” and “operator” were first introduced in this paper. With the operon model, gene regulation could, for the first time, be considered in molecular terms.
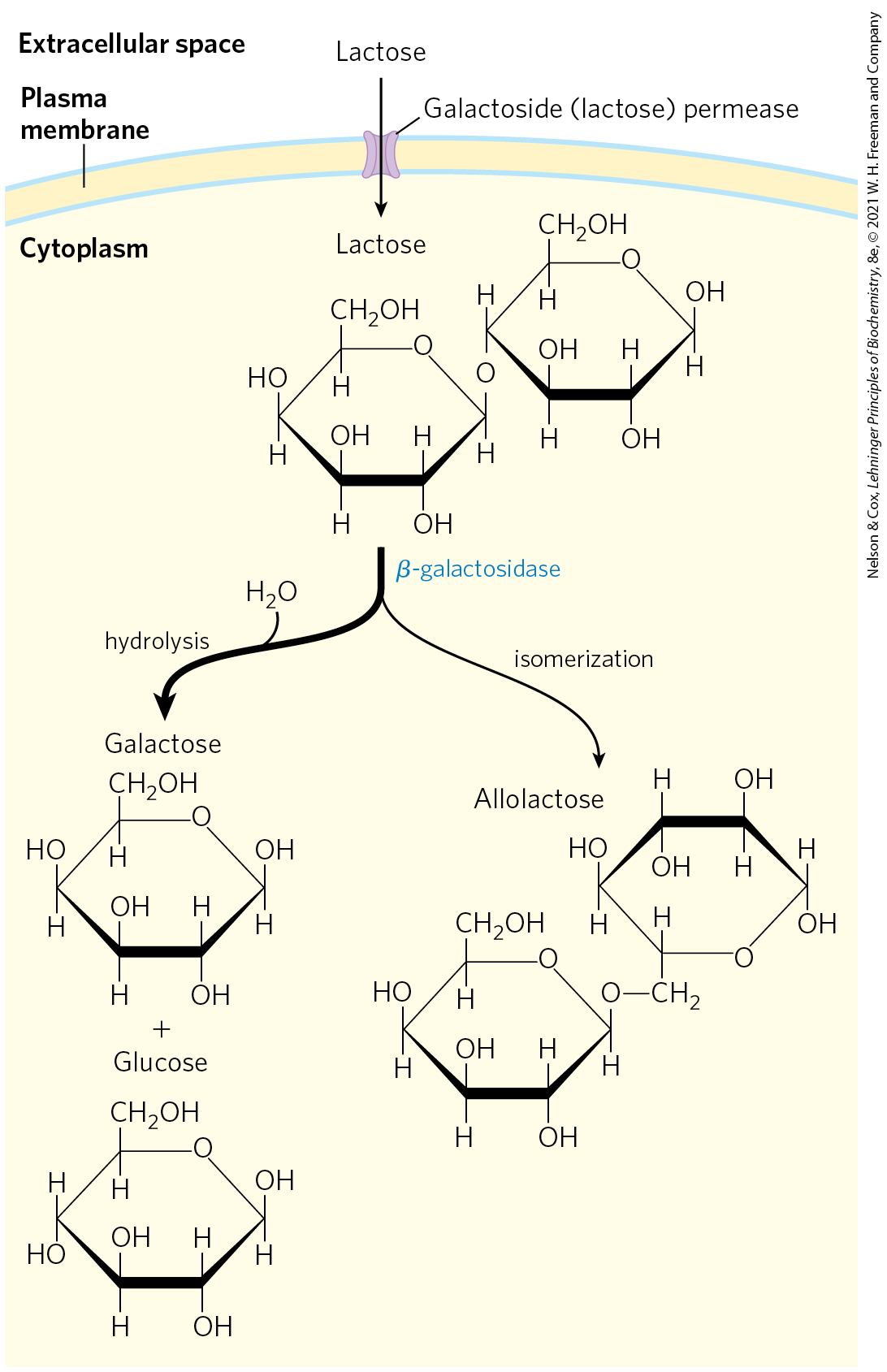
FIGURE 28-7 Lactose metabolism in E. coli. Uptake and metabolism of lactose require the activities of galactoside (lactose) permease and β-galactosidase. Conversion of lactose to allolactose by transglycosylation is a minor reaction also catalyzed by β-galactosidase.
The lac Operon Is Subject to Negative Regulation
The lactose (lac) operon (Fig. 28-8a) includes the genes for β-galactosidase (Z), galactoside permease (Y), and thiogalactoside transacetylase (A). The last of these enzymes seems to modify toxic galactosides to facilitate their removal from the cell. Each of the three genes is preceded by a ribosome-binding site (not shown in Fig. 28-8) that independently directs the translation of that gene (Chapter 27). Regulation of the lac operon by the lac repressor protein (Lac) follows the pattern outlined in Figure 28-4a.
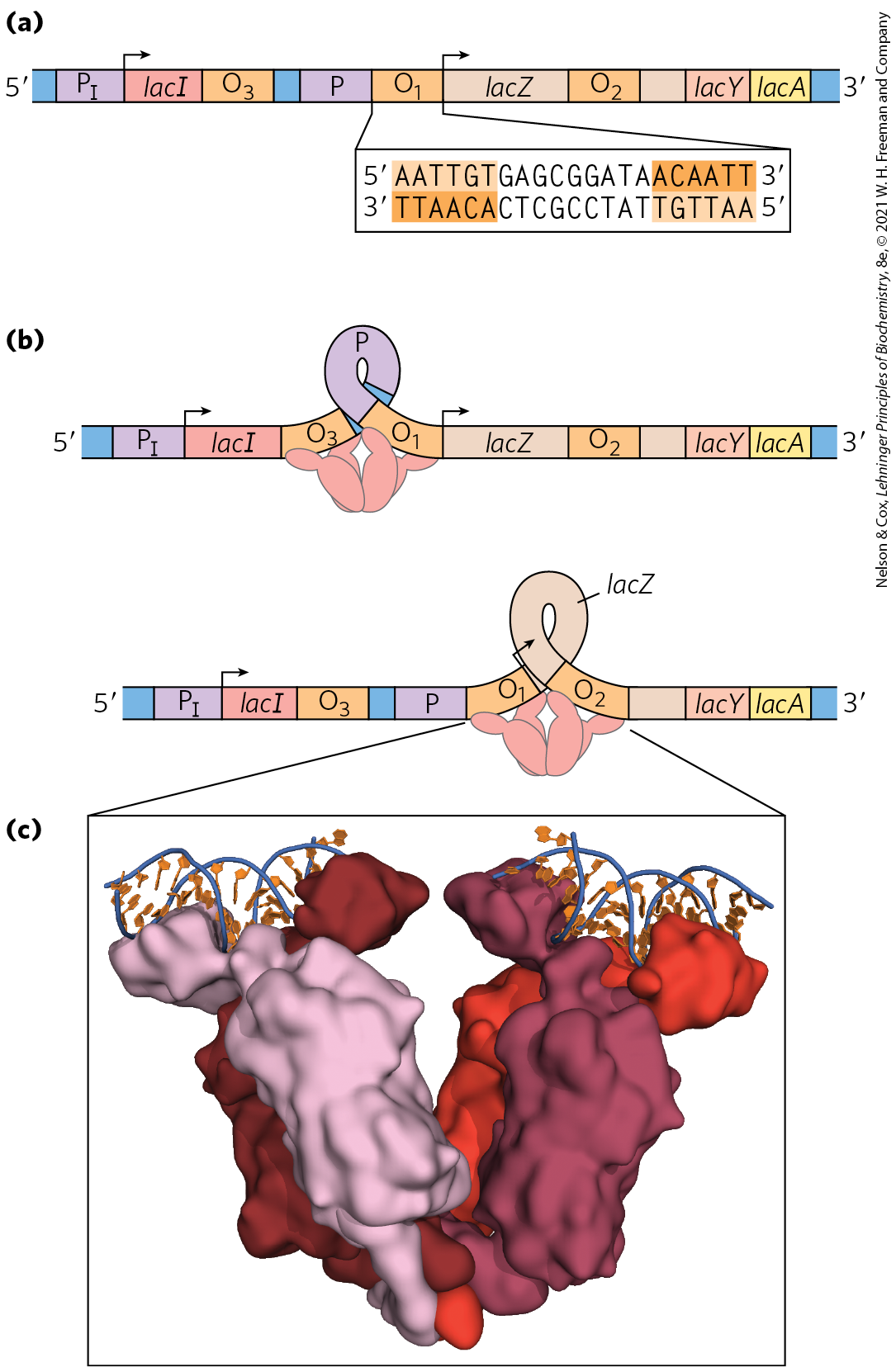
FIGURE 28-8 The lac operon. (a) In the lac operon, the lacI gene encodes the Lac repressor. The lac Z, Y, and A genes encode β-galactosidase, galactoside permease, and thiogalactoside transacetylase, respectively. P is the promoter for the lac genes, and is the promoter for the I gene. is the main operator for the lac operon; and are secondary operator sites of lesser affinity for the Lac repressor. The inverted repeat to which the Lac repressor binds in is shown. (b) The Lac repressor binds to the main operator and or , and it seems to form a loop in the DNA. (c) Lac repressor (shades of red) is shown bound to short, discontinuous segments of DNA (blue and orange). [(c) Data from PDB ID 2PE5, R. Daber et al., J. Mol. Biol. 370:609, 2007.]
The study of lac operon mutants has revealed some details of the workings of the operon’s regulatory system. In the absence of lactose, the lac operon genes are repressed. Mutations in the operator or in another gene, the I gene, result in constitutive synthesis of the gene products. When the I gene is defective, repression can be restored by introducing a functional I gene into the cell on another DNA molecule, demonstrating that the I gene encodes a diffusible molecule that causes gene repression. This molecule proved to be a protein, now called the Lac repressor, a tetramer of identical monomers. The operator to which it binds most tightly abuts the transcription start site (Fig. 28-8a). The I gene is transcribed from its own promoter independent of the lac operon genes. The lac operon has two secondary binding sites for the Lac repressor: and . is centered near position , within the gene encoding β-galactosidase (Z); is near position , within the I gene. To repress the operon, the Lac repressor seems to bind to both the main operator and one of the two secondary sites, with the intervening DNA looped out (Fig. 28-8b, c). Either binding arrangement blocks transcription initiation.
Despite this elaborate binding complex, repression is not absolute. Binding of the Lac repressor reduces the rate of transcription initiation by a factor of . If the and sites are eliminated by deletion or mutation, the binding of repressor to alone reduces transcription by a factor of about . Even in the repressed state, each cell has a few molecules of β-galactosidase and galactoside permease, presumably synthesized on the rare occasions when the repressor transiently dissociates from the operators. This basal level of transcription is essential to operon regulation.
When cells are provided with lactose, the lac operon is induced. An inducer (signal) molecule binds to a specific site on the Lac repressor, causing a conformational change that results in dissociation of the repressor from the operator. The inducer in the lac operon system is not lactose itself but allolactose, an isomer of lactose (Fig. 28-7). After entry into the E. coli cell (via the few preexisting molecules of lactose permease), lactose is converted to allolactose by one of the few preexisting β-galactosidase molecules. Release of the operator by Lac repressor, triggered as the repressor binds to allolactose, allows expression of the lac operon genes and leads to a -fold increase in the concentration of β-galactosidase.
Several β-galactosides structurally related to allolactose are inducers of the lac operon but are not substrates for β-galactosidase; others are substrates but not inducers. One particularly effective and nonmetabolizable inducer of the lac operon that is often used experimentally is isopropylthiogalactoside (IPTG).
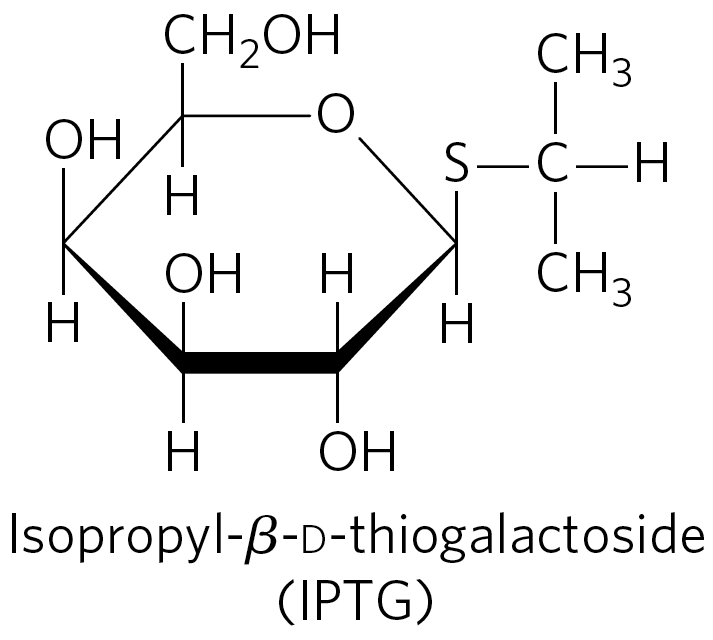
An inducer that cannot be metabolized allows researchers to explore the physiological function of lactose as a carbon source for growth, separate from its function in the regulation of gene expression.
In addition to the multitude of operons now known in bacteria, a few polycistronic operons have been found in the cells of lower eukaryotes. In the cells of higher eukaryotes, however, almost all protein-coding genes are transcribed separately.
The mechanisms by which operons are regulated can vary significantly from the simple model presented in Figure 28-8. Even the lac operon is more complex than indicated here, with an activator also contributing to the overall scheme, as we shall see in Section 28.2. Before any further discussion of the layers of regulation of gene expression, however, we examine the critical molecular interactions between DNA-binding proteins (such as repressors and activators) and the DNA sequences to which they bind.
Regulatory Proteins Have Discrete DNA-Binding Domains
Regulatory proteins generally bind to specific DNA sequences. Their affinity for these target sequences is roughly to times higher than their affinity for any other DNA sequence. Most regulatory proteins have discrete DNA-binding domains containing substructures that interact closely and specifically with the DNA. These binding domains usually include one or more of a relatively small group of recognizable and characteristic structural motifs.
To bind specifically to DNA sequences, regulatory proteins must recognize surface features on the DNA (see Fig. 8-13). Most of the chemical groups that differ among the four bases and thus permit discrimination between base pairs are hydrogen-bond donor and acceptor groups exposed in the major groove of DNA (Fig. 28-9), and most of the protein-DNA contacts that impart specificity are hydrogen bonds. A notable exception is the nonpolar surface near C-5 of pyrimidines, where thymine is readily distinguished from cytosine by its protruding methyl group. Protein-DNA contacts are also possible in the minor groove of the DNA, but the hydrogen-bonding patterns there generally do not allow ready discrimination between base pairs.
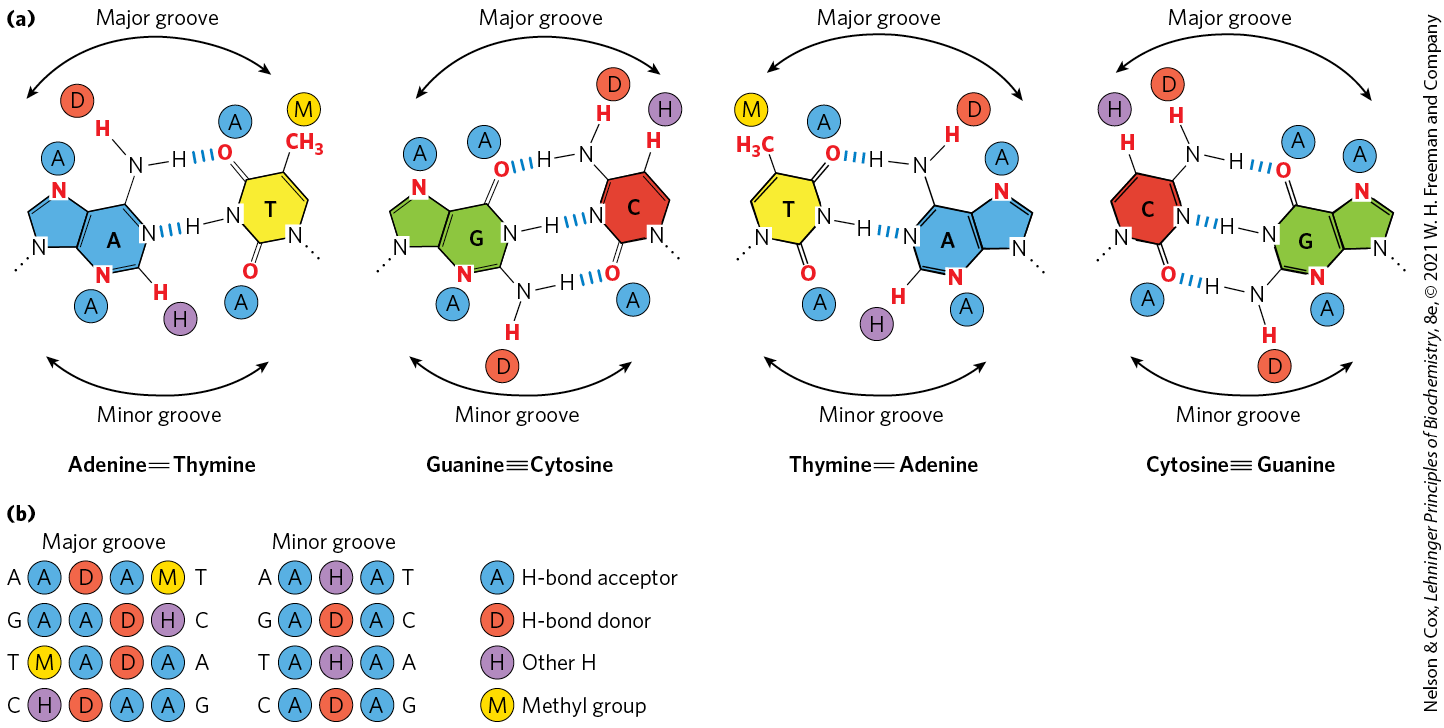
FIGURE 28-9 Groups in DNA available for protein binding. (a) Shown here are functional groups on all four base pairs that are displayed in the major and minor grooves of DNA. Hydrogen-bond acceptor (A) and donor (D) atoms are marked by blue and red disks, respectively. Other hydrogen atoms (H) are marked with purple disks, and methyl groups (M) with yellow disks. (b) Recognition patterns for each base pair (from left to right). The much greater variation in the patterns for the major groove gives rise to a much greater discriminatory power in the major groove relative to the minor groove. [Information from J. L. Huret, Atlas Genet. Cytogenet. Oncol. Haematol. 2006, http://atlasgeneticsoncology.org/Educ/DNAEngID30001ES.html.]
Within regulatory proteins, the amino acid side chains most often hydrogen-bonding to bases in the DNA are those of Asn, Gln, Glu, Lys, and Arg residues. Is there a simple recognition code in which a particular amino acid always pairs with a particular base? The two hydrogen bonds that can form between Gln or Asn and the and N-7 positions of adenine cannot form with any other base. And an Arg residue can form two hydrogen bonds with N-7 and of guanine (Fig. 28-10). Examination of the structure of many DNA-binding proteins, however, has shown that a protein can recognize each base pair in more than one way, leading to the conclusion that there is no simple amino acid–base code. For some proteins, the Gln-adenine interaction can specify base pairs, but in others a van der Waals pocket for the methyl group of thymine can recognize base pairs. Researchers cannot yet examine the structure of a DNA-binding protein and infer the DNA sequence to which it binds.
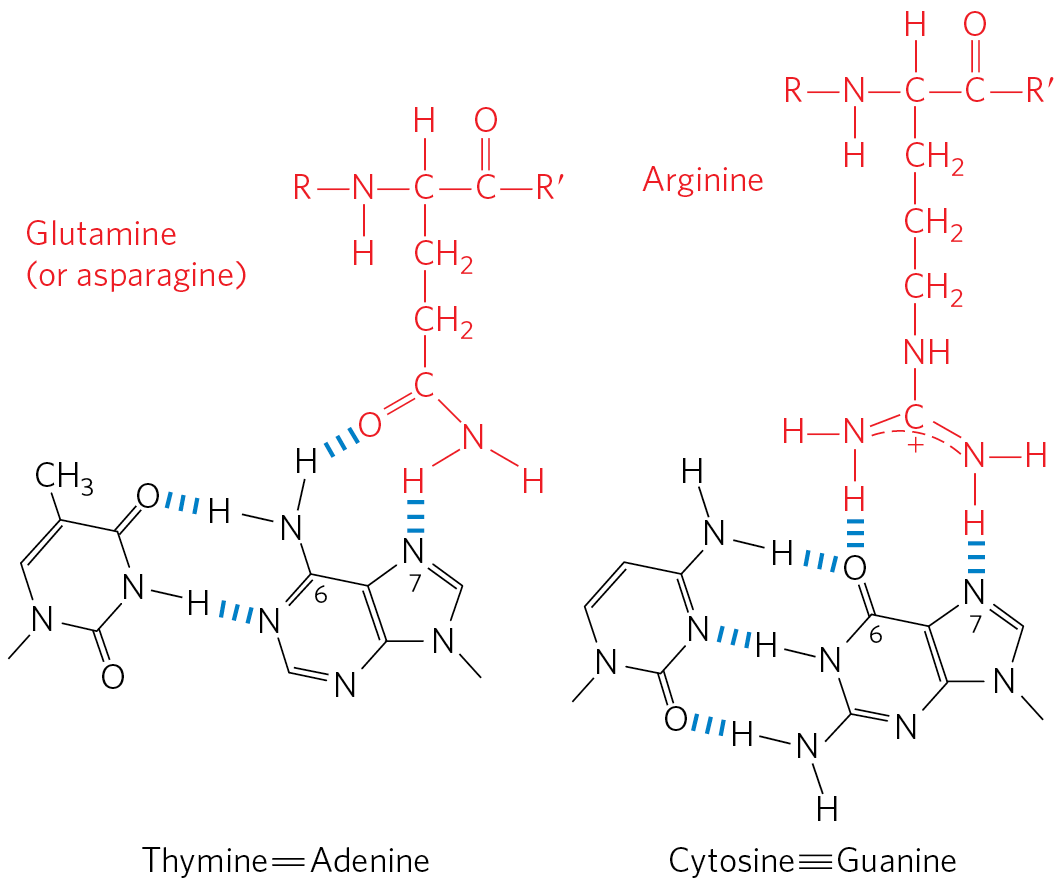
FIGURE 28-10 Specific amino acid residue–base pair interactions. The two examples shown have been observed in DNA-protein binding.
To interact with bases in the major groove of DNA, a protein requires a relatively small substructure that can stably protrude from the protein surface. The DNA-binding domains of regulatory proteins tend to be small (60 to 90 amino acid residues), and the structural motifs within these domains that are actually in contact with the DNA are smaller still. Many small proteins are unstable because of their limited capacity to form layers of structure to bury hydrophobic groups. The DNA-binding motifs provide either a very compact stable structure or a way of allowing a segment of protein to protrude from the protein surface.
The DNA-binding sites for regulatory proteins are often inverted repeats of a short DNA sequence (a palindrome) at which multiple (usually two) subunits of a regulatory protein bind cooperatively. The Lac repressor is unusual in that it functions as a tetramer, with two dimers tethered together at the end distant from the DNA-binding sites (Fig. 28-8b). An E. coli cell usually contains about 20 tetramers of the Lac repressor. Each of the tethered dimers separately binds to a palindromic operator sequence, in contact with 17 bp of a 22 bp region in the lac operon. And each of the tethered dimers can independently bind to an operator sequence, with one generally binding to and the other to or (as in Fig. 28-8b). The symmetry of the operator sequence corresponds to the twofold axis of symmetry of two paired Lac repressor subunits. The tetrameric Lac repressor binds to its operator sequences in vivo with an estimated dissociation constant of . The repressor discriminates between the operators and other sequences by a factor of about , so binding to these few base pairs among the 4.6 million or so of the E. coli chromosome is highly specific.
Several DNA-binding motifs have been described, but here we focus on two that play prominent roles in the binding of DNA by regulatory proteins from all domains of life: the helix-turn-helix and the zinc finger. We also consider two other types of such motifs: the homeodomain and the RNA recognition motif, which, as its name implies, also binds RNA; both motifs play prominent roles in some eukaryotic regulatory proteins.
Helix-Turn-Helix
The helix-turn-helix motif is crucial to the interaction of many regulatory proteins with DNA in bacteria, and similar motifs occur in some eukaryotic regulatory proteins. The helix-turn-helix comprises about 20 amino acid residues in two short α-helical segments, each 7 to 9 residues long, separated by a β turn (Fig. 28-11). This structure generally is not stable by itself; it is simply the interactive portion of a somewhat larger DNA-binding domain. One of the two α-helical segments is called the recognition helix, because it usually contains many of the amino acids that interact with DNA in a sequence-specific way. This α helix is stacked on other segments of the protein structure so that it protrudes from the protein surface. When bound to DNA, the recognition helix is positioned in or nearly in the major groove. The Lac repressor has this DNA-binding motif.
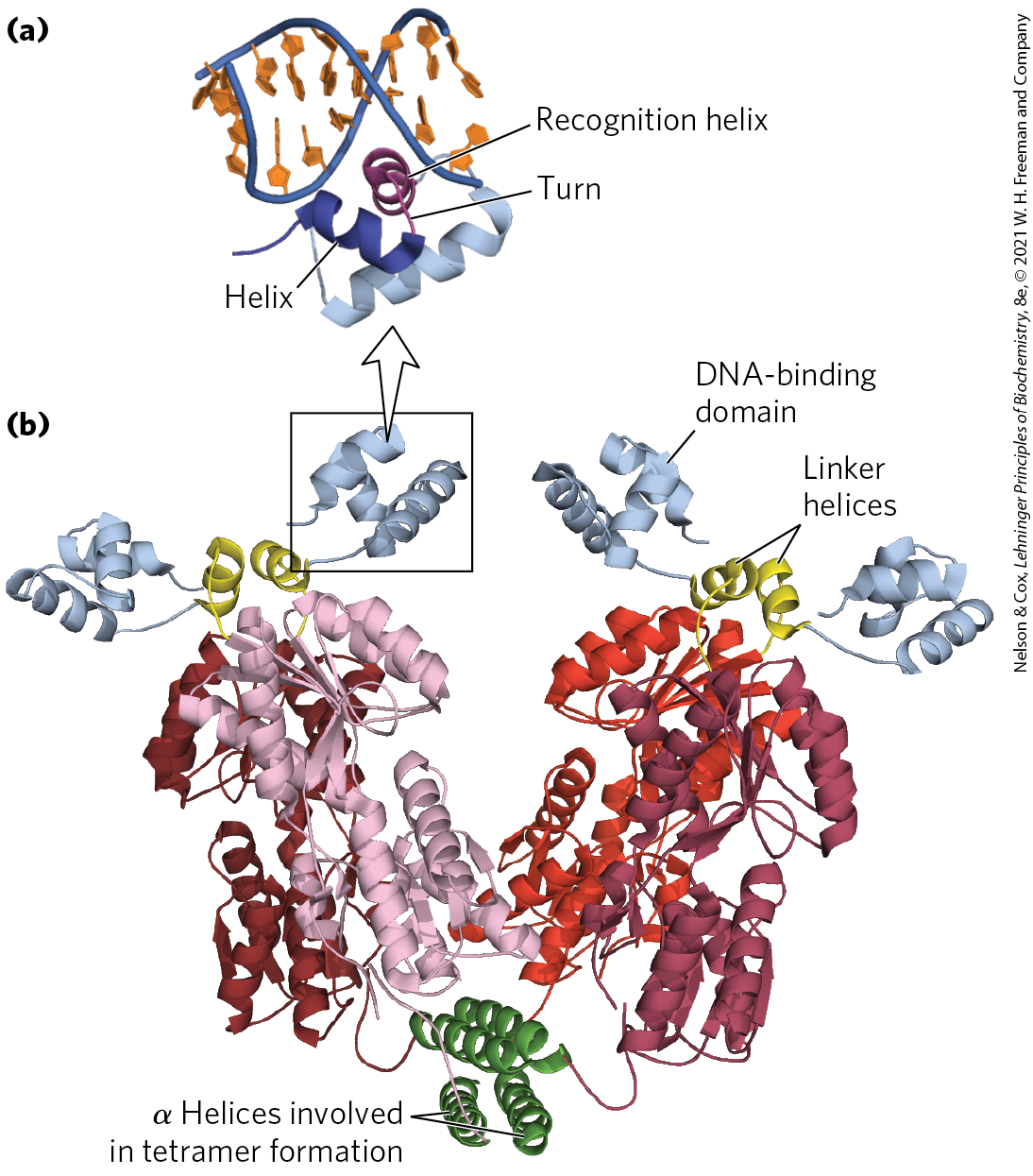
FIGURE 28-11 Helix-turn-helix. (a) DNA-binding domain of the Lac repressor bound to DNA. (b) The entire Lac repressor. The DNA-binding domains and the α helices involved in tetramer formation are labeled. The remainder of the protein has the binding sites for allolactose. The allolactose-binding domains are linked to the DNA-binding domains through linker helices. [Data from PDB ID 2PE5, R. Daber et al., J. Mol. Biol. 370:609, 2007.]
Zinc Finger
In a zinc finger, about 30 amino acid residues form an elongated loop held together at the base by a single ion, which is coordinated to 4 of the residues (4 Cys, or 2 Cys and 2 His). The zinc does not itself interact with DNA; rather, the coordination of zinc with the amino acid residues stabilizes this small structural motif. Several hydrophobic side chains in the core of the structure also lend stability. Figure 28-12 shows the interaction between DNA and three zinc fingers of a single polypeptide from the mouse regulatory protein Zif268.
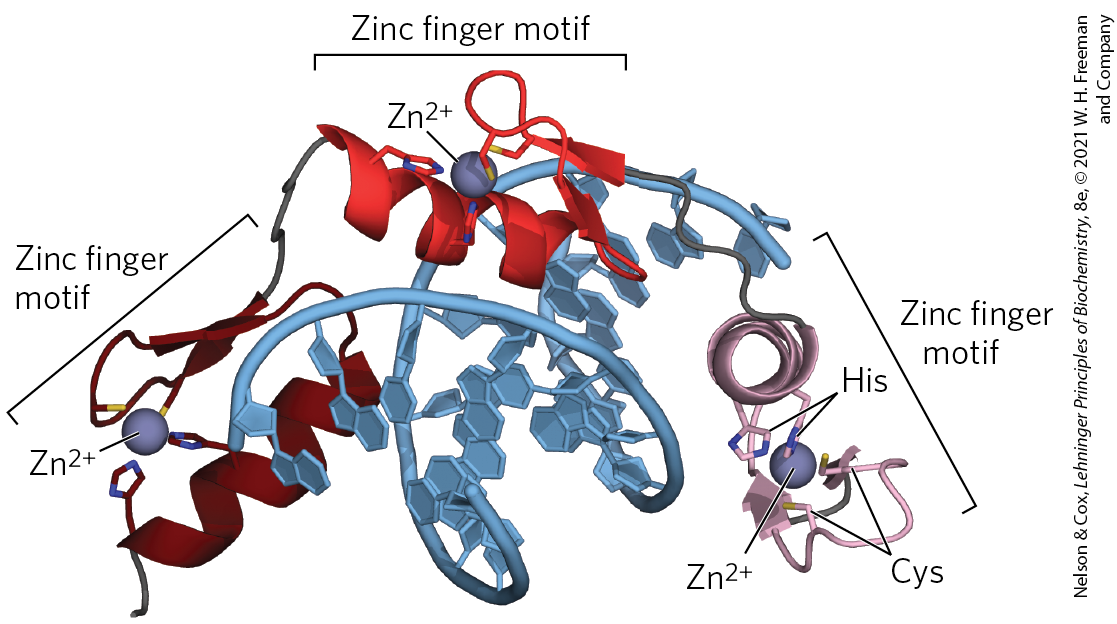
FIGURE 28-12 Zinc fingers. Three zinc fingers of the regulatory protein Zif268, complexed with DNA. Each coordinates with two His and two Cys residues. [Data from PDB ID 1ZAA, N. P. Pavletich and C. O. Pabo, Science 252:809, 1991.]
Many eukaryotic DNA-binding proteins contain zinc fingers. The interaction of a single zinc finger with DNA is typically weak, and many DNA-binding proteins, like Zif268, have multiple zinc fingers that substantially enhance binding by interacting simultaneously with the DNA. One DNA-binding protein of the frog Xenopus has 37 zinc fingers. There are few known examples of the zinc finger motif in bacterial proteins.
The precise manner in which proteins with zinc fingers bind to DNA differs from one protein to the next. Some zinc fingers contain the amino acid residues that are important in sequence discrimination, whereas others seem to bind DNA nonspecifically (the amino acids required for specificity are located elsewhere in the protein). Zinc fingers can also function as RNA-binding motifs, such as in certain proteins that bind eukaryotic mRNAs and act as translational repressors. We discuss this role later (Section 28.3).
Homeodomain
Another type of DNA-binding domain has been identified in some proteins that function as transcriptional regulators, especially during eukaryotic development. This domain of 60 amino acid residues — called the homeodomain, because it was discovered in homeotic genes (genes that regulate the development of body patterns) — is highly conserved and has now been identified in proteins from a wide variety of organisms, including humans (Fig. 28-13). The DNA-binding segment of the domain is related to the helix-turn-helix motif. The DNA sequence that encodes this domain is known as the homeobox.
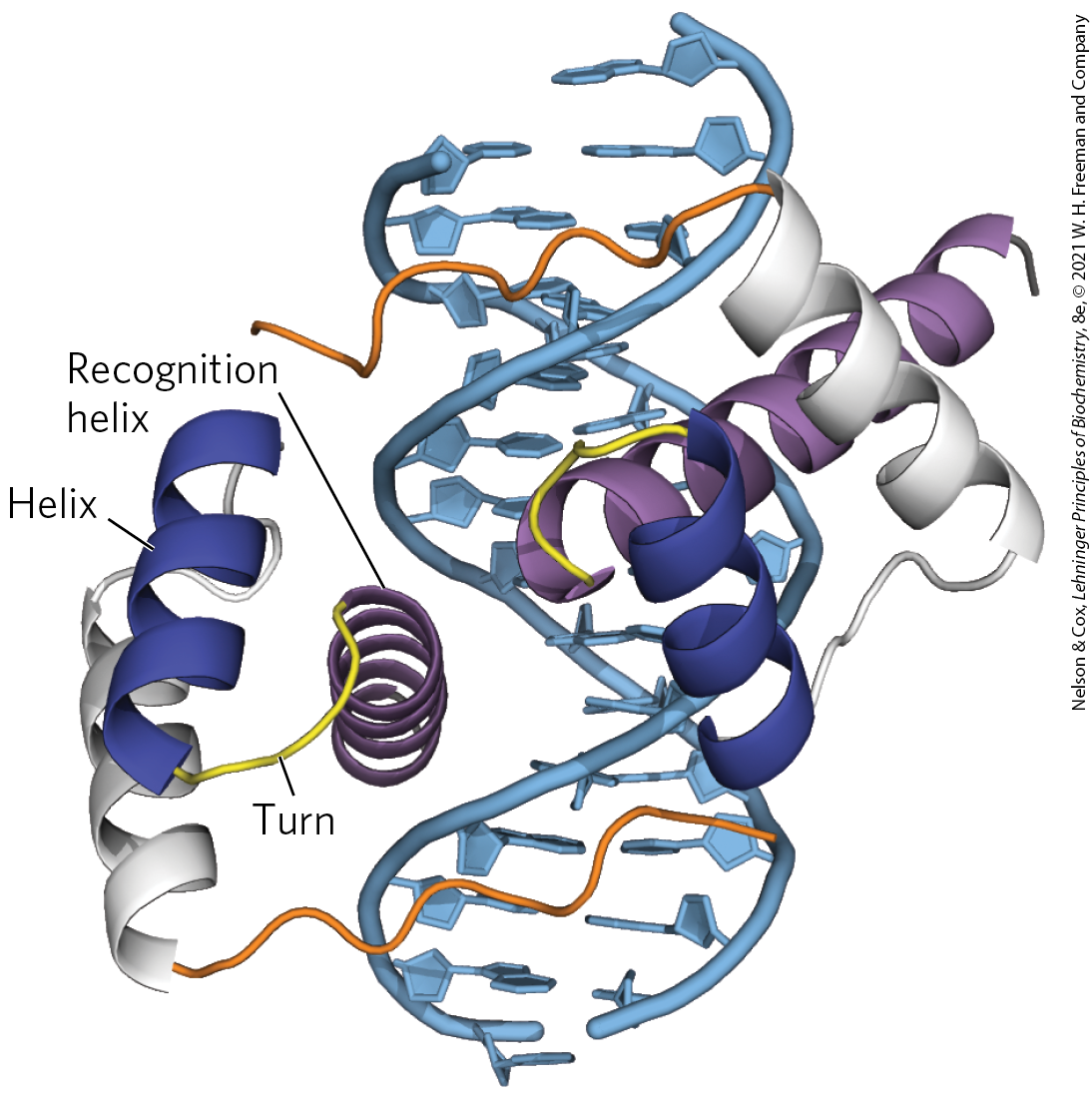
FIGURE 28-13 Homeodomains. Shown here are two homeodomains bound to DNA. In each homeodomain, the recognition helix, layered on two others, can be seen protruding into the major groove. This is only a small part of a larger regulatory protein from a class called Pax, active in the regulation of development in fruit flies (see Section 28.3). [Data from PDB ID 1FJL, D. S. Wilson et al., Cell 82:709, 1995.]
RNA Recognition Motif
New classes of proteins with RNA-binding domains continue to be identified. RNA recognition motifs (RRMs) are found in some eukaryotic gene activators, where they may do double duty in binding DNA and RNA. When bound to specific binding sites in DNA, these activators induce transcription. The same activators are sometimes regulated in part by specific lncRNAs that compete with DNA binding and decrease gene transcription. Other proteins with RRM motifs bind to mRNA, rRNA, or any of a range of other smaller, noncoding RNAs. The RRM consists of 90 to 100 amino acid residues, arranged in a four-strand antiparallel β sheet sandwiched against two α helices, with a topology (Fig. 28-14a). This motif may be present as part of DNA-binding regulatory proteins that also have other DNA-binding motifs or may occur in proteins that bind uniquely to RNA. The RRM is just one of many diverse protein motifs known to interact with RNA (Fig. 28-14b).
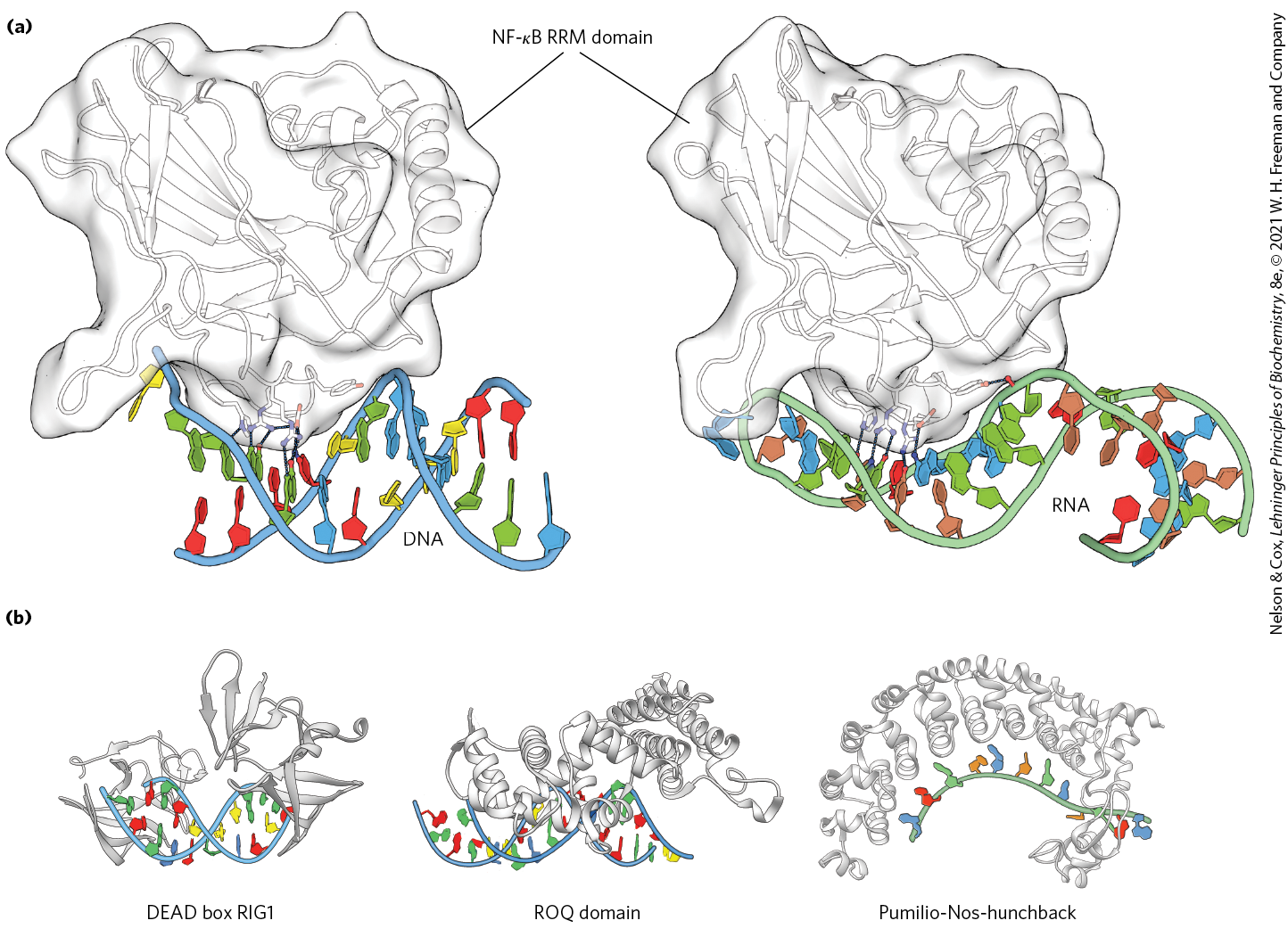
FIGURE 28-14 RNA recognition motifs (RRMs). (a) An RRM from the p50 subunit of regulatory protein is shown, bound to (left) DNA and (right) RNA. Black lines indicate hydrogen-bonding interactions between particular amino acid residues and bases in the DNA or RNA. is the name of a family of structurally related eukaryotic transcription factors that regulate processes ranging from immune and inflammatory responses to cell growth and apoptosis. (b) Three additional RRM motifs from widespread RNA-binding protein families. [(a) Data from (left) PDB ID 1OOA, D. B. Huang et al., Proc. Natl. Acad. Sci. USA 100:9268, 2003; (right) PDB ID 1VKX, F. E. Chen et al., Nature 391:410, 1998. (b) DEAD box RIG1: PDB ID 3LRR, C. Lu et al., Structure 18:1032, 2010; ROQ domain: PDB ID 4QIK, D. Tan et al., Nat. Struct. Mol. Biol. 21:679, 2014; Pumilio-Nos-hunchback: PDB ID 5KL1, C. A. Weidmann et al., eLife 5, 2016.]
Regulatory Proteins Also Have Protein-Protein Interaction Domains
Regulatory proteins contain domains not only for DNA binding but also for protein-protein interactions — with RNA polymerase, other regulatory proteins, or other subunits of the same regulatory protein. Examples include many eukaryotic transcription factors that function as gene activators, which often bind as dimers to the DNA through DNA-binding domains that contain zinc fingers. Some structural domains are devoted to the interactions required for dimer formation, which is generally a prerequisite for DNA binding. Like DNA-binding motifs, the structural motifs that mediate protein-protein interactions tend to fall within one of a few common categories. Two important examples are the leucine zipper and the basic helix-loop-helix. Structural motifs such as these are the basis for classifying some regulatory proteins into structural families.
Leucine Zipper
The leucine zipper is an amphipathic α helix with a series of hydrophobic amino acid residues concentrated on one side (Fig. 28-15), with the hydrophobic surface forming the area of contact between the two polypeptides of a dimer. A striking feature of these α helices is the occurrence of Leu residues at every seventh position, forming a straight line along the hydrophobic surface. Although researchers initially thought the Leu residues interdigitated (hence the name “zipper”), we now know that they line up, side by side, as the interacting α helices coil around each other (forming a coiled coil; Fig. 28-15b). Regulatory proteins with leucine zippers often have a separate DNA-binding domain with a high concentration of basic (Lys or Arg) residues that can interact with the negatively charged phosphates of the DNA backbone. Leucine zippers have been found in many eukaryotic proteins and a few bacterial proteins.
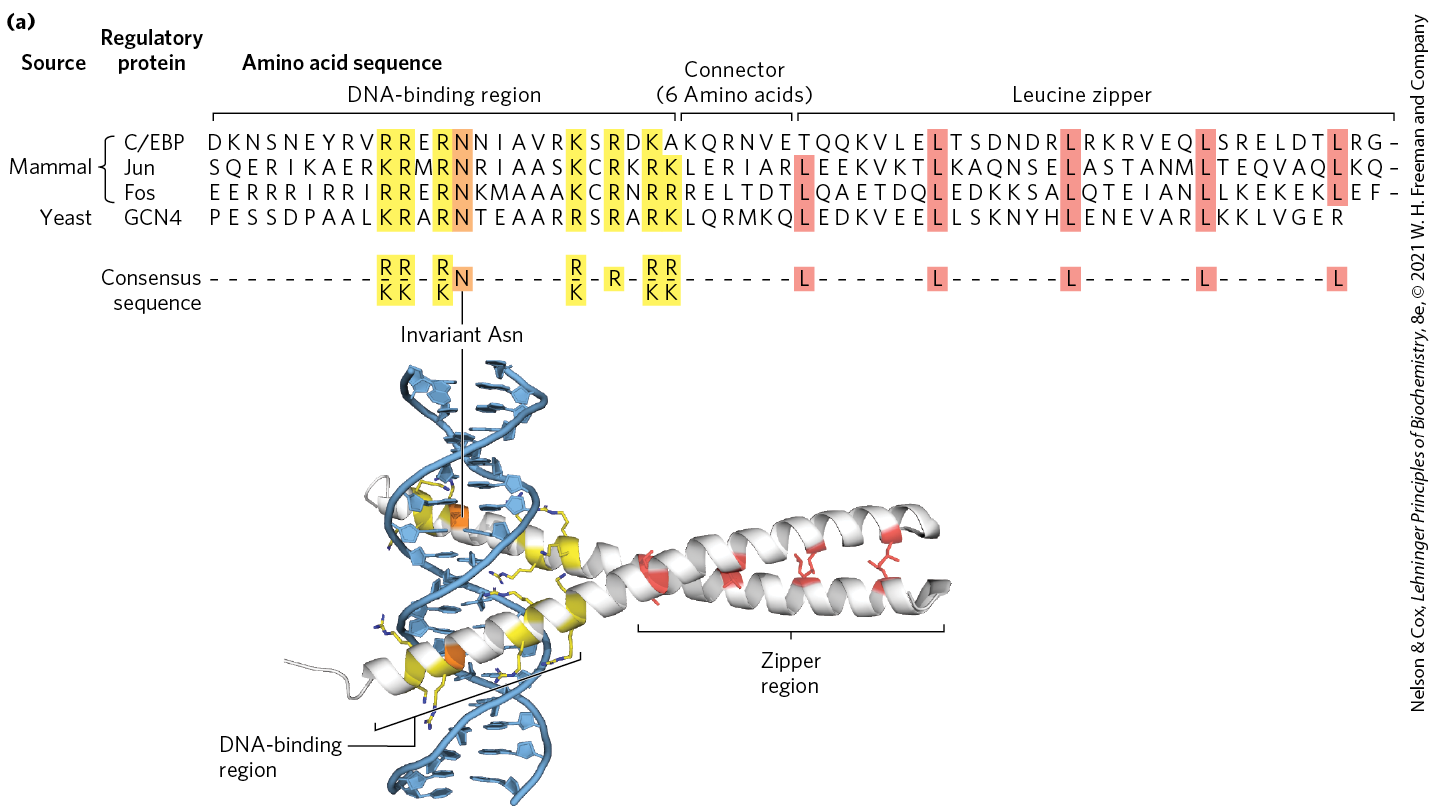
FIGURE 28-15 Leucine zippers. (a) Comparison of amino acid sequences of several leucine zipper proteins. Notice the Leu (L) residues (shaded) at every seventh position in the zipper region, and the number of Lys (K) and Arg (R) residues in the DNA-binding region. (b) Leucine zipper from the yeast activator protein GCN4. Only the “zippered” α helices, derived from different subunits of the dimeric protein, are shown. The two helices wrap around each other in a gently coiled coil. The interacting Leu side chains and the conserved residues in the DNA-binding region are highlighted to correspond to the sequence in (a). [(a) Information from S. L. McKnight, Sci. Am. 264 (April):54, 1991. (b) Data from PDB ID 1YSA, T. E. Ellenberger et al., Cell 71:1223, 1992.]
Basic Helix-Loop-Helix
Another common structural motif, the basic helix-loop-helix, occurs in some eukaryotic regulatory proteins implicated in the control of gene expression during development of multicellular organisms. These proteins share a conserved region of about 50 amino acid residues important in both DNA binding and protein dimerization. This region can form two short, amphipathic α helices linked by a loop of variable length, the helix-loop-helix (distinct from the helix-turn-helix motif associated with DNA binding). The helix-loop-helix motifs of two polypeptides interact to form dimers (Fig. 28-16). In these proteins, DNA binding is mediated by an adjacent short amino acid sequence rich in basic residues, similar to the separate DNA-binding region in proteins containing leucine zippers.
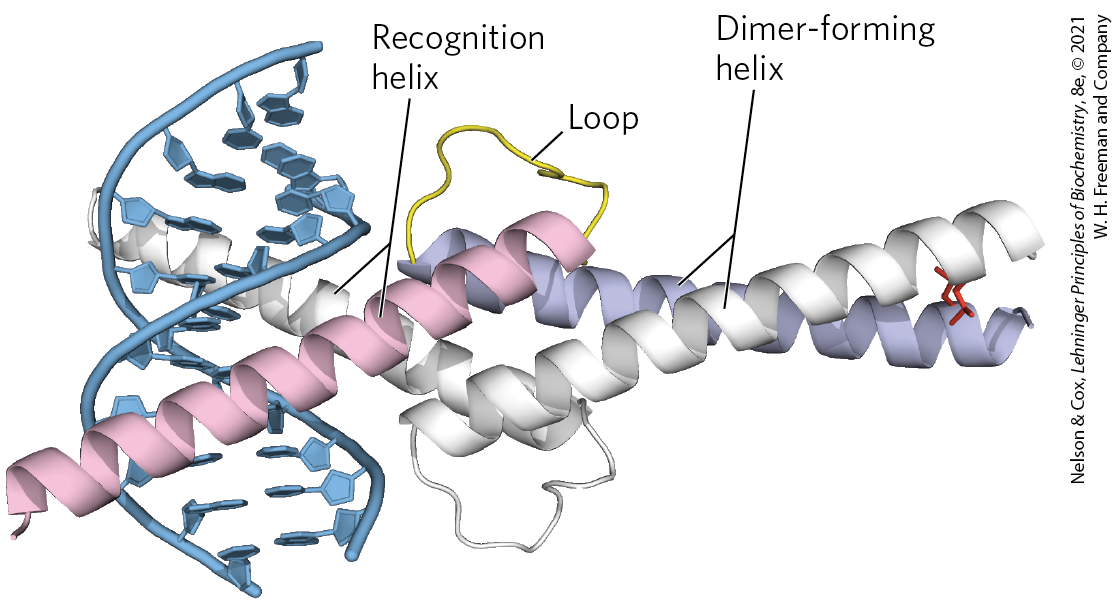
FIGURE 28-16 Helix-loop-helix. The human transcription factor Max, bound to its DNA target site. The protein is dimeric; one subunit is colored. The recognition helix is linked via the loop to the dimer-forming helix, which merges with the carboxyl-terminal end of the subunit. Interaction of the carboxyl-terminal helices of the two subunits describes a coiled coil very similar to that of a leucine zipper (see Fig. 28-15b), but with only one pair of interacting Leu residues (side chains at the right) in this example. The overall structure is sometimes called a helix-loop-helix/leucine zipper motif. [Data from PDB ID 1HLO, P. Brownlie et al., Structure 5:509, 1997.]
Protein-Protein Interactions in Eukaryotic Regulatory Proteins
In eukaryotes, most genes are regulated by activators, and most genes are monocistronic. If a different activator were required for each gene, the number of activators (and genes encoding them) would need to be equivalent to the number of regulated genes. However, in yeast, about 300 transcription factors (many of them activators) are responsible for the regulation of many thousands of genes. Many of the transcription factors regulate the induction of multiple genes, but most genes are subject to regulation by multiple transcription factors. Appropriate regulation of different genes is accomplished by different combinations of a limited repertoire of transcription factors at each gene, a mechanism referred to as combinatorial control.
Combinatorial control is accomplished in part by mixing and matching the variants within a regulatory protein family to form a series of different active protein dimers. Several families of eukaryotic transcription factors have been defined on the basis of close structural similarities. Within each family, dimers can sometimes form between two identical proteins (a homodimer) or between two different members of the family (a heterodimer). A hypothetical family of four different leucine-zipper proteins could thus form up to 10 different dimeric species. In many cases, the different combinations have distinct regulatory and functional properties and regulate different genes. As we shall see, multiple regulatory proteins of this kind function in the regulation of most eukaryotic genes, further contributing to combinatorial control.
In addition to having structural domains devoted to DNA binding and protein dimerization, which direct a particular protein dimer to a particular gene, many regulatory proteins have domains that interact with RNA polymerase, with regulatory RNAs, with unrelated regulatory proteins, or with some combination of the three. At least three types of additional domains for protein-protein interaction have been characterized (primarily in eukaryotes): glutamine-rich, proline-rich, and acidic domains, the names reflecting the amino acid residues that are especially abundant.
Protein-DNA and protein-RNA binding interactions are the basis of the intricate regulatory circuits fundamental to gene function. We now turn to a closer examination of these gene regulatory schemes, first in bacteria, then in eukaryotes.
SUMMARY 28.1 The Proteins and RNAs of Gene Regulation
- Transcription is initiated when an RNA polymerase interacts with a site called a promoter. In bacteria, the frequency of transcription initiation is dictated in part by sequence changes within the promoter. For gene products required all the time at a defined level — the products of housekeeping genes — the promoter sequence may be the sole element of regulation. For genes encoding products that are not always needed, regulation is imposed by additional proteins and RNAs.
- Regulation of gene transcription is imposed primarily by three types of proteins: specificity factors, repressors, and activators. Regulatory RNAs also play an important role in regulating the expression of many genes.
- In bacteria, genes that encode products with interdependent functions are often clustered in an operon, a single transcriptional unit. Transcription of the genes is generally blocked by binding of a specific repressor protein at a DNA site called an operator. Dissociation of the repressor from the operator is mediated by a specific small molecule, an inducer.
- Many principles of gene regulation in bacteria were first elucidated in studies of the lactose (lac) operon. The Lac repressor dissociates from the lac operator when the repressor binds to its inducer, allolactose.
- Regulatory proteins are DNA-binding proteins that recognize specific DNA sequences; most have distinct DNA-binding domains. Within these domains, common structural motifs that bind DNA (and/or RNA) are the helix-turn-helix, zinc finger, homeodomain, and RNA recognition motif.
- Regulatory proteins often contain domains such as the leucine zipper and helix-loop-helix, required for dimerization or other protein-protein interactions, and other motifs required for activation of transcription. Mixing and matching of protein family variants in dimeric transcription factors provides for more efficient and responsive regulation through combinatorial control.
 Transcription is initiated when an RNA polymerase interacts with a site called a promoter. In bacteria, the frequency of transcription initiation is dictated in part by sequence changes within the promoter. For gene products required all the time at a defined level — the products of housekeeping genes — the promoter sequence may be the sole element of regulation. For genes encoding products that are not always needed, regulation is imposed by additional proteins and RNAs.
Transcription is initiated when an RNA polymerase interacts with a site called a promoter. In bacteria, the frequency of transcription initiation is dictated in part by sequence changes within the promoter. For gene products required all the time at a defined level — the products of housekeeping genes — the promoter sequence may be the sole element of regulation. For genes encoding products that are not always needed, regulation is imposed by additional proteins and RNAs.