Chapter Review
Key Terms
Terms in bold are defined in the glossary.
- proteostasis
- translation
- aminoacyl-tRNA
- aminoacyl-tRNA synthetases
- codon
- reading frame
- initiation codon
- termination codons
- open reading frame (ORF)
- degenerate code
- anticodon
- wobble
- translational frameshifting
- RNA editing
- initiation
- Shine-Dalgarno sequence
- aminoacyl (A) site
- peptidyl (P) site
- exit (E) site
- initiation complex
- elongation
- elongation factors
- peptidyl transferase
- translocation
- termination
- termination factors
- release factors
- polysome
- posttranslational modification
- puromycin
- tetracycline
- chloramphenicol
- cycloheximide
- streptomycin
- diphtheria toxin
- ricin
- signal sequence
- signal recognition particle (SRP)
- peptide translocation complex
- tunicamycin
- nuclear localization sequence (NLS)
- coated pits
- clathrin
- dynamin
- ubiquitin
- proteasome
Problems
1. Messenger RNA Translation Predict the amino acid sequences of peptides formed by ribosomes in response to each mRNA sequence, assuming that the reading frame begins with the first three bases in each sequence.
- GGUCAGUCGCUCCUGAUU
- UUGGAUGCGCCAUAAUUUGCU
- CAUGAUGCCUGUUGCUAC
- AUGGACGAA
2. How Many Different mRNA Sequences Can Specify One Amino Acid Sequence? Write all the possible mRNA sequences that can code for the simple tripeptide segment Leu–Met–Tyr. Your answer will give you some idea of the number of possible mRNAs that can code for one polypeptide.
3. Can the Base Sequence of an mRNA Be Predicted from the Amino Acid Sequence of Its Polypeptide Product? A given sequence of bases in an mRNA will code for one and only one sequence of amino acids in a polypeptide, if the reading frame is specified. From a given sequence of amino acid residues in a protein such as cytochrome c, can we predict the base sequence of the unique mRNA that encoded it? Give reasons for your answer.
4. Coding of a Polypeptide by Duplex DNA The template strand of a segment of double-helical DNA contains the sequence
- What is the base sequence of the mRNA that can be transcribed from this strand?
- What amino acid sequence could be coded by the mRNA in (a), starting from the end?
- If the complementary (nontemplate) strand of this DNA were transcribed and translated, would the resulting amino acid sequence be the same as in (b)? Explain the biological significance of your answer.
5. The Genetic Code and Mutation A mutation occasionally arises that converts a codon specifying an amino acid to a stop or nonsense codon. When this occurs in the middle of a gene, the resulting protein is truncated and often inactive. If the protein is essential, cell death can result. Which of these secondary mutations might restore some or all of the protein function so that the cell can survive (there may be more than one correct answer)?
- A mutation restoring the codon to one encoding the original amino acid
- A mutation changing the nonsense codon to one encoding a different but similar amino acid
- A mutation in the anticodon of a tRNA such that the tRNA now recognizes the nonsense codon
- A mutation in which an additional nucleotide inserts just upstream of the nonsense codon, changing the reading frame so the nonsense codon is no longer read as “stop”
6. The Direction of Protein Synthesis In 1961, Howard Dintzis established that protein synthesis on ribosomes begins at the amino terminus and proceeds toward the carboxyl terminus. He used immature red blood cells that were still synthesizing hemoglobin. He added radioactively labeled leucine (chosen because it occurs frequently in both the α and β subunits) for various lengths of time, rapidly isolated only the full-length (completed) α subunits, and then determined where in the peptide the labeled amino acids were located. After the labeled leucine and extract had been incubated together for one hour, the protein was labeled uniformly along its length. However, after much shorter incubation times, the labeled amino acids were clustered at one end. At which end, amino or carboxyl terminus, did Dintzis find the labeled residues after the short exposure to labeled leucine?
7. Methionine Has Only One Codon Methionine is one of two amino acids with only one codon. How does the single codon for methionine specify both the initiating residue and the interior Met residues of polypeptides synthesized by E. coli?
8. The Genetic Code in Action Translate the mRNA shown, starting at the first nucleotide, assuming that translation occurs in an E. coli cell. If all tRNAs make maximum use of wobble rules but do not contain inosine, how many distinct tRNAs are required to translate this RNA?
9. Synthetic mRNAs The genetic code was elucidated through the use of polyribonucleotides synthesized either enzymatically or chemically in the laboratory. Given what we now know about the genetic code, how would you make a polyribonucleotide that could serve as an mRNA coding predominantly for many Phe residues and for a small number of Leu and Ser residues? What other amino acid(s) would be encoded by this polyribonucleotide, but in smaller amounts?
10. Energy Cost of Protein Biosynthesis Determine the minimum energy cost, in terms of ATP equivalents expended, for the biosynthesis of the β-globin chain of hemoglobin (146 residues), starting from a pool including all necessary amino acids, ATP, and GTP. Compare your answer with the direct energy cost of the biosynthesis of a linear glycogen chain of 146 glucose residues in linkage, starting from a pool including glucose, UTP, and ATP. From your data, what is the extra energy cost of making a protein, in which all the residues are ordered in a specific sequence, compared with the cost of making a polysaccharide containing the same number of residues but lacking the informational content of the protein?
In addition to the direct energy cost for the synthesis of a protein, there are indirect energy costs — those required for the cell to make the necessary enzymes for protein synthesis. Compare the magnitude of the indirect costs to a eukaryotic cell of the biosynthesis of linear glycogen chains and the biosynthesis of polypeptides, in terms of the enzymatic machinery involved.
11. Predicting Anticodons from Codons Most amino acids have more than one codon and attach to more than one tRNA, each with a different anticodon. Write all possible anticodons for the four codons of glycine: , GGC, GGA, and GGG.
- From your answer, which of the positions in the anticodons are primary determinants of their codon specificity in the case of glycine?
- Which of these anticodon-codon pairings has/have a wobbly base pair?
- In which of the anticodon-codon pairings do all three positions exhibit strong Watson-Crick hydrogen bonding?
12. Effect of Single-Base Changes on Amino Acid Sequence Much important confirmatory evidence on the genetic code has come from assessing changes in the amino acid sequence of mutant proteins after a single base has been changed in the gene that encodes the protein. Which of the listed amino acid replacements would be consistent with the genetic code if the replacements were caused by a single base change? Which cannot be the result of a single-base mutation? Why?
13. Resistance of the Genetic Code to Mutation The RNA sequence shown represents the beginning of an open reading frame (ORF). What changes (if any) can occur at each position without generating a change in the encoded amino acid residue?
14. Basis of the Sickle Cell Mutation Sickle cell hemoglobin has a Val residue at position 6 of the β-globin chain instead of the Glu residue found in normal hemoglobin A. Can you predict what change took place in the DNA codon for glutamate to account for replacement of the Glu residue by Val?
15. Proofreading by Aminoacyl-tRNA Synthetases The isoleucyl-tRNA synthetase has a proofreading function that ensures the fidelity of the aminoacylation reaction, but the histidyl-tRNA synthetase lacks such a proofreading function. Explain.
16. Importance of the “Second Genetic Code” Some aminoacyl-tRNA synthetases do not recognize and bind the anticodon of their cognate tRNAs but instead use other structural features of the tRNAs to impart binding specificity. The tRNAs for alanine apparently fall into this category.
- What features of does Ala-tRNA synthetase recognize?
- Describe the consequences of a mutation in the third position of the anticodon of .
- What other kinds of mutations might have similar effects?
- Mutations of these types are never found in natural populations of organisms. Why? (Hint: Consider what might happen both to individual proteins and to the organism as a whole.)
17. Rate of Protein Synthesis A bacterial ribosome can synthesize about 20 peptide bonds per minute. If the average bacterial protein is approximately 260 amino acid residues long, how many proteins can the ribosomes in an E. coli cell synthesize in 20 minutes if all ribosomes are functioning at maximum rates?
18. The Role of Translation Factors A researcher isolates mutant variants of the bacterial translation factors IF2, EF-Tu, and EF-G. In each case, the mutation allows proper folding of the protein and the binding of GTP but does not allow GTP hydrolysis. At what stage would translation be blocked by each mutant protein?
19. Maintaining the Fidelity of Protein Synthesis The chemical mechanisms used to avoid errors in protein synthesis are different from those used during DNA replication. DNA polymerases use a exonuclease proofreading activity to remove mispaired nucleotides incorrectly inserted into a growing DNA strand. There is no analogous proofreading function on ribosomes, and, in fact, the identity of an amino acid attached to an incoming tRNA and added to the growing polypeptide is never checked. A proofreading step that hydrolyzed the previously formed peptide bond after insertion of an incorrect amino acid into a growing polypeptide (analogous to the proofreading step of DNA polymerases) would be impractical. Why? (Hint: Consider how the link between the growing polypeptide and the mRNA is maintained during elongation; see Figs. 27-28 and 27-29.)
20. Bacterial Protein Export Bacteria mostly use the system shown in Fig. 27-44 to export proteins out of the cell. SecB, one of the chaperone proteins found only in gram-negative bacteria, delivers a newly translated polypeptide to the SecA ATPase on the interior side of the membrane. SecA pushes the exported protein through a membrane pore formed by the SecYEG complex. The SecYEG complex is homologous to the Sec61 complex in eukaryotes. Which component of this bacterial protein export system would be the most attractive target for antibiotic development? Explain.
21. Predicting the Cellular Location of a Protein You alter the gene for a eukaryotic polypeptide 300 amino acid residues long so that a signal sequence recognized by the SRP occurs at the polypeptide’s amino terminus and a nuclear localization signal (NLS) occurs internally, beginning at residue 150. Where would you likely find the protein in the cell?
22. Requirements for Protein Translocation across a Membrane The secreted bacterial protein OmpA has a precursor, ProOmpA, which has the amino-terminal signal sequence required for secretion. If you denature purified ProOmpA with 8 M urea and then remove the urea (such as by running the protein solution rapidly through a gel filtration column), the protein can translocate across isolated bacterial inner membranes in vitro. However, translocation becomes impossible if you first incubate ProOmpA for a few hours in the absence of urea. Furthermore, ProOmpA maintains its capacity for translocation for an extended period if you first incubate it in the presence of another bacterial protein called trigger factor. Describe the probable function of trigger factor.
23. Protein-Coding Capacity of a Viral DNA The 5,386 bp genome of bacteriophage ϕX174 includes genes for 10 proteins, designated A to K (omitting “I”), with sizes given in the table. How much DNA would be required to encode these 10 proteins? How can you reconcile the size of the ϕX174 genome with its protein-coding capacity?
Protein Number of amino acid residues Protein Number of amino acid residues A
455
F
427
B
120
G
175
C
86
H
328
D
152
J
38
E
91
K
56
Data Analysis Problem
24. Designing Proteins by Using Randomly Generated Genes Studies of the amino acid sequence and corresponding three-dimensional structure of wild-type or mutant proteins have led to significant insights into the principles that govern protein folding. An important test of this understanding would be to design a protein based on these principles and see whether it folds as expected.
Kamtekar and colleagues (1993) used aspects of the genetic code to generate random protein sequences with defined patterns of hydrophilic and hydrophobic residues. Their clever approach combined knowledge about protein structure, amino acid properties, and the genetic code to explore the factors that influence protein structure.
The researchers set out to generate a set of proteins with the simple four-helix bundle structure shown below, with α helices (shown as cylinders) connected by segments of random coil (light red).
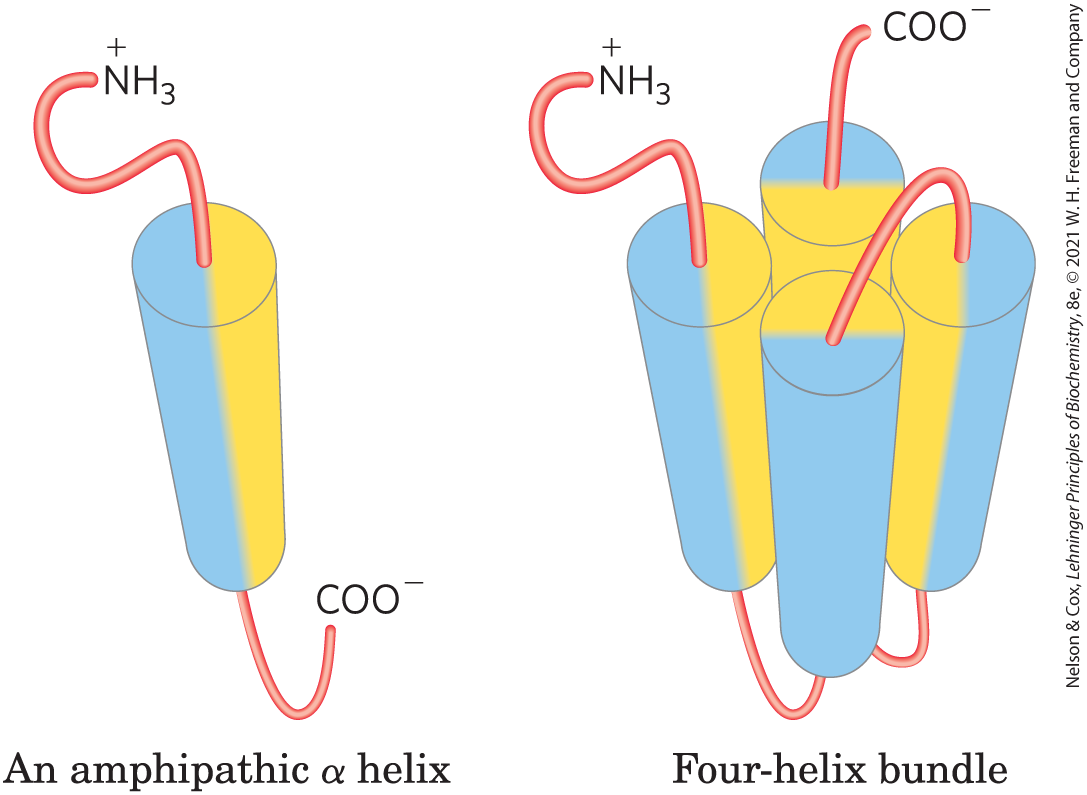
Each α helix is amphipathic — the R groups on one side of the helix are exclusively hydrophobic (yellow), and those on the other side are exclusively hydrophilic (blue). A protein consisting of four of these helices separated by short segments of random coil would be expected to fold so that the hydrophilic sides of the helices face the solvent.
- What forces or interactions hold the four α helices together in this bundled structure?
Figure 4-3a shows a segment of α helix consisting of 10 amino acid residues. With the gray central rod as a divider, four of the R groups (purple spheres) extend from the left side of the helix, and six extend from the right.
- Number the R groups in Figure 4-3a, from top (amino terminus; 1) to bottom (carboxyl terminus; 10). Which R groups extend from the left side, and which extend from the right?
- Suppose you wanted to design this 10 amino acid segment to be an amphipathic helix, with the left side hydrophilic and the right side hydrophobic. Give a sequence of 10 amino acids that could potentially fold into such a structure. There are many possible correct answers.
- Give one possible double-stranded DNA sequence that could encode the amino acid sequence you chose for (c). (It is an internal portion of a protein, so you do not need to include start or stop codons.)
Rather than designing proteins with specific sequences, Kamtekar and colleagues designed proteins with partially random sequences, with hydrophilic and hydrophobic amino acid residues placed in a controlled pattern. They did this by taking advantage of some interesting features of the genetic code to construct a library of synthetic DNA molecules with partially random sequences arranged in a particular pattern.
To design a DNA sequence that would encode random hydrophobic amino acid sequences, the researchers began with the degenerate codon NTN, where N can be A, G, C, or T. They filled each N position by including an equimolar mixture of A, G, C, and T in the DNA synthesis reaction to generate a mixture of DNA molecules with different nucleotides at that position (see Fig. 8-32). Similarly, to encode random polar amino acid sequences, they began with the degenerate codon NAN and used an equimolar mixture of A, G, and C (but in this case, no T) to fill the N positions.
- Which amino acids can be encoded by the NTN triplet? Are all amino acids in this set hydrophobic? Does the set include all the hydrophobic amino acids?
- Which amino acids can be encoded by the NAN triplet? Are all of these polar? Does the set include all the polar amino acids?
- In creating the NAN codons, why was it necessary to leave T out of the reaction mixture?
Kamtekar and coworkers cloned this library of random DNA sequences into plasmids, selected 48 that produced the correct patterning of hydrophilic and hydrophobic amino acids, and expressed these in E. coli. The next challenge was to determine whether the proteins folded as expected. It would be very time-consuming to express each protein, crystallize it, and determine its complete three-dimensional structure. Instead, the investigators used the E. coli protein-processing machinery to screen out sequences that led to highly defective proteins. In this initial screening, they kept only those clones that resulted in a band of protein with the expected molecular weight on SDS polyacrylamide gel electrophoresis (see Fig. 3-18).
- Why would a grossly misfolded protein fail to produce a band of the expected molecular weight on electrophoresis?
Several proteins passed this initial test, and further exploration showed that they had the expected four-helix structure.
- Why didn’t all of the random-sequence proteins that passed the initial screening test produce four-helix structures?
- What forces or interactions hold the four α helices together in this bundled structure?
Reference
- Kamtekar, S., J.M. Schiffer, H. Xiong, J.M. Babik, and M.H. Hecht. 1993. Protein design by binary patterning of polar and nonpolar amino acids. Science 262:1680–1685.