Chapter Review
KEY TERMS
Terms in bold are defined in the glossary.
- genome
- genomics
- systems biology
- cloning
- vector
- recombinant DNA
- recombinant DNA technology
- genetic engineering
- restriction endonucleases
- DNA ligases
- restriction-modification system
- multiple cloning site (MCS)
- plasmid
- bacterial artificial chromosome (BAC)
- yeast artificial chromosome (YAC)
- expression vector
- baculovirus
- bacmid
- site-directed mutagenesis
- fusion protein
- tag
- reverse transcriptase PCR (RT-PCR)
- quantitative PCR (qPCR)
- DNA library
- complementary DNA (cDNA)
- cDNA library
- transcriptome
- proteome
- transcriptomics
- proteomics
- comparative genomics
- genome annotation
- orthologs
- paralogs
- synteny
- RNA-Seq
- single cell RNA-Seq (scRNA-Seq)
- green fluorescent protein (GFP)
- epitope tag
- yeast two-hybrid analysis
- CRISPR/Cas
- guide RNA (gRNA)
- trans-activating CRISPR RNA (tracrRNA)
- single guide RNA (sgRNA)
- single nucleotide polymorphism (SNP)
- haplotype
PROBLEMS
1. Engineering Cloned DNA When joining two or more DNA fragments, a researcher can adjust the sequence at the junction in a variety of subtle ways, as seen in these exercises.
- Write the sequence of each end of a linear DNA fragment produced by an EcoRI restriction digest (include those sequences remaining from the EcoRI recognition sequence).
- Write the sequence resulting from the reaction of this end sequence with DNA polymerase I and the four deoxynucleoside triphosphates (see Fig. 8-34).
- Write the sequence produced at the junction that arises if two ends with the structure derived in (b) are ligated (see Fig. 25-15).
- Write the sequence produced if the structure derived in (a) is treated with a nuclease that degrades only single-stranded DNA.
- Write the sequence of the junction produced if an end with structure (b) is ligated to an end with structure (d).
- Write the sequence of the end of a linear DNA fragment that was produced by a PvuII restriction digest (include those sequences remaining from the PvuII recognition sequence).
- Write the sequence of the junction produced if an end with structure (b) is ligated to an end with structure (f).
- Suppose you can synthesize a short duplex DNA fragment with any sequence you desire. With this synthetic fragment and the procedures described in (a) through (g), design a protocol that would remove an EcoRI restriction site from a DNA molecule and incorporate a new BamHI restriction site at approximately the same location. (See Fig. 9-2.)
- Design four different short synthetic double-stranded DNA fragments that would permit ligation of structure (a) with a DNA fragment produced by a PstI restriction digest. In one of these fragments, design the sequence so that the final junction contains the recognition sequences for both EcoRI and PstI. In the second and third fragments, design the sequence so that the junction contains only the EcoRI and only the PstI recognition sequence, respectively. Design the sequence of the fourth fragment so that neither the EcoRI nor the PstI sequence appears in the junction.
2. Selecting for Recombinant Plasmids When cloning a foreign DNA fragment into a plasmid, it is often useful to insert the fragment at a site that interrupts a selectable marker (such as the tetracycline-resistance gene of pBR322). The loss of function of the interrupted gene can be used to identify clones containing recombinant plasmids with foreign DNA. With a yeast artificial chromosome (YAC) vector, a researcher can distinguish vectors that incorporate large foreign DNA fragments from those that do not, without interrupting gene function. How are these recombinant vectors identified?
3. DNA Cloning The restriction endonuclease PstI cleaves the plasmid cloning vector pBR322 (see Fig. 9-3). A researcher ligates an isolated DNA fragment from a eukaryotic genome (also produced by PstI cleavage) to the prepared vector. She then uses the mixture of ligated DNAs to transform bacteria and selects plasmid-containing bacteria by growth in the presence of tetracycline.
- In addition to the desired recombinant plasmid, what other types of plasmids might be found among the transformed bacteria that are tetracycline-resistant? How can the types be distinguished?
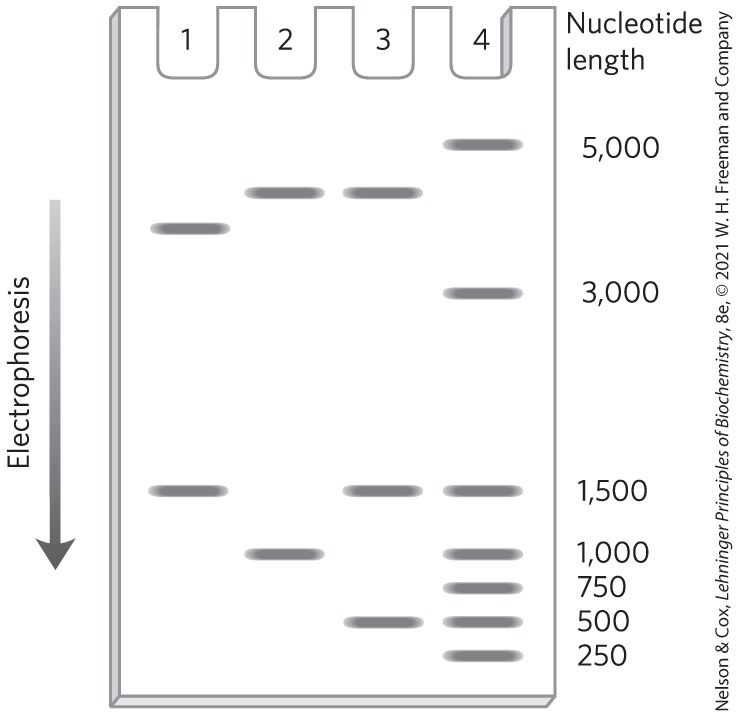
- The cloned DNA fragment is 1,000 bp long and has an EcoRI site 250 bp from one end. The researcher cleaves three different recombinant plasmids with EcoRI and analyzes them by gel electrophoresis, with the results shown in the image. What does each pattern say about the cloned DNA? Note that in pBR322, the PstI and EcoRI restriction sites are about 750 bp apart. The entire plasmid with no cloned insert is 4,361 bp. Size markers in lane 4 have the number of nucleotides noted.
4. Restriction Enzymes The partial sequence of one strand of a double-stranded DNA molecule is
– – – GACGAAGTGCTGCAGAAAGTCCGCGTTATAGGCAT GAATTCCTGAGG – – –
The cleavage sites for the restriction enzymes EcoRI and PstI are shown below.
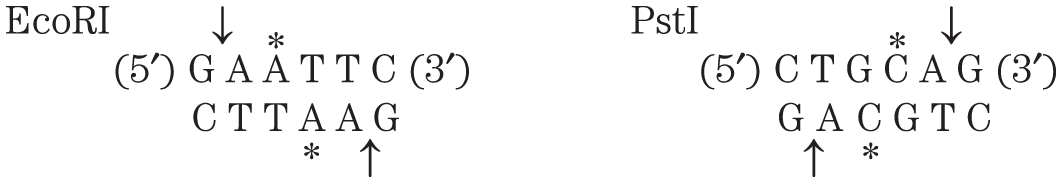
Write the sequence of both strands of the DNA fragment created when this DNA is cleaved with both EcoRI and PstI. The top strand of your duplex DNA fragment should be derived from the strand sequence given.
5. Designing a Diagnostic Test for a Genetic Disease Huntington disease (HD) is an inherited neurodegenerative disorder, characterized by the gradual, irreversible impairment of psychological, motor, and cognitive functions. Symptoms typically appear in middle age, but onset can occur at almost any age. The course of the disease can be 15 to 20 years. Biomedical research is improving our understanding of the molecular basis of the disease. The genetic mutation underlying HD has been traced to a gene encoding a protein ( 350,000) of unknown function. The region of the gene that encodes the amino terminus of the protein has a repeated sequence of CAG codons (for glutamine). The length of this simple trinucleotide repeat indicates whether an individual will develop HD, and at approximately what age the first symptoms will occur. The sequence is repeated 6 to 39 times in individuals who will not develop HD, 40 to 55 times in those with adult-onset HD, and more than 70 times in individuals with childhood-onset HD.
A small portion of the amino-terminal coding sequence of the 3,143-codon HD gene is shown. The nucleotide sequence of the DNA is given in black, the amino acid sequence corresponding to the gene is given in blue, and the CAG repeat is shaded. Using Figure 27-7 to translate the genetic code, outline a PCR-based test for HD that could be carried out using a blood sample. Assume the PCR primer must be 25 nucleotides long. By convention, unless otherwise specified, a DNA sequence encoding a protein is displayed with the coding strand — the sequence identical to the mRNA transcribed from the gene (except for U replacing T) — on top, such that it reads to , left to right.
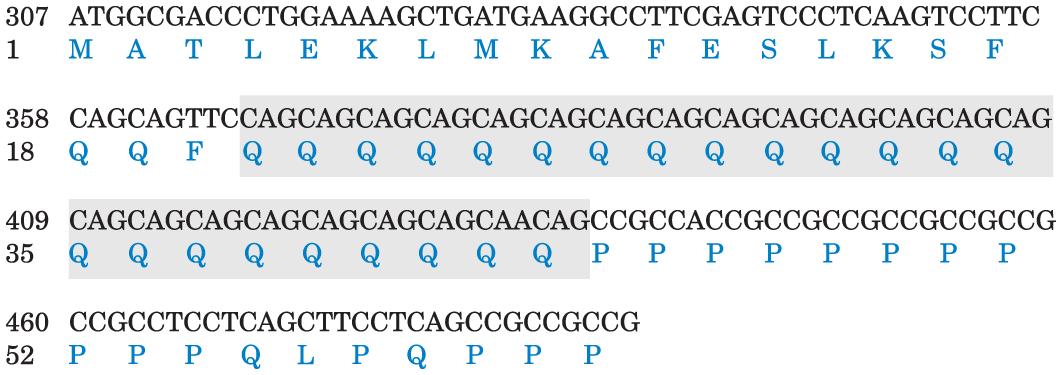
Information from The Huntington’s Disease Collaborative Research Group, Cell 72:971, 1993.
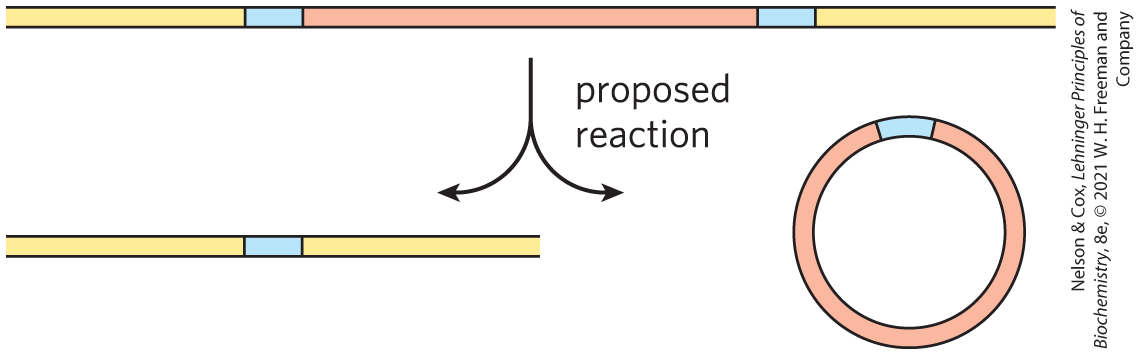
6. Using PCR to Detect Circular DNA Molecules In a species of ciliated protist, a segment of genomic DNA is sometimes deleted. The deletion is a genetically programmed reaction associated with cellular mating. A researcher proposes that the DNA is deleted in a type of recombination called site-specific recombination, with the DNA at either end of the segment joined together and the deleted DNA ending up as a circular DNA reaction product. Suggest how the researcher might use the polymerase chain reaction (PCR) to detect the presence of the circular form of the deleted DNA in an extract of the protist.
7. Protein Dynamics within Cells In a bacterial cell, two proteins, X and Y, are thought to have similar functions. Researchers genetically engineered each protein to fuse with a variant of the green fluorescent protein, one that glows red (X) and the other yellow (Y). Controls showed that both fusion proteins retained their activity, and both produced visible spots of light (foci) when expressed. To better understand the biological functions of the two proteins, the researchers expressed the fusion proteins in the same bacterial cell under two different conditions. Under nutrient-rich conditions, distinct red and yellow puncta (well-defined clustering of foci) were distributed throughout the cell. One or two red puncta were typically found within the nucleoid (chromosomal DNA), whereas the multiple yellow puncta were distributed throughout the cell. However, under nutrient starvation, the yellow puncta migrated and co-localized (overlapped) with the red puncta. What might be concluded from these observations?
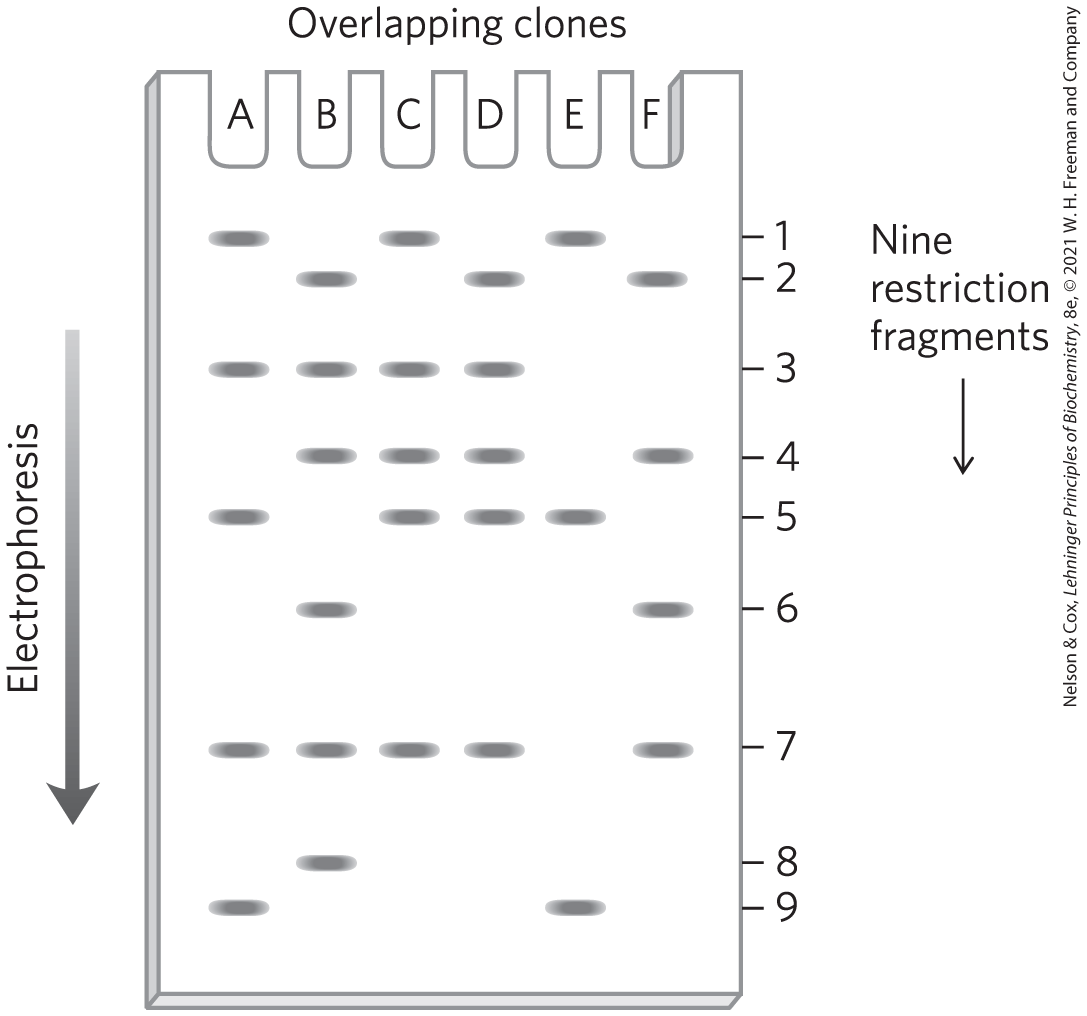
8. Mapping a Chromosome Segment Researchers isolated a group of overlapping clones, designated A through F, from one region of a chromosome. They then separately cleaved each of the clones using a restriction enzyme and resolved the pieces by agarose gel electrophoresis. The image shows the electrophoresis results. There are nine different restriction fragments in this chromosomal region, with a subset appearing in each clone. Using this information, deduce the order of the restriction fragments in the chromosome.
9. Immunofluorescence In a common protocol for immunofluorescence detection of cellular proteins, an investigator uses two antibodies. The first binds specifically to the protein of interest. The second is labeled with fluorochromes for easy visualization, and it binds to the first antibody. In principle, one could simply label the first antibody and skip one step. Why use two successive antibodies?
10. Yeast Two-Hybrid Analysis You are a researcher who has just discovered a new protein in a fungus. Design a yeast two-hybrid experiment to identify the other proteins in the fungal cell with which your protein interacts, and explain how this could help you determine the function of your protein.
11. RNA-Seq RNA-Seq is a next-generation sequencing method used to quantitatively profile the cellular transcriptome. Researchers use RNA-Seq to compare the expression of genes under different environmental conditions or between different types of cells. There are three general steps in an RNA-Seq workflow:
- Generate a cDNA library from cellular RNA.
- Add oligonucleotide adapters to the fragments of the cDNA library.
- Use next-generation sequencing to identify transcriptionally active genes from the cDNA library.
What is the role of the enzyme reverse transcriptase in an RNA-Seq workflow?
12. Cellular RNA Suppose that an investigative team conducted an RNA-Seq experiment on mouse liver cells. The team found many sequences that contained no open reading frames (Chapter 27) — long stretches of consecutive triplet codons that could be translated into a protein and therefore suggest the presence of a gene. Suggest a reason for this observed lack of ORFs.
13. Use of Outgroups in Comparative Genomics A hypothetical protein found in human, orangutan, and chimpanzee has the following sequences (boldface indicates amino acid residue M differences; dashes indicate a deletion, meaning the residues are missing in that sequence):
Human:
ATSAAGYDEWEGGKVLIHL – – KLQNRGALLELDIGAV
Orangutan:
ATSAAGWDEWEGGKVLIHLDGKLQNRGALLELDIGAV
Chimpanzee:
ATSAAGWDEWEGGKILIHLDGKLQNRGALLELDIGAV
What is the most likely sequence of the protein present in the last common ancestor of human and chimpanzee?
14. Human Migrations I Native American populations in North America and South America have mitochondrial DNA haplotypes that can be traced to populations in northeast Asia. The Aleut and Eskimo populations in the far northern parts of North America possess a subset of the same haplotypes that link other Native Americans to Asia, and the Aleut and Eskimo populations also have several additional haplotypes that can be traced to Asian origins but are not found in native populations in other parts of the Americas. Provide a possible explanation.
15. Human Migrations II DNA (haplotypes) originating from the Denisovans can be found in the genomes of Indigenous Australians and Melanesian Islanders. However, the same DNA markers are not found in the genomes of people native to Africa. Explain.
16. Finding Disease Genes You are a gene hunter, trying to find the genetic basis for a rare inherited disease. Examination of six pedigrees of families affected by the disease provides inconsistent results. For two of the families, the disease is co-inherited with markers on chromosome 7. For the other four families, the disease is co-inherited with markers on chromosome 12. Explain how this difference might have arisen.
17. RT-PCR Primer Design Investigators can use sequences of transcribed mRNA as a PCR template to produce a corresponding DNA sequence. Reverse transcriptase, an enzyme that works like DNA polymerase, amplifies the mRNA template as DNA in the first PCR cycle. After making the DNA strands from the RNA template, the investigator can carry out the remaining cycles with DNA polymerase, using standard PCR protocols. She can then compare the detected amplified sequences to the genome to analyze transcriptional activity. Thus, reverse transcriptase PCR (RT-PCR) is a powerful experimental technique used to detect RNA from living cells, which transcribe their DNA into RNA, as opposed to dead tissues, which do not. Consider the mRNA transcript shown.
–AUAUCGCUCCACGUAACUGAAAGAAAAGUGUGGAGCUAGCA GUCGAGA–
Which DNA oligonucleotide pair could serve as a suitable primer in an RT-PCR amplification of this transcript? The oligonucleotides are written in the to direction.
- Primer 1: GGAGACCTTGACT; Primer 2: AGTCAAGGTCTCC
- Primer 1: GACTGCTAGCTCC; Primer 2: GTTACGTGGAGCG
- Primer 1: GCCGCGCGCGCGC; Primer 2: CCCCGCCGCGCCG
- Primer 1: CACGATTCAACGTG; Primer 2: TTCGCATTGCCGAA
 Designing a Diagnostic Test for a Genetic Disease Huntington disease (HD) is an inherited neurodegenerative disorder, characterized by the gradual, irreversible impairment of psychological, motor, and cognitive functions. Symptoms typically appear in middle age, but onset can occur at almost any age. The course of the disease can be 15 to 20 years. Biomedical research is improving our understanding of the molecular basis of the disease. The genetic mutation underlying HD has been traced to a gene encoding a protein ( 350,000) of unknown function. The region of the gene that encodes the amino terminus of the protein has a repeated sequence of CAG codons (for glutamine). The length of this simple trinucleotide repeat indicates whether an individual will develop HD, and at approximately what age the first symptoms will occur. The sequence is repeated 6 to 39 times in individuals who will not develop HD, 40 to 55 times in those with adult-onset HD, and more than 70 times in individuals with childhood-onset HD.
Designing a Diagnostic Test for a Genetic Disease Huntington disease (HD) is an inherited neurodegenerative disorder, characterized by the gradual, irreversible impairment of psychological, motor, and cognitive functions. Symptoms typically appear in middle age, but onset can occur at almost any age. The course of the disease can be 15 to 20 years. Biomedical research is improving our understanding of the molecular basis of the disease. The genetic mutation underlying HD has been traced to a gene encoding a protein ( 350,000) of unknown function. The region of the gene that encodes the amino terminus of the protein has a repeated sequence of CAG codons (for glutamine). The length of this simple trinucleotide repeat indicates whether an individual will develop HD, and at approximately what age the first symptoms will occur. The sequence is repeated 6 to 39 times in individuals who will not develop HD, 40 to 55 times in those with adult-onset HD, and more than 70 times in individuals with childhood-onset HD.DATA ANALYSIS PROBLEM
18. HincII: The First Restriction Endonuclease Discovery of the first restriction endonuclease to be of practical use was reported in two papers published in 1970. In the first paper, Smith and Wilcox described the isolation of an enzyme that cleaved double-stranded DNA. They initially demonstrated the enzyme’s nuclease activity by measuring the decrease in viscosity of DNA samples treated with the enzyme.
- Why does treatment with a nuclease decrease the viscosity of a solution of DNA?
The authors determined whether the enzyme was an endonuclease or an exonuclease by treating -labeled DNA with the enzyme, then adding trichloroacetic acid (TCA). Under the conditions used in their experiment, single nucleotides would be TCA-soluble and oligonucleotides would precipitate.
- No TCA-soluble -labeled material formed upon treatment of the -labeled DNA with the nuclease. Based on this finding, is the enzyme an endonuclease or is it an exonuclease? Explain your reasoning.
When a polynucleotide is cleaved, the phosphate usually is not removed but remains attached to the or end of the resulting DNA fragment. Smith and Wilcox determined the location of the phosphate on the fragment formed by the nuclease in three steps:
- Treat unlabeled DNA with the nuclease.
- Treat a sample (A) of the product with γ--labeled ATP and polynucleotide kinase (which can attach the γ-phosphate of ATP to a OH but not to a phosphate or to a OH or phosphate). Measure the amount of incorporated into the DNA.
- Treat another sample (B) of the product of step 1 with alkaline phosphatase (which removes phosphate groups from free and ends), followed by polynucleotide kinase and γ--labeled ATP. Measure the amount of incorporated into the DNA.
- Smith and Wilcox found that sample A had 136 counts/min of ; sample B had 3,740 counts/min. Did the nuclease cleavage leave the phosphate on the end or the end of the DNA fragments? Explain your reasoning.
- Treatment of bacteriophage T7 DNA with the nuclease gave approximately 40 specific fragments of various lengths. How is this result consistent with the enzyme’s recognizing a specific sequence in the DNA as opposed to making random double-strand breaks?
At this point, there were two possibilities for the site-specific cleavage: the cleavage occurred either (1) at the site of recognition or (2) near the site of recognition but not within the sequence recognized. To address this issue, Kelly and Smith determined the sequence of the ends of the DNA fragments generated by the nuclease, in five steps:
- Treat phage T7 DNA with the enzyme.
- Treat the resulting fragments with alkaline phosphatase to remove the phosphates.
- Treat the dephosphorylated fragments with polynucleotide kinase and γ--labeled ATP to label the ends.
- Treat the labeled molecules with DNases to break them into a mixture of mono-, di-, and trinucleotides.
- Determine the sequence of the labeled mono-, di-, and trinucleotides by comparing them with oligonucleotides of known sequence on thin-layer chromatography.
The labeled products were identified as follows: mononucleotides — A and G; dinucleotides — ()ApA() and ()GpA(); trinucleotides — ()ApApC() and ()GpApC().
- Which model of cleavage is consistent with these results? Explain your reasoning.
Kelly and Smith went on to determine the sequence of the ends of the fragments. They found a mixture of ()TpC() and ()TpT(). They did not determine the sequence of any trinucleotides at the end.
- Based on these data, what is the recognition sequence for the nuclease, and where in the sequence is the DNA backbone cleaved? Use Table 9-2 as a model for your answer.
- Why does treatment with a nuclease decrease the viscosity of a solution of DNA?
References
- Kelly, T. J., and H. O. Smith. 1970. A restriction enzyme from Haemophilus influenzae: II. Base sequence of the recognition site. J. Mol. Biol. 51:393–409.
- Smith, H. O., and K. W. Wilcox. 1970. A restriction enzyme from Haemophilus influenzae: I. Purification and general properties. J. Mol. Biol. 51:379–391.