26.4 Catalytic RNAs and the RNA World Hypothesis
The study of posttranscriptional processing of RNA molecules led to one of the most exciting discoveries in biochemistry — the existence of RNA enzymes or ribozymes. The best-characterized ribozymes are the self-splicing group I introns, RNase P, and the hammerhead ribozyme (discussed below). Most of the activities of these ribozymes are based on two fundamental reactions: transesterification (Fig. 26-14) and phosphodiester bond hydrolysis (cleavage). The substrate for a ribozyme is often an RNA molecule, and it may even be part of the ribozyme itself. When its substrate is RNA, the RNA catalyst can make use of base-pairing interactions to align the substrate for the reaction.
 The study of posttranscriptional processing of RNA molecules led to one of the most exciting discoveries in biochemistry — the existence of RNA enzymes or ribozymes. The best-characterized ribozymes are the self-splicing group I introns, RNase P, and the hammerhead ribozyme (discussed below). Most of the activities of these ribozymes are based on two fundamental reactions: transesterification (
The study of posttranscriptional processing of RNA molecules led to one of the most exciting discoveries in biochemistry — the existence of RNA enzymes or ribozymes. The best-characterized ribozymes are the self-splicing group I introns, RNase P, and the hammerhead ribozyme (discussed below). Most of the activities of these ribozymes are based on two fundamental reactions: transesterification (Ribozymes Share Features with Protein Enzymes
Like protein enzymes, ribozymes vary greatly in size. A self-splicing group I intron may have more than 400 nucleotides. In comparison, the hammerhead ribozyme consists of two RNA strands with a total of just 41 nucleotides. Also as with protein enzymes, the three-dimensional structure of ribozymes is important for function. Ribozymes, like protein enzymes, are inactivated by heating above their melting temperature or by the addition of denaturing agents or complementary oligonucleotides, which disrupt normal base-pairing patterns. Ribozymes can also be inactivated if essential nucleotides are changed. The secondary structure of a self-splicing group I intron from the 26S rRNA precursor of Tetrahymena is shown in detail in Figure 26-37. This secondary structure highlights the large number of base-pairing and other noncovalent interactions that must occur for the ribozyme to adopt a catalytic structure. Just as amino acid mutations can change activities of protein enzymes, nucleotide mutations can alter the noncovalent interactions required for ribozyme folding and catalysis.
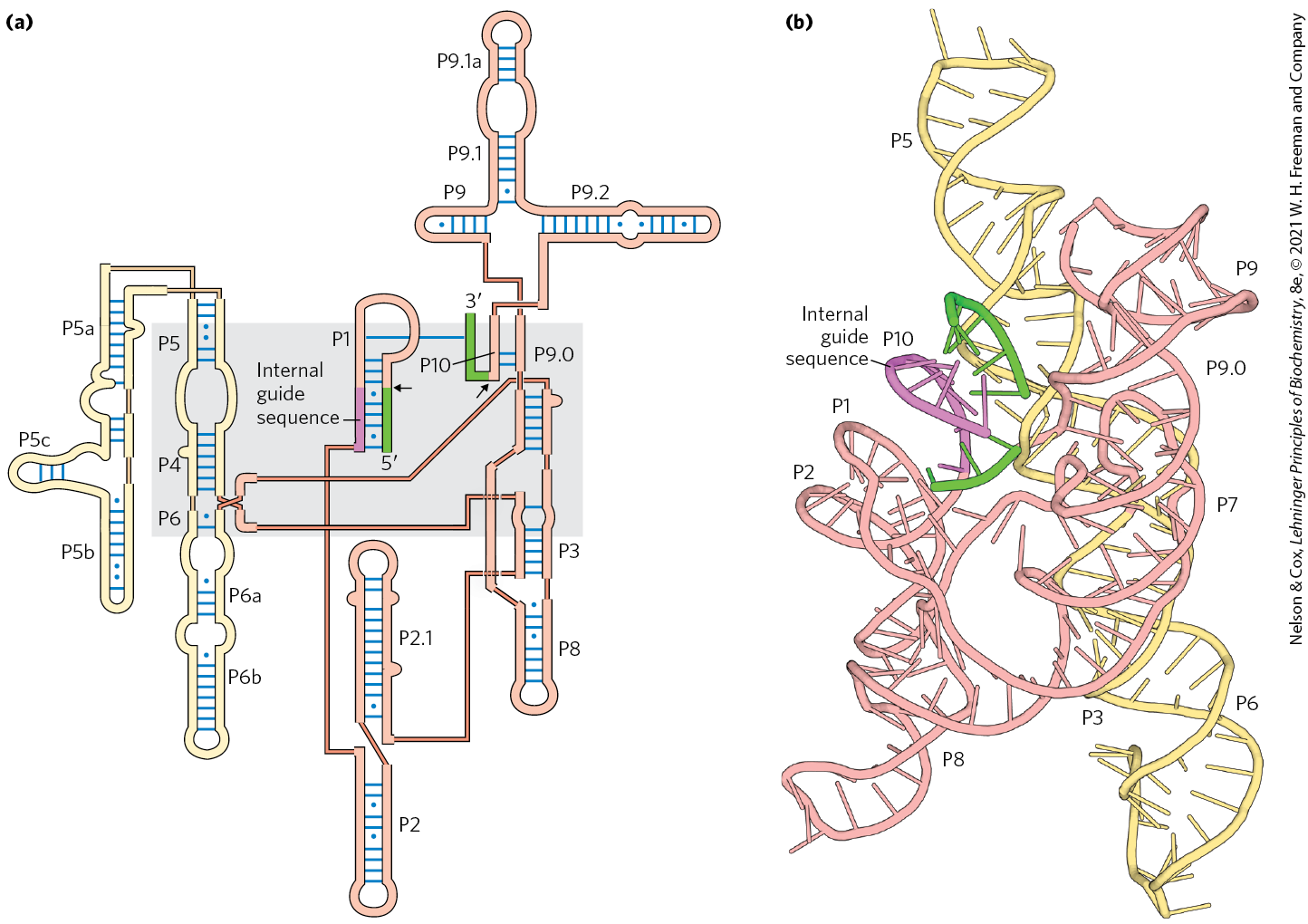
FIGURE 26-37 Secondary structure of the self-splicing rRNA intron of Tetrahymena. (a) A two-dimensional representation of secondary structure immediately prior to the initiation of the reaction. Intron sequences are shaded yellow and light red; flanking exon sequences are green; the internal guide sequences that help to align reacting segments at the active site are purple. Each thin, light-red line represents a bond between adjacent nucleotides in a continuous sequence (a device necessitated by showing this complex molecule in two dimensions). Short blue lines represent normal base pairing; blue dots indicate G–U base pairs. All nucleotides are shown. The catalytic core of the self-splicing activity is shaded in gray. Some base-paired regions are labeled (P1, P3, P2.1, P5a, and so forth) according to an established convention for this RNA molecule. The P1 region, which contains the internal guide sequence (purple), is the location of the splice site (black arrow). Part of the internal guide sequence pairs with the end of the exon, bringing the and splice sites (black arrows) into close proximity. (b) Three-dimensional structure of a reaction intermediate of the same intron, after guanosine-mediated cleavage (Fig. 26-14) and prior to exon ligation. Segments are colored as in (a). [Data from (a) PDB ID 1GID, J. H. Cate et al., Science 273:1678, 1996. (b) PDB ID 1U6B, P. L. Adams et al., Nature 430:45, 2004.]
Ribozymes share several properties with enzymes besides accelerating the reaction rate, including kinetic behavior and specificity. Binding of the guanosine cofactor to the Tetrahymena group I rRNA intron is saturable () and can be competitively inhibited by -deoxyguanosine. The intron is very precise in its excision reaction, largely due to a segment called the internal guide sequence that can base-pair with exon sequences near the splice site (Fig. 26-37). This pairing promotes the alignment of specific bonds to be cleaved and rejoined.
Because the intron itself is chemically altered during the splicing reaction — its ends are cleaved — it may seem to lack one key enzymatic property: the ability to catalyze multiple reactions. Closer inspection has shown that after excision, the 414 nucleotide intron from Tetrahymena rRNA can, in vitro, act as a true enzyme (but in vivo it is quickly degraded). A series of intramolecular cyclization and cleavage reactions in the excised intron leads to the loss of 19 nucleotides from its end. The remaining 395 nucleotide, linear RNA — referred to as L-19 IVS (intervening sequence) — promotes nucleotidyl transfer reactions in which some oligonucleotides are lengthened at the expense of others (Fig. 26-38). The best substrates are oligonucleotides, such as a synthetic oligomer, that can base-pair with the same guanylate-rich internal guide sequence that held the exon in place for self-splicing.
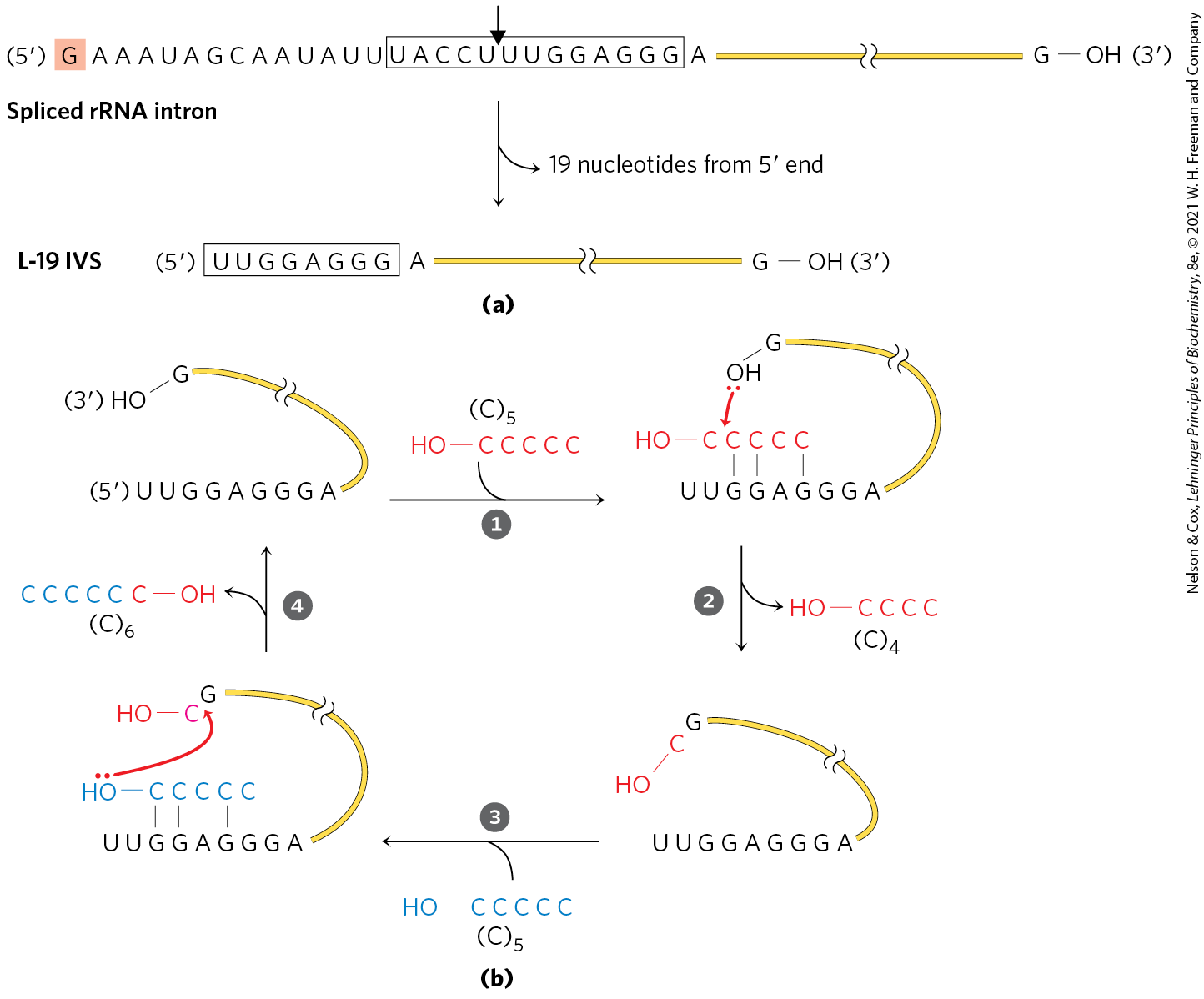
FIGURE 26-38 In vitro catalytic activity of L-19 IVS. (a) L-19 IVS (intervening sequence, the term once used for intron) is generated by the autocatalytic removal of 19 nucleotides from the end of the spliced Tetrahymena intron. The cleavage site is indicated by the arrow in the internal guide sequence (boxed). The G residue (shaded) added in the first step of the splicing reaction is part of the removed sequence. A portion of the internal guide sequence remains at the end of L-19 IVS. (b) L-19 IVS lengthens some RNA oligonucleotides at the expense of others in a cycle of transesterification reactions (steps through ). The OH of the G residue at the end of L-19 IVS plays a key role in this cycle (note that this is not the G residue added in the splicing reaction). is one of the ribozyme’s better substrates because it can base-pair with the guide sequence remaining in the intron.
 through
through  ). The OH of the G residue at the end of L-19 IVS plays a key role in this cycle (note that this is not the G residue added in the splicing reaction). is one of the ribozyme’s better substrates because it can base-pair with the guide sequence remaining in the intron.
). The OH of the G residue at the end of L-19 IVS plays a key role in this cycle (note that this is not the G residue added in the splicing reaction). is one of the ribozyme’s better substrates because it can base-pair with the guide sequence remaining in the intron.The enzymatic activity of the L-19 IVS ribozyme results from a cycle of transesterification reactions mechanistically similar to self-splicing. Each ribozyme molecule can process about 100 substrate molecules per hour and is not altered in the reaction — that is, the intron acts as a catalyst. It follows Michaelis-Menten kinetics, is specific for RNA oligonucleotide substrates, and can be competitively inhibited. The (specificity constant) is , lower than that of many protein enzymes, but the ribozyme accelerates hydrolysis by a factor of relative to the uncatalyzed reaction. It makes use of substrate orientation, covalent catalysis, and metal-ion catalysis — all strategies shared with protein enzymes.
Ribozymes Participate in a Variety of Biological Processes
E. coli RNase P has both an RNA component (the M1 RNA, with 377 nucleotides) and a protein component (). In 1983, Sidney Altman and Norman Pace and their coworkers discovered that under some conditions, the M1 RNA alone is capable of catalysis, cleaving tRNA precursors at the correct position. The protein component apparently serves to stabilize the RNA or facilitate its function in vivo. The RNase P ribozyme recognizes the three-dimensional shape of its pre-tRNA substrate, along with the CCA sequence, and thus can cleave the leaders from diverse tRNAs (Fig. 26-25).
The known catalytic repertoire of ribozymes continues to expand. Some virusoids, small RNAs associated with plant RNA viruses, include a structure that promotes a self-cleavage reaction; the small hammerhead ribozyme illustrated in Figure 26-39 is in this class, catalyzing the hydrolysis of an internal phosphodiester bond. There are at least nine structural classes of ribozymes that engage in self-cleavage; all use general acid and base catalysis (Fig. 6-8) to promote the attack of a -hydroxyl group on an adjacent phosphodiester bond. Despite being surrounded by proteins, the splicing reaction that occurs in a spliceosome relies on a catalytic center formed by the U2, U5, and U6 snRNAs and intron (see Figs 26-16 and 26-17). And, as we shall see in Chapter 27, an RNA component of ribosomes catalyzes the synthesis of proteins. Exploring catalytic RNAs has provided new insights into catalytic function in general and has important implications for our understanding of the origin and evolution of life on this planet.
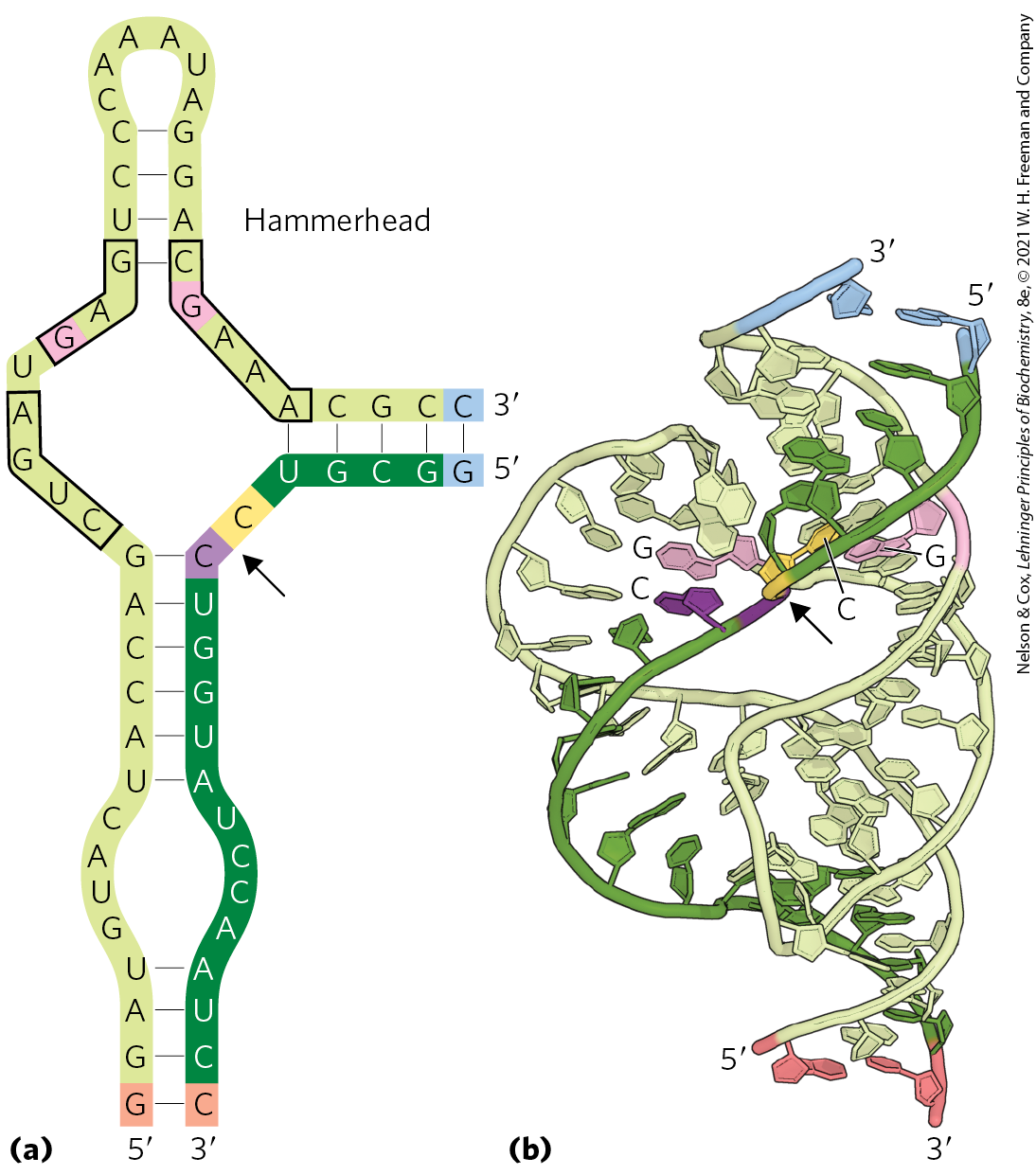
FIGURE 26-39 Hammerhead ribozyme. Some virusoid RNAs include small segments that promote site-specific RNA cleavage reactions associated with replication. These segments are called hammerhead ribozymes, because their secondary structures are shaped like the head of a hammer. (a) The minimal sequences required for catalysis by the ribozyme. The boxed nucleotides are highly conserved and are required for catalytic function. Guanine nucleotides shaded pink form part of the active site. The arrow indicates the site of self-cleavage. (b) Three-dimensional structure of a hammerhead ribozyme (see Fig. 8-25b for a view of another hammerhead ribozyme). The strands are colored as in (a). The hammerhead ribozyme is a metalloenzyme; ions are required for activity in vivo. The phosphodiester bond at the site of self-cleavage is indicated by an arrow. [Data from PDB ID 3ZD5, M. Martick and W. G. Scott, Cell 126:309, 2006.]
Ribozymes Provide Clues to the Origin of Life in an RNA World
The extraordinary complexity and order that distinguish living from inanimate systems are key manifestations of fundamental life processes. Maintaining the living state requires that selected chemical transformations occur very rapidly — especially those that use environmental energy sources and synthesize elaborate or specialized cellular macromolecules. Life depends on powerful and selective catalysts — enzymes — and on informational systems capable of both securely storing the blueprint for these enzymes and accurately reproducing the blueprint for generation after generation. Chromosomes encode the blueprint not for the cell but for the enzymes that construct and maintain the cell. The parallel demands for information and catalysis present a classic conundrum: what came first, the information needed to specify structure or the enzymes needed to maintain and transmit the information?

Carl Woese, 1928–2012
How might a self-replicating polymer come to be? How might it maintain itself in an environment where the precursors for polymer synthesis are scarce? How could evolution progress from such a polymer to the modern DNA-protein world? These difficult questions can be addressed by careful experimentation, providing clues about how life on Earth began and evolved.
The unveiling of the structural and functional complexity of RNA led Carl Woese, Francis Crick, and Leslie Orgel to propose in the 1960s that this macromolecule might serve as both information carrier and catalyst. Since that time, at least six lines of evidence have given increasing substance to their RNA world hypothesis.
1. Prebiotic Chemistry Experiments
The probable origin of purine and pyrimidine bases is suggested by experiments designed to test hypotheses about prebiotic chemistry (pp. 31–32). Beginning with simple molecules thought to be present in the early atmosphere (, , , ), electrical discharges mimicking lightning generate, first, more reactive molecules such as HCN and aldehydes, then an array of amino acids and organic acids (see Fig. 1-33). When molecules such as HCN become abundant, purine and pyrimidine bases are synthesized in detectable amounts. Remarkably, a concentrated solution of ammonium cyanide, refluxed for a few days, generates adenine in yields of up to 0.5% (Fig. 26-40). Adenine may well have been the first and most abundant nucleotide constituent to appear on Earth. Intriguingly, most enzyme cofactors contain adenosine as part of their structure, although it plays no direct role in the cofactor function (see Fig. 8-41). This may suggest an evolutionary relationship. Based on the simple synthesis of adenine from cyanide, adenine may simply have been abundant and available.
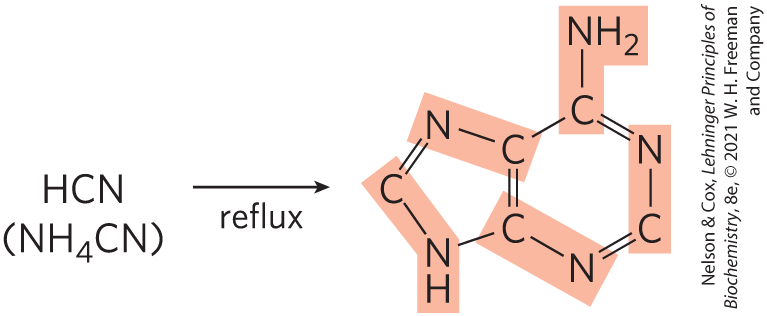
FIGURE 26-40 Experiments supporting prebiotic synthesis of adenine from ammonium cyanide. Adenine is derived from five molecules of cyanide, denoted by shading.
2. The Existence of Catalytic RNAs
In an “RNA world,” RNAs, not proteins, act as catalysts. Perhaps more than anything else, the discovery of ribozymes gave life to the RNA world hypothesis and led to widespread speculation that an RNA world might have been important in the transition from prebiotic chemistry to life (see Fig. 1-35). The parent of all life on this planet, in the sense that it could reproduce itself across the generations from the origin of life to the present, might have been a self-replicating RNA, or a polymer with equivalent chemical characteristics.
3. The Expanding Catalytic Repertoire of Ribozymes
A self-replicating polymer would quickly use up available supplies of precursors provided by the relatively slow processes of prebiotic chemistry. Thus, from an early stage in evolution, metabolic pathways would be required to generate precursors efficiently, with the synthesis of precursors presumably catalyzed by ribozymes. The extant ribozymes found in nature have a limited repertoire of catalytic functions, and of the ribozymes that may once have existed, no trace is left. To explore the RNA world hypothesis more deeply, we need to know whether RNA has the potential to catalyze the many different reactions needed in a primitive system of metabolic pathways.
The search for RNAs with new catalytic functions has been aided by the development of a method that rapidly searches pools of random polymers of RNA and extracts those with particular activities; known as SELEX, this is nothing less than accelerated evolution in a test tube (Box 26-4). It has been used to generate RNA molecules that bind to amino acids, organic dyes, nucleotides, cyanocobalamin, and other molecules. Researchers have isolated ribozymes that catalyze ester and amide bond formation, reactions, metallation of (addition of metal ions to) porphyrins, and carbon–carbon bond formation. The evolution of enzymatic cofactors with nucleotide “handles” that facilitate their binding to ribozymes might have further expanded the repertoire of chemical processes available to primitive metabolic systems.
4. The Structure of the Ribosome
As we shall see in Chapter 27, some natural RNA molecules, components of ribosomes, catalyze the formation of peptide bonds, offering a glimpse of how the RNA world might have been transformed by the greater catalytic potential of proteins. The evolution of a capacity to synthesize proteins would have been a major event in the RNA world, allowing the generation of polymers that could greatly stabilize complex RNA structures. However, the onset of peptide synthesis would also have hastened the demise of the RNA world. Proteins simply have more catalytic potential. The information-carrying role of RNA may have passed to DNA because DNA is chemically more stable. RNA replicase and reverse transcriptase may be modern versions of enzymes that once played important roles in making the transition to the modern DNA-based system.
5. Extant Vestiges of an RNA World
The known functions of RNA continue to multiply with each decade. Retroviruses, other RNA viruses, and retrotransposons inhabit a semi-independent universe, maintaining a parasitic existence within the biosphere. For evolutionary biologists, these almost-living entities provide a window on key steps in the evolution of life. Transposons may have been an early innovation in an RNA world. With the appearance of the first, inefficient self-replicators, transposition could have been an important alternative to replication as a strategy for successful reproduction and survival. Early parasitic RNAs would simply hop into a self-replicating molecule via catalyzed transesterification, then passively undergo replication. Natural selection would have driven transposition to become site-specific, targeting sequences that did not interfere with the catalytic activities of the host RNA. Replicators and RNA transposons could have existed in a primitive symbiotic relationship, each contributing to the evolution of the other. Modern introns, retroviruses, and transposons may all be vestiges of a “piggyback” strategy pursued by early parasitic RNAs. These elements continue to make major contributions to the evolution of their hosts.
6. Progress in the Search for an RNA Replicator
The RNA world hypothesis requires a nucleotide polymer to reproduce itself. Can a ribozyme bring about its own synthesis in a template-directed manner? Researchers are getting closer to finding such a ribozyme or ribozyme system. For example, Gerald Joyce and colleagues, in 2009, reported on the first set of two ribozymes that could cross-catalyze each other’s formation (Fig. 26-41). One ribozyme, E, catalyzes the joining of two oligonucleotides ( and ) to create a second, complementary ribozyme called . could then catalyze the joining of two other oligonucleotides (A and B) to form another molecule of E. In this system, the formation of E and was templated, and the amounts grew exponentially as long as substrates were available and proteins were absent. The system evolved so that more-efficient enzymes appeared in the population. A more general RNA-polymerase-like ribozyme was described in 2011 by Philipp Holliger and colleagues.
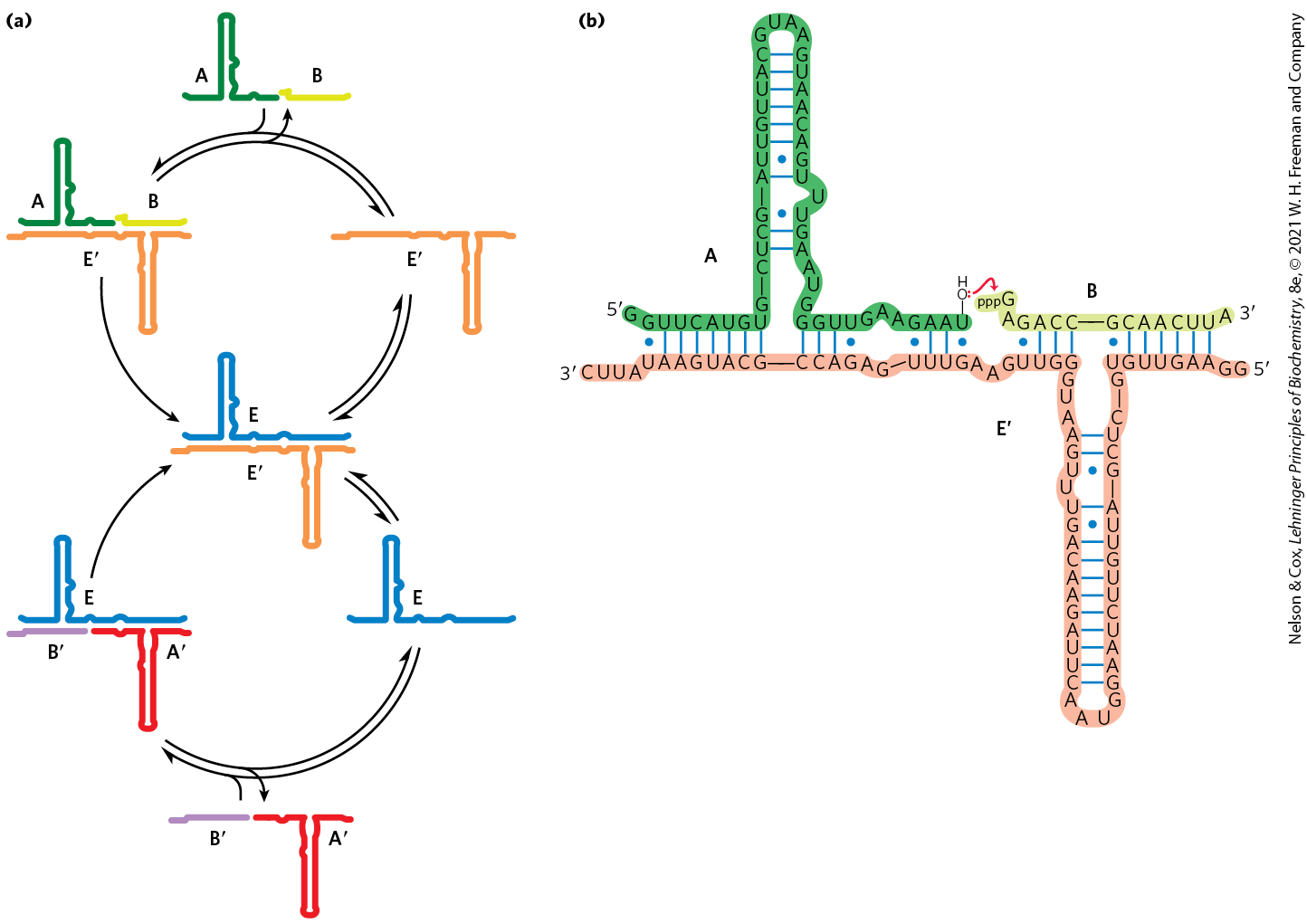
FIGURE 26-41 Self-sustained replication of an RNA enzyme. This system has many of the properties of a living system. The RNA molecules incorporate information and catalytic function, and the reactions produce an exponential increase in the product RNAs. When variants of the RNA substrates are introduced, the system undergoes natural selection such that the best replicators eventually dominate the population. (a) A possible reaction scheme. Oligoribonucleotides A and B anneal to ribozyme and are ligated catalytically to form ribozyme E. The joining of oligoribonucleotides and is similarly catalyzed by ribozyme E. The levels of E and grow exponentially, with a doubling time of about one hour at , as long as there is a supply of the precursors A, B, , and . (b) The ligation reaction involves attack of the OH of one oligoribonucleotide on the α phosphate of the -triphosphate of the other oligoribonucleotide. Pyrophosphate is released. Base pairing of the substrates with the ribozyme plays a key role in aligning the substrates for the reaction. [Information from T. A. Lincoln and G. F. Joyce, Science 323:1229, 2009.]
Although the RNA world remains a hypothesis, with many gaps yet to be explained, experimental evidence supports a growing list of its key elements. Further experimentation should increase our understanding. Important clues to the puzzle will be found in the workings of fundamental chemistry, in living cells, and perhaps on other planets.
SUMMARY 26.4 Catalytic RNA and the RNA World Hypothesis
- Ribozymes and protein-based enzymes share common features, including folded three-dimensional structures, inactivation by denaturation, acceleration of reaction rates, saturable kinetics, and reaction specificity.
- Ribozymes and RNA-based catalysts are present in organisms today and are involved in a wide range of activities, including tRNA processing, nuclear pre-mRNA splicing, and translation.
- The evolution of life on Earth may have included an RNA world in which RNA was the central information carrier and catalyst before proteins and DNA emerged as key players. The existence of ribozymes provides a powerful piece of evidence in support of this hypothesis.
 Ribozymes and protein-based enzymes share common features, including folded three-dimensional structures, inactivation by denaturation, acceleration of reaction rates, saturable kinetics, and reaction specificity.
Ribozymes and protein-based enzymes share common features, including folded three-dimensional structures, inactivation by denaturation, acceleration of reaction rates, saturable kinetics, and reaction specificity.