The term “chromosome” is used to refer to a nucleic acid molecule that is the repository of genetic information in a virus, a bacterium, an archaeon, a eukaryotic cell, or an organelle. It also refers to the densely colored bodies seen in the nuclei of dye-stained eukaryotic cells undergoing mitosis, as visualized using a light microscope.
Chromatin Consists of DNA, Proteins, and RNA
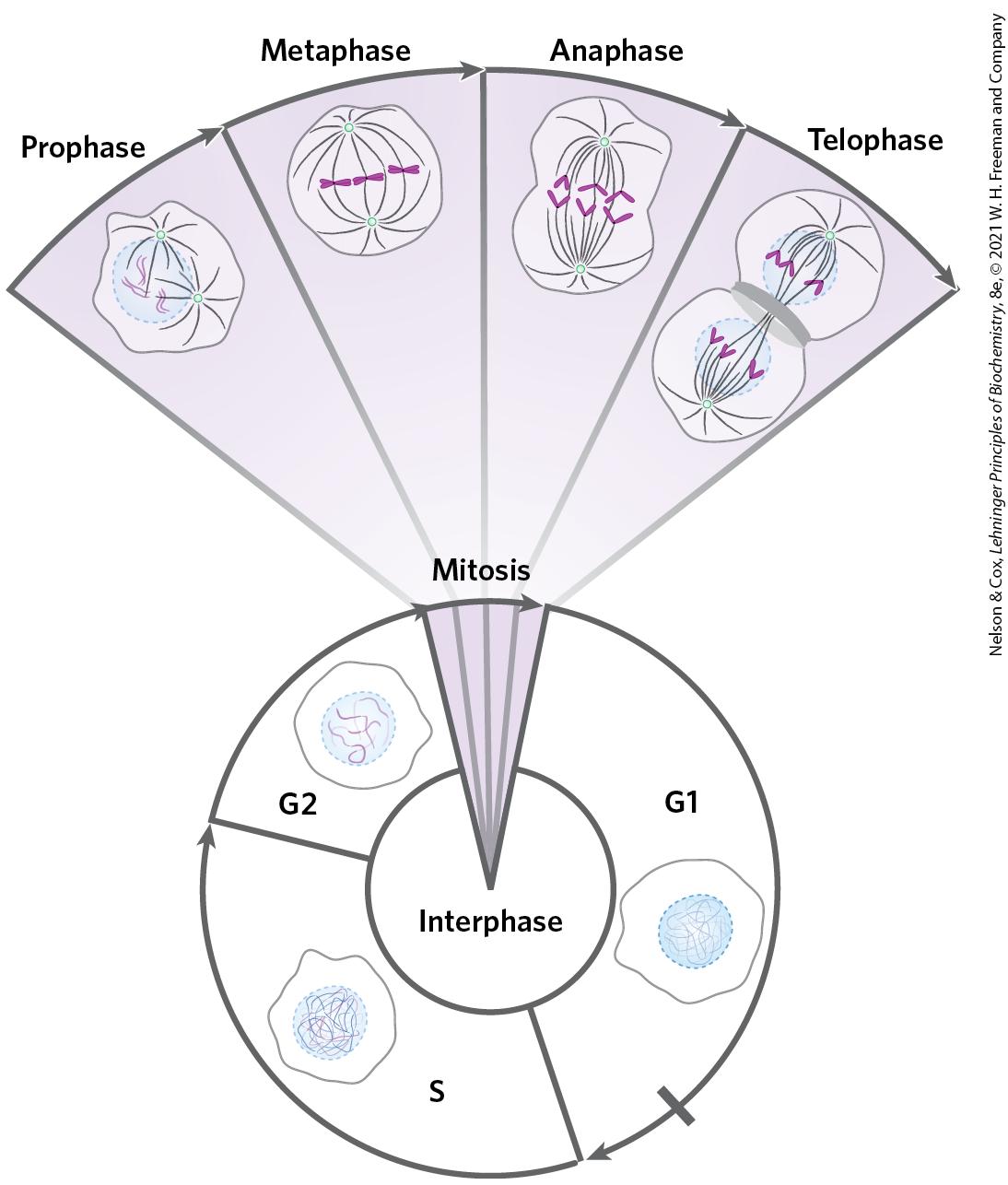
The eukaryotic cell cycle produces remarkable changes in the structure of chromosomes (Fig. 24-22). In nondividing eukaryotic cells (in the G0 phase) and those in interphase (G1, S, and G2), the chromosomal material, chromatin, is amorphous. In the S phase of interphase, the DNA in this amorphous state replicates, each chromosome producing two sister chromosomes (called sister chromatids) that remain associated with each other after replication is complete. The chromosomes become much more condensed during prophase of mitosis, taking the form of a species-specific number of well-defined pairs of sister chromatids (Fig. 24-5).
FIGURE 24-22 Changes in chromosome structure during the eukaryotic cell cycle. The relative lengths of the phases shown here are arbitrary. The duration of each phase varies with cell type and with growth conditions (for single-celled organisms) or metabolic state (for multicellular organisms); mitosis is typically the shortest phase. Cellular DNA is uncondensed throughout interphase, as shown in the cartoons of the nucleus. The interphase period can be divided into the G1 (gap) phase; the S (synthesis) phase, when the DNA is replicated; and the G2 phase, throughout which the replicated chromosomes (chromatids) cohere to one another. Mitosis can be divided into four stages. The DNA undergoes condensation in prophase. During metaphase, the condensed chromosomes line up in pairs along the plane halfway between the spindle poles. The two chromosomes of each pair are linked to different spindle poles via microtubules that extend between the spindle and the centromere. The sister chromatids separate at anaphase, each drawn toward the spindle pole to which it is connected. The process is completed in telophase. After cell division, the chromosomes decondense and the cycle begins anew.
Chromatin consists of fibers containing protein and DNA in approximately equal proportions (by mass), along with a significant amount of associated RNA. The DNA in the chromatin is very tightly associated with proteins called histones, which package and order the DNA into structural units called nucleosomes (Fig. 24-23). Also found in chromatin are many nonhistone proteins, some of which help maintain chromosome structure and others that regulate the expression of specific genes (Chapter 28). Beginning with nucleosomes, eukaryotic chromosomal DNA is packaged into a succession of higher-order structures that ultimately yield the compact chromosome seen with the light microscope. We now turn to a description of this structure in eukaryotes and compare it with the packaging of DNA in bacterial cells.
Found in the chromatin of all eukaryotic cells, histones have molecular weights between 11,000 and 21,000 and are very rich in the basic amino acids arginine and lysine (together these make up about one-fourth of the amino acid residues). All eukaryotic cells have five major classes of histones, differing in molecular weight and amino acid composition (Table 24-5). The H3 histones are nearly identical in amino acid sequence in all eukaryotes, as are the H4 histones, suggesting strict conservation of their functions. For example, only 2 of 102 amino acid residues differ between the H4 histone molecules of peas and cows, and only 8 differ between the H4 histones of humans and yeast. Histones H1, H2A, and H2B show less sequence similarity across eukaryotic species.
TABLE 24-5 Types and Properties of the Common Histones
aThe sizes of these histones vary somewhat from species to species. The numbers given here are for bovine histones.
Each type of histone is subject to enzymatic modification by methylation, acetylation, ADP-ribosylation, phosphorylation, glycosylation, SUMOylation, or ubiquitination (p. 216 and Fig. 6-38). Such modifications affect the net electric charge, shape, and other properties of histones, as well as the structural and functional properties of the chromatin. The modifications play a role in the regulation of transcription and in chromatin structure at different stages of the cell cycle.
In addition, eukaryotes generally have several variant forms of certain histones, most notably histones H2A and H3, described in more detail below. The variant forms, along with their modifications, have specialized roles in DNA metabolism.
Nucleosomes Are the Fundamental Organizational Units of Chromatin
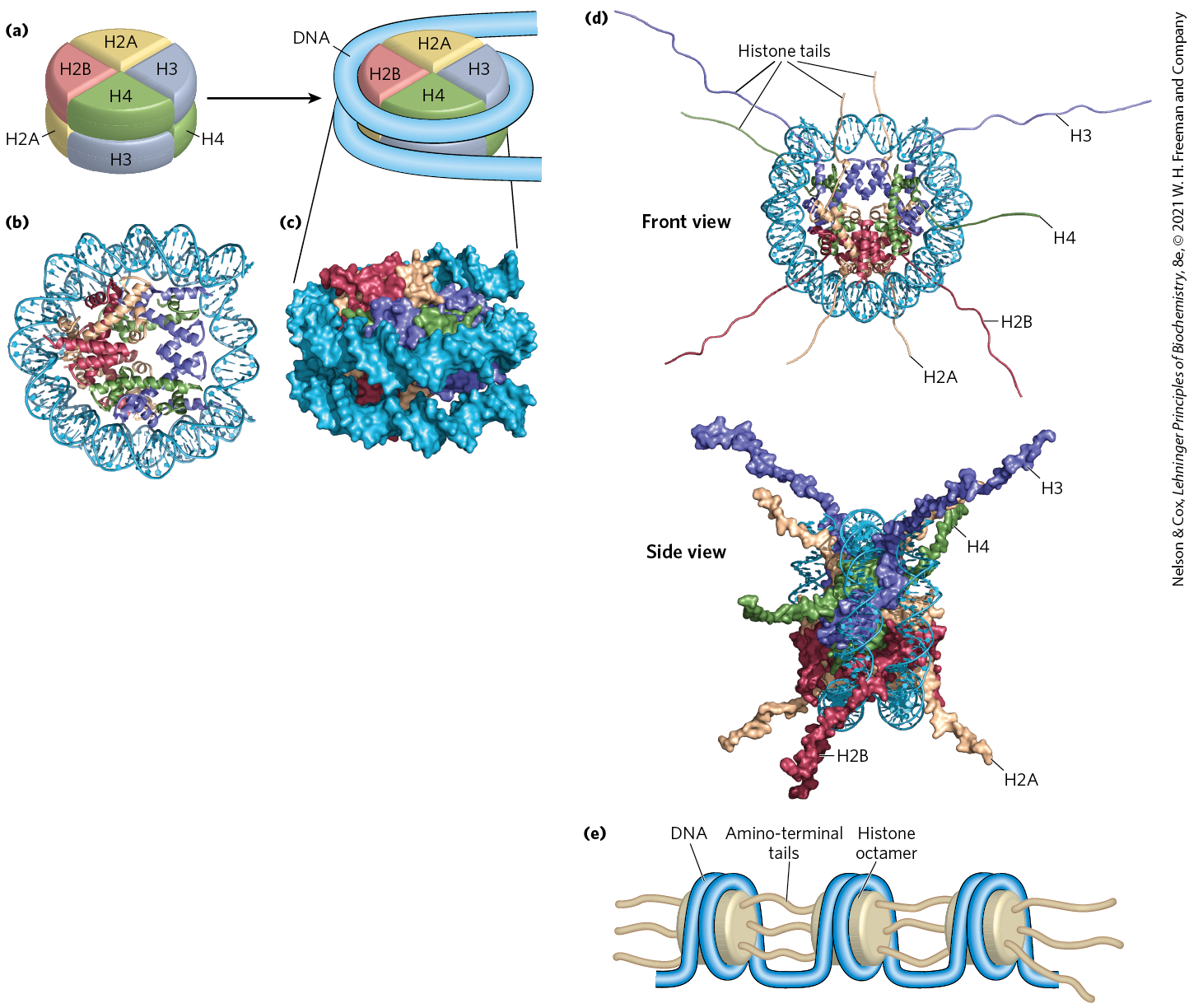
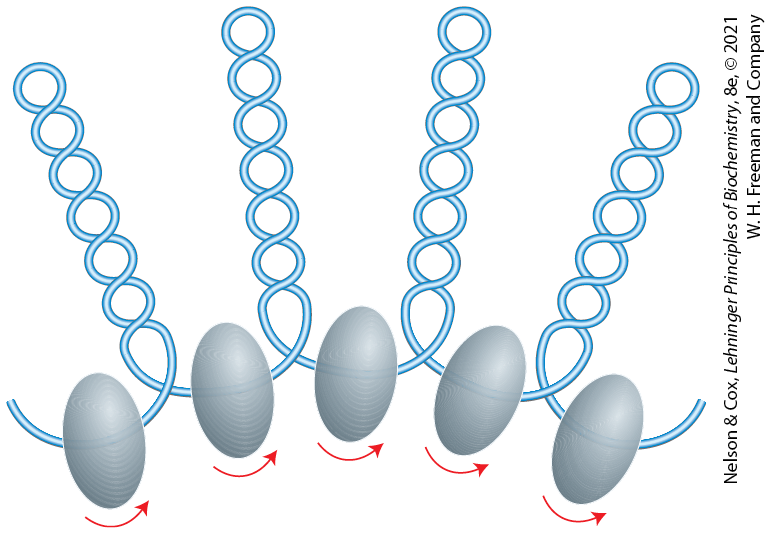
The eukaryotic chromosome depicted in Figure 24-5 represents the compaction of a DNA molecule about μm long into a cell nucleus that is typically 5 to 10 μm in diameter. This 10,000-fold compaction is achieved by means of several levels of highly organized folding. Subjection of chromosomes to treatments that partially unfold them reveals a structure in which the DNA is bound tightly to beads of protein, often regularly spaced. The beads in this “beads-on-a-string” arrangement are complexes of histones and DNA. The bead plus the connecting DNA that leads to the next bead form the nucleosome, the fundamental unit of organization on which the higher-order packing of chromatin is built (Fig. 24-24). The bead of each nucleosome contains eight histone molecules: two copies each of H2A, H2B, H3, and H4. The spacing of the nucleosome beads provides a repeating unit typically of about 200 bp, of which 146 bp are bound tightly around the eight-part histone core and the remainder serve as linker DNA between nucleosome beads. Histone H1 binds to the linker DNA. Brief treatment of chromatin with enzymes that digest DNA causes the linker DNA to degrade preferentially, releasing histone particles containing 146 bp of bound DNA that is protected from digestion.
FIGURE 24-24 DNA wrapped around a histone core. (a) The simplified structure of a nucleosome octamer (left), with DNA wrapped around the histone core (right). (b) A ribbon representation of the nucleosome from the African frog Xenopus laevis. Different colors represent the different histones, matching the colors in (a). (c) Surface representation of the nucleosome. The view in (c) is rotated relative to the view in (b) to match the orientation shown in (a). A 146 bp segment of DNA in the form of a left-handed solenoidal supercoil wraps around the histone complex 1.67 times. (d) Two views of histone amino-terminal tails protruding from between the two DNA duplexes that supercoil around the nucleosome core. Some tails pass between the supercoils, through holes formed by alignment of the minor grooves of adjacent helices. The H3 and H2B tails emerge between the two coils of DNA wrapped around the histone; the H4 and H2A tails emerge between adjacent histone subunits. (e) The amino-terminal tails of one nucleosome protrude from the particle and interact with adjacent nucleosomes, helping to define higher-order DNA packaging. [(b–d) Data from PDB ID 1AOI, K. Luger et al., Nature 389:251, 1997.]
Researchers have crystallized nucleosome cores obtained in this way, and x-ray diffraction analysis reveals a particle made up of the eight histone molecules with the DNA wrapped around the core in the form of a left-handed solenoidal supercoil (Fig. 24-24; see also Fig. 24-21). Extending out from the nucleosome core are the amino-terminal tails of the histones, which are intrinsically disordered (Fig. 24-24d). Most of the histone modifications occur in these tails. The tails play a key role in forming contacts between nucleosomes in the chromatin (Fig. 24-24e). As the nucleosomes are approximately 10 to 11 nm in diameter, this simple beads-on-a-string structure is sometimes called the 10 nm fiber.
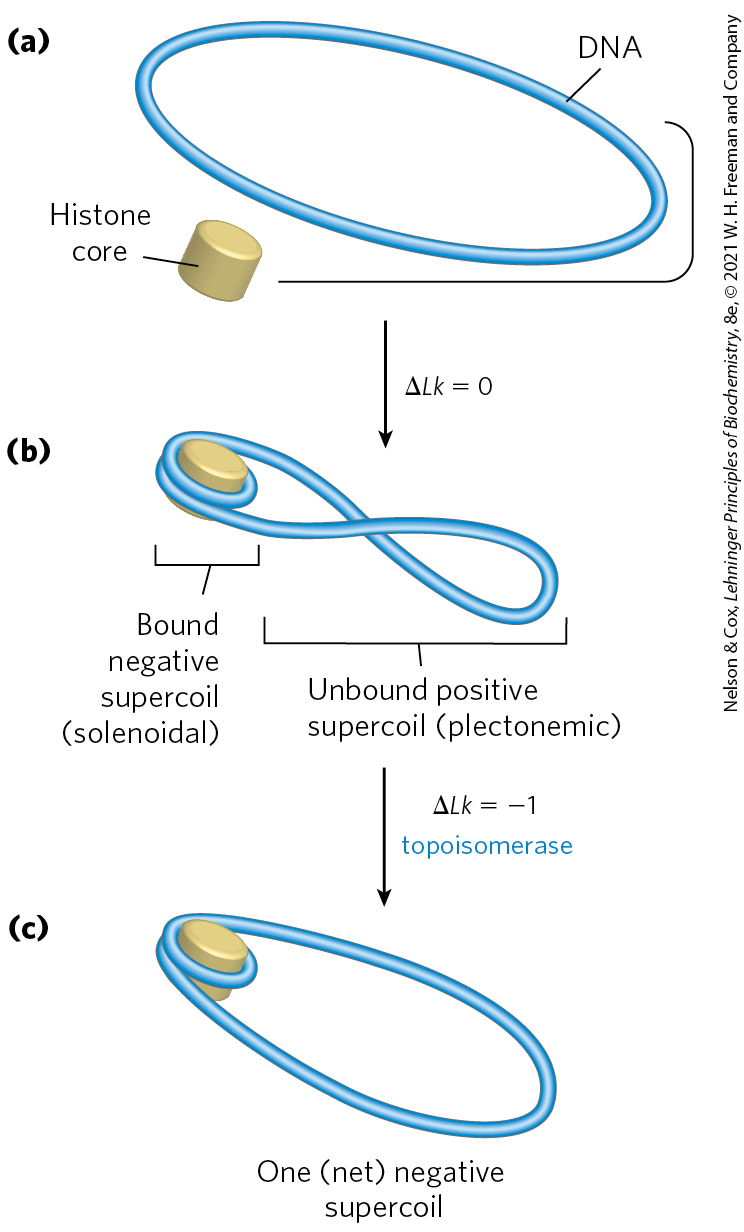
A close inspection of the nucleosome structure reveals why eukaryotic DNA is underwound even though eukaryotic cells lack enzymes that underwind DNA. Recall that the solenoidal wrapping of DNA in nucleosomes is but one form of supercoiling that can be taken up by underwound (negatively supercoiled) DNA. The tight wrapping of DNA around the histone core requires the removal of about one helical turn in the DNA. When the protein core of a nucleosome binds in vitro to a relaxed closed-circular DNA, the binding introduces a negative supercoil. Because this binding process does not break the DNA or change the linking number, the formation of a negative solenoidal supercoil must be accompanied by a compensatory positive supercoil in the unbound region of the DNA (Fig. 24-25). As mentioned earlier, eukaryotic topoisomerases can relax positive supercoils. Relaxing the unbound positive supercoil leaves the negative supercoil fixed (through its binding to the nucleosome’s histone core) and results in an overall decrease in linking number. Indeed, topoisomerases have proved necessary for assembling chromatin from purified histones and closed-circular DNA in vitro.
FIGURE 24-25 Chromatin assembly. (a) Relaxed closed-circular DNA. (b) Binding of a histone core to form a nucleosome induces one negative supercoil. In the absence of any strand breaks, a positive supercoil must form elsewhere in the DNA . (c) Relaxation of this positive supercoil by a topoisomerase leaves one net negative supercoil .
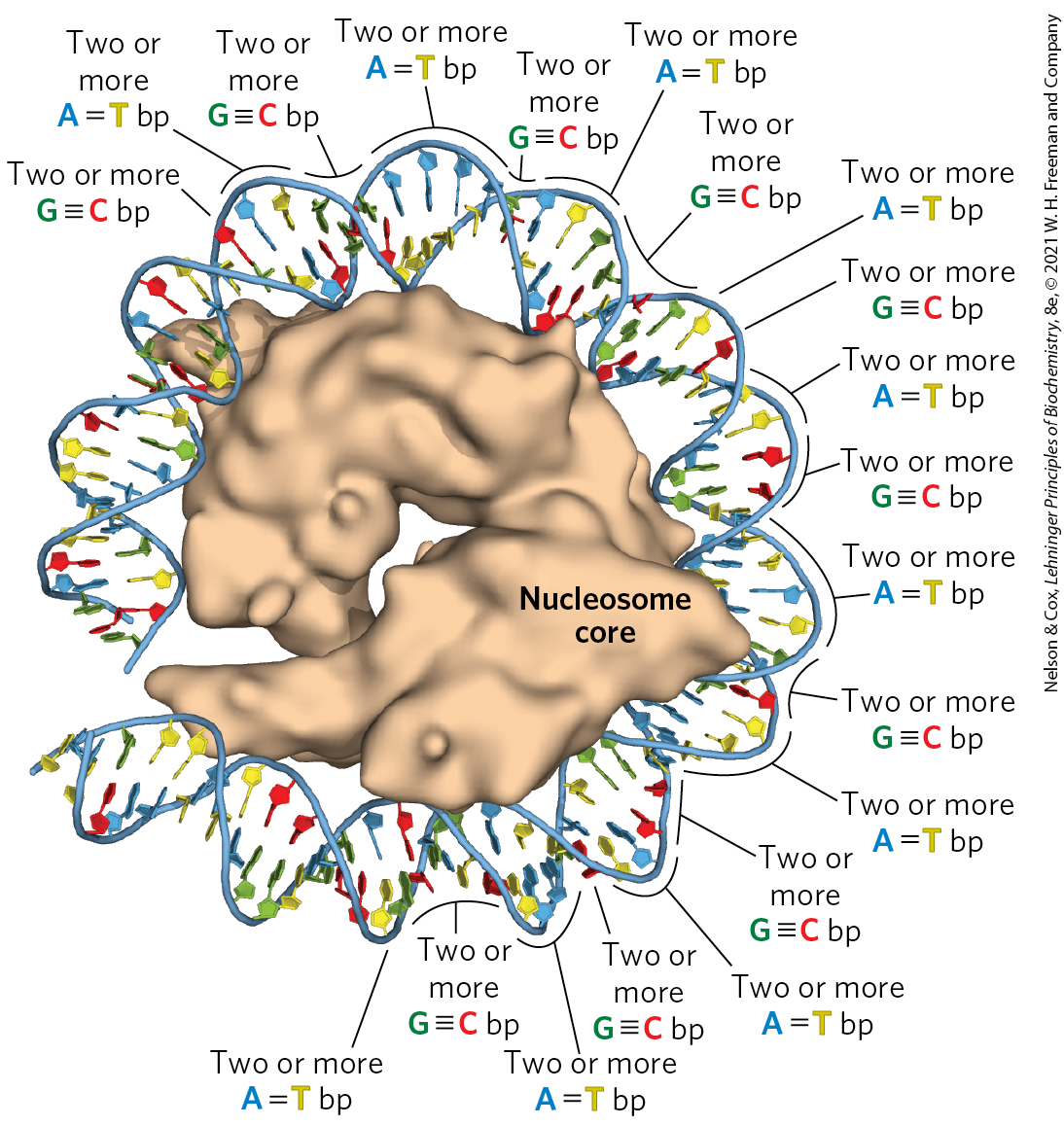
Another factor that affects the binding of DNA to histones in nucleosome cores is the sequence of the bound DNA. Histone cores do not bind at random positions on the DNA; rather, some locations are more likely to be bound than others. This positioning is not fully understood, but in some cases it seems to depend on a local abundance of base pairs in the DNA helix where it is in contact with the histones (Fig. 24-26). A cluster of two or three base pairs facilitates the compression of the minor groove that is needed for the DNA to wrap tightly around the nucleosome’s histone core. Nucleosomes bind particularly well to sequences where AA or AT or TT dinucleotides are staggered at 10 bp intervals, an arrangement that can account for up to 50% of the positions of bound histones in vivo.
FIGURE 24-26 The effect of DNA sequence on nucleosome binding. Runs of two or more base pairs facilitate the bending of DNA, whereas runs of two or more base pairs have the opposite effect. When spaced at about 10 bp intervals, consecutive base pairs help bend DNA into a circle. When consecutive base pairs are spaced 10 bp apart, offset by 5 bp from runs of base pairs, DNA binding to the nucleosome core is facilitated. [Data from PDB ID 1AOI, K. Luger et al., Nature 389:251, 1997.]
Nucleosome cores are deposited on DNA during replication or following other processes that require a transient displacement of nucleosomes. Other, nonhistone proteins are required for the positioning of some nucleosome cores. In several organisms, certain proteins bind to a specific DNA sequence and facilitate the formation of a nucleosome core nearby. Nucleosome cores seem to be deposited stepwise. A tetramer of two H3 and two H4 histones binds first, followed by two H2A–H2B dimers. The incorporation of nucleosomes into chromosomes after chromosomal replication is mediated by a complex of histone chaperones conserved in all eukaryotes and described here for the yeast system. These include the proteins CAF1 (chromatin assembly factor 1), RTT106 and RTT109 (regulation of Ty1 transposition), and ASF1 (anti-silencing factor 1). ASF1 binds to newly synthesized H3–H4 dimers and facilitates RTT109-mediated acetylation at (K56) of histone H3 (H3K56). The H3K56 modification increases the affinity of H3 for CAF1 and RTT, which in turn promote the deposition of H3-containing histone complexes on the DNA after replication. CAF1 binds directly to a key component of the replication complex called PCNA (see Chapter 25), so that nucleosome deposition is closely coordinated with replication. Some of the same histone chaperones, or different ones, may help assemble nucleosomes after DNA repair, transcription, or other processes.
Histone exchange factors permit the substitution of histone variants for core histones in contexts other than postreplication. Proper placement of these variant histones is important. Studies show that mice lacking one of the variant histones die as early embryos (Box 24-1). Precise positioning of nucleosome cores also plays a role in the expression of some eukaryotic genes (Chapter 28).
Nucleosomes Are Packed into Highly Condensed Chromosome Structures
Wrapping of DNA around a nucleosome core compacts the DNA length about sevenfold. The overall compaction in a chromosome, however, is greater than 10,000-fold — ample evidence for even higher orders of structural organization. The condensation does not follow a rigid organization, but it is also not random and occurs so as to avoid the formation of knots.
The higher levels of folding are not yet fully understood, but certain regions of DNA seem to associate with a chromosomal scaffold (Fig. 24-27) that contains many proteins. Given the need to fold and compact the chromosome without creating knots, topoisomerase II is one of the most abundant proteins in the chromosome, further emphasizing the relationship between DNA underwinding and chromatin structure. Topoisomerase II is so important to the maintenance of chromatin structure that inhibitors of this enzyme can kill rapidly dividing cells. Several drugs used in cancer chemotherapy are topoisomerase II inhibitors that allow the enzyme to promote strand breakage but not the resealing of the breaks (Box 24-2, p. 906).
FIGURE 24-27 Loops of DNA attached to a chromosomal scaffold. (a) A swollen mitotic chromosome, produced in a buffer of low ionic strength, as seen in the electron microscope. Notice the appearance of chromatin loops at the margins. (b) Extraction of the histones leaves a proteinaceous chromosomal scaffold surrounded by naked DNA. (c) The DNA appears to be organized in loops attached at their base to the scaffold in the upper left corner; . The three images are at different magnifications.
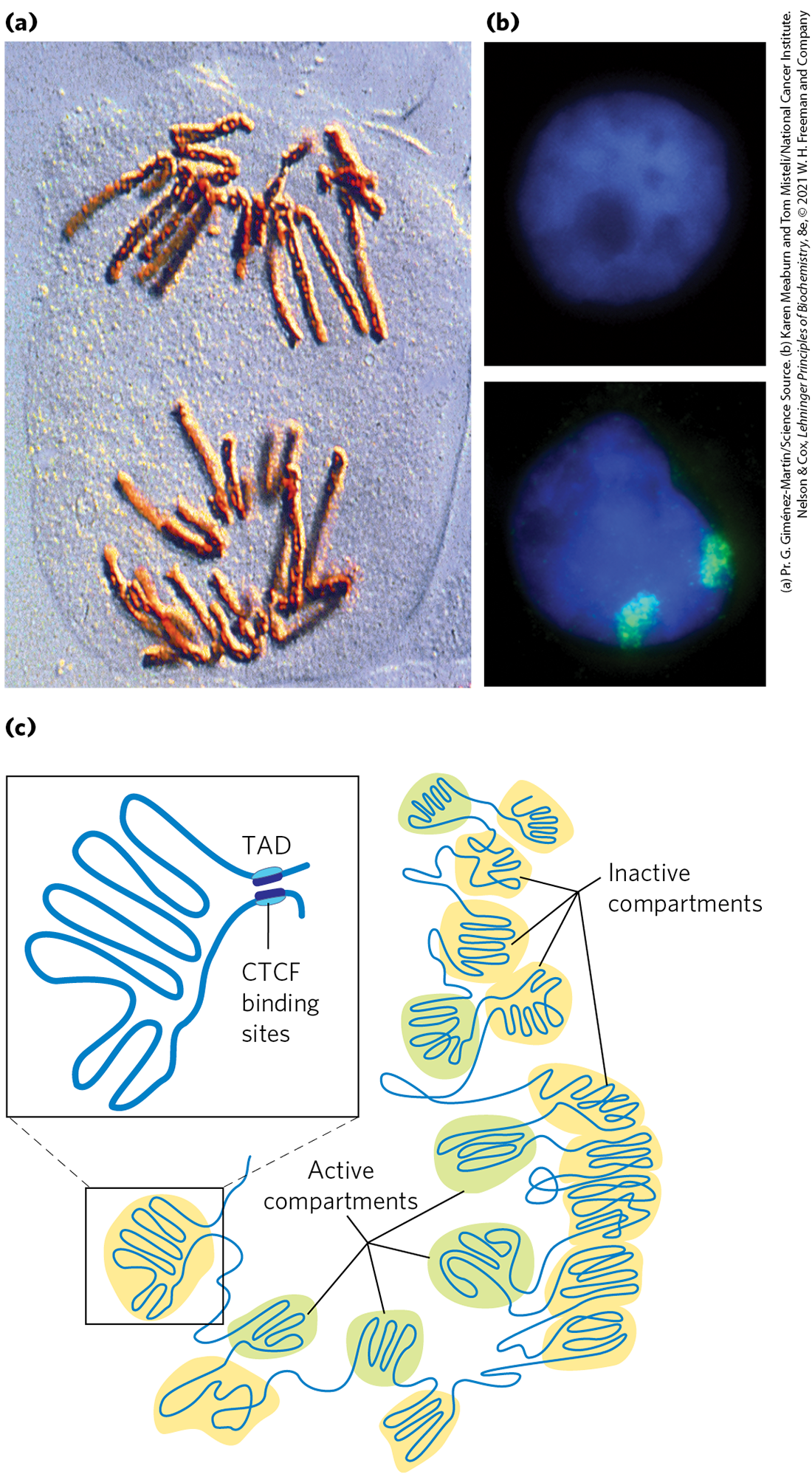
There are additional layers of organization in the eukaryotic nucleus. Just before cell division during mitosis, chromosomes can be seen as highly condensed and organized structures (Figure 24-28a). During interphase, chromosomes appear dispersed (Fig. 24-28b, top), but they do not meander randomly in nuclear space (Fig. 24-28b, bottom). Each chromosome appears to be organized with two sets of compartments, one set that is transcriptionally active and the other that is transcriptionally inactive. The level of chromatin condensation is reduced in the transcriptionally active compartments. The highly condensed DNA in transcriptionally inactive regions or in regions lacking genes is also called heterochromatin. Within each compartment, large segments of DNA are organized in loops called topologically associating domains, or TADs. The TADs, which typically average about 800,000 bp, are often bordered by DNA sites recognized by the CCCTC-binding factor (CTCF). The binding by CTCF brings together sites that are otherwise quite distant in the linear DNA sequence, tethering the base of the loop (Fig. 24-28c).
FIGURE 24-28 Chromosomal organization in the eukaryotic nucleus. (a) Condensed chromosomes at the mitotic anaphase in cells of the bluebell (Endymion sp.). (b) Interphase nuclei of human breast epithelial cells. The nucleus on the bottom has been treated so that its two copies of chromosome 11 fluoresce green. (c) Chromosomes are organized into active compartments, in which actively transcribed genes are clustered, and inactive compartments, made of heterochromatin within which genes are silenced. In both cases, the compartments feature large DNA loops called topologically associating domains (TADs), many constrained at their bases by DNA-binding proteins such as CTCF. Certain lncRNAs (Fig. 24-29) also play a role in defining loops within chromatin. Constraining a loop at its base not only provides a boundary for the loop, but also allows supercoiling within the loop to be controlled.
Another important component defining the structure of chromosomes is RNA, particularly a class of RNAs called long noncoding RNAs (lncRNAs). RNA has the potential to take up a variety of structures (see Chapter 8), and can interact with DNA, proteins, or other RNA molecules. The lncRNAs, as the name implies, are functional RNAs, generally over 200 nucleotides long, that do not necessarily encode proteins. Many lncRNAs are now known and more are being discovered rapidly. Many of them provide a scaffold for proteins that both bind to the RNA and affect chromosome structure and function. Some proteins that bind to lncRNAs also have binding sites on DNA, and the RNAs provide a link that tethers distant parts of the chromosome together (Fig. 24-29). Other proteins that bind to lncRNAs help to position nucleosomes, modify histones, methylate DNA at various locations to alter gene transcription, and generally affect chromosome structure in many different ways. Some well-studied examples include particular lncRNAs that play a major role in X chromosome inactivation in mammals (Box 24-3).
FIGURE 24-29 Effects of lncRNAs on chromosome architecture and gene expression. (a) Various lncRNAs can interact with DNA-binding proteins and in some cases with DNA to tether otherwise distant segments of DNA. (b) A transcribed lncRNA can interact with multiple proteins that have gene regulatory roles, suppressing or activating transcription of nearby genes. [Information from J. M. Engreitz et al., Nat. Rev. Mol. Cell Biol. 17:756, 2016, Fig. 5.]
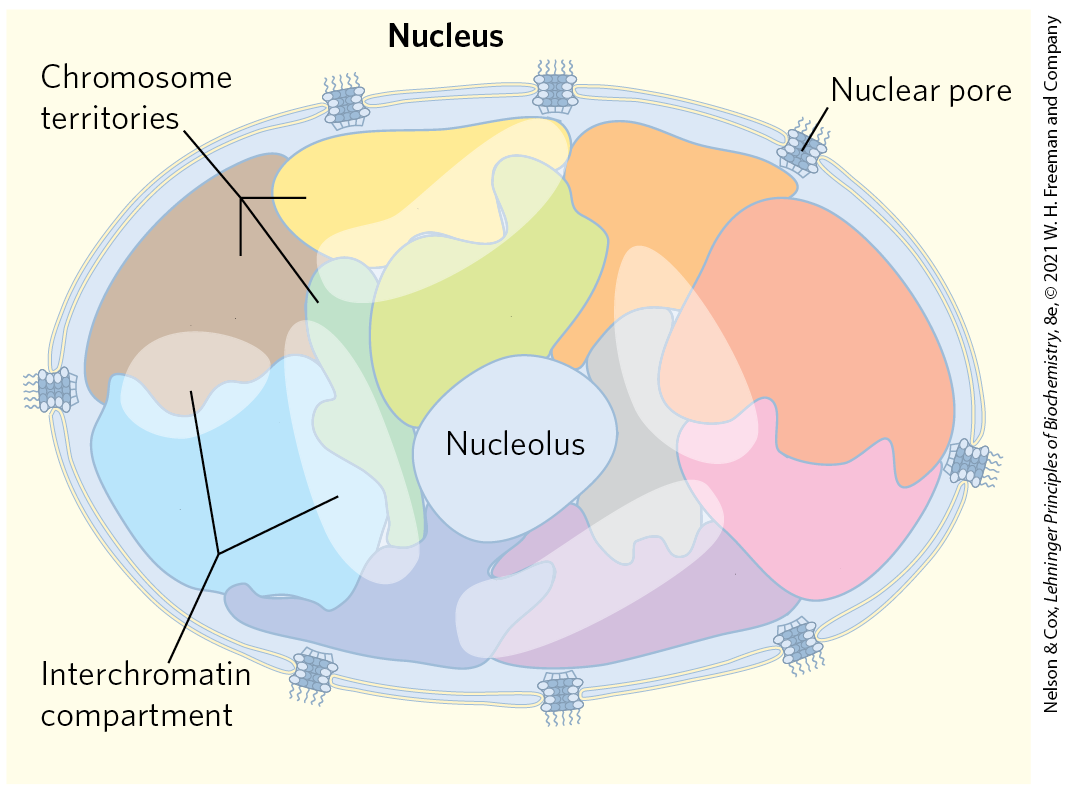
The entire structure of each chromosome is constrained within a subnuclear domain called a chromosome territory (Fig. 24-30). There is little or no intermingling of chromosomal DNA in different territories. The exact location of chromosome territories varies from cell to cell in an organism, but some spatial patterns are evident. Some chromosomes have a higher density of genes than others (for example, human chromosomes 1, 16, 17, 19, and 22), and these tend to have territories in the center of the nucleus. Chromosomes with more heterochromatin tend to be located on the nuclear periphery. Spaces between chromosomes are often sites where transcriptional machinery and transcriptionally active genes on adjacent chromosomes are concentrated.
FIGURE 24-30 Chromosome territories. Cartoon showing chromosome territories in a eukaryotic nucleus. The interchromatin compartments are enriched in transcriptional machinery and have abundant actively transcribed genes. The nucleolus is a suborganelle within the nucleus where ribosomes are synthesized and assembled (Chapter 27).
Condensed Chromosome Structures Are Maintained by SMC Proteins
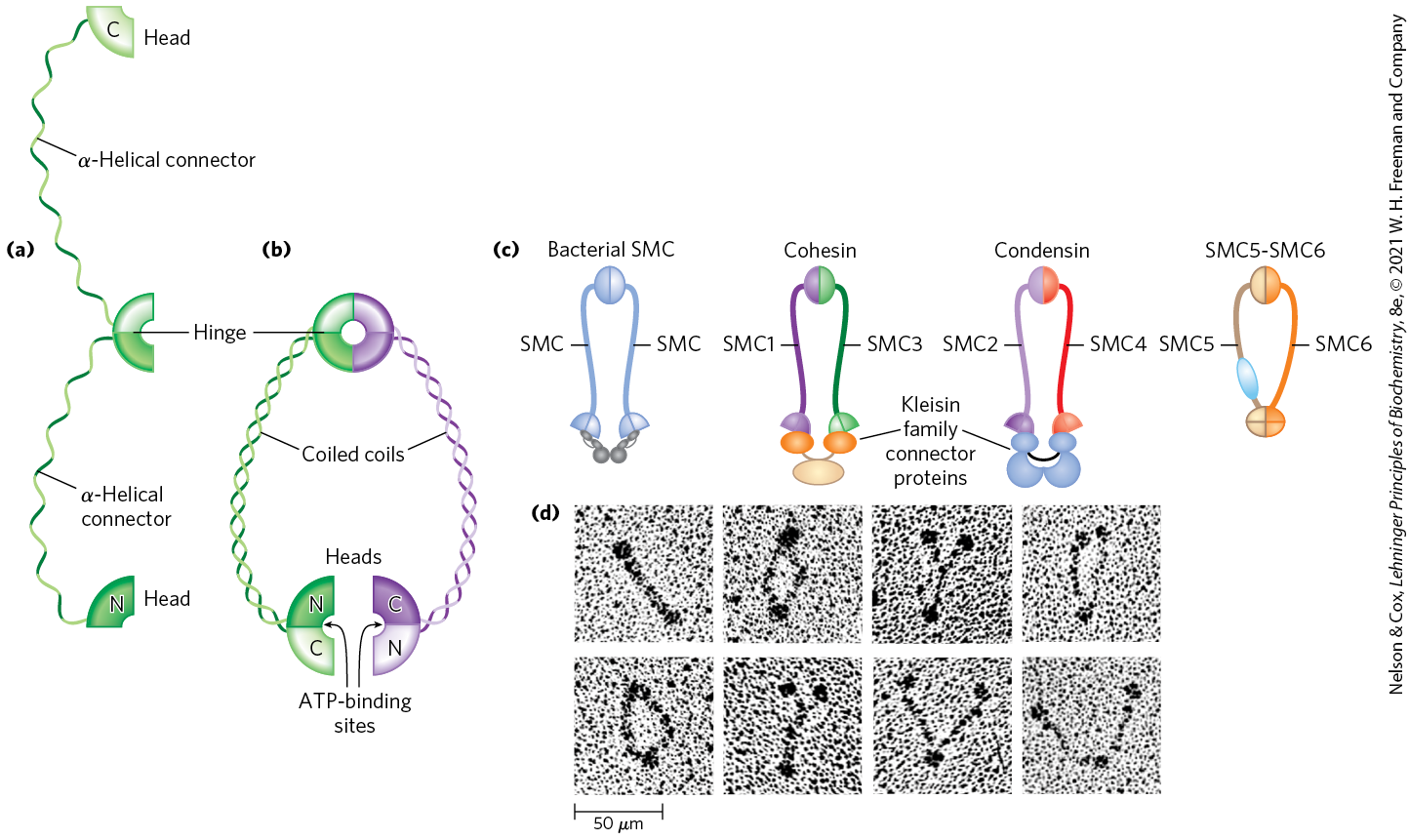
SMC proteins (structural maintenance of chromosomes), the third major class of chromatin protein in addition to the histones and topoisomerases, are responsible for maintaining the structure and integrity of chromosomes following replication. The primary structure of SMC proteins consists of five distinct domains (Fig. 24-31a). The amino- and carboxyl-terminal globular domains, N and C, each of which contains part of an ATP-hydrolytic site, are connected by two regions of α-helical coiled-coil motifs (see Fig. 4-10) joined by a hinge domain. The proteins are generally dimeric, forming a V-shaped complex that is thought to be tied together through the protein’s hinge domains. One N domain and one C domain come together like tweezers to form a complete ATP-hydrolytic site at each free end of the V (Fig. 24-31b).
FIGURE 24-31 Structure of SMC proteins. (a) SMC proteins have five domains. (b) Each SMC polypeptide is folded so that the two coiled-coil domains wrap around each other and the N and C domains come together to form a complete ATP-binding site. Two polypeptides are linked at the hinge region to form the dimeric V-shaped SMC molecule. (c) Bacterial SMC proteins form a homodimer. The six different eukaryotic SMC proteins form heterodimers. Cohesins are made up of SMC1–SMC3 pairs, and condensins consist of SMC2–SMC4 pairs. The SMC5–SMC6 pair is involved in DNA repair. (d) Electron micrographs of SMC dimers from the bacterium Bacillus subtilis. [(a–c) Information from T. Hirano, Nat. Rev. Mol. Cell Biol. 7:311, 2006, Fig. 1. (d) Harold P. Erickson, Duke University Medical Center, Department of Cell Biology.]
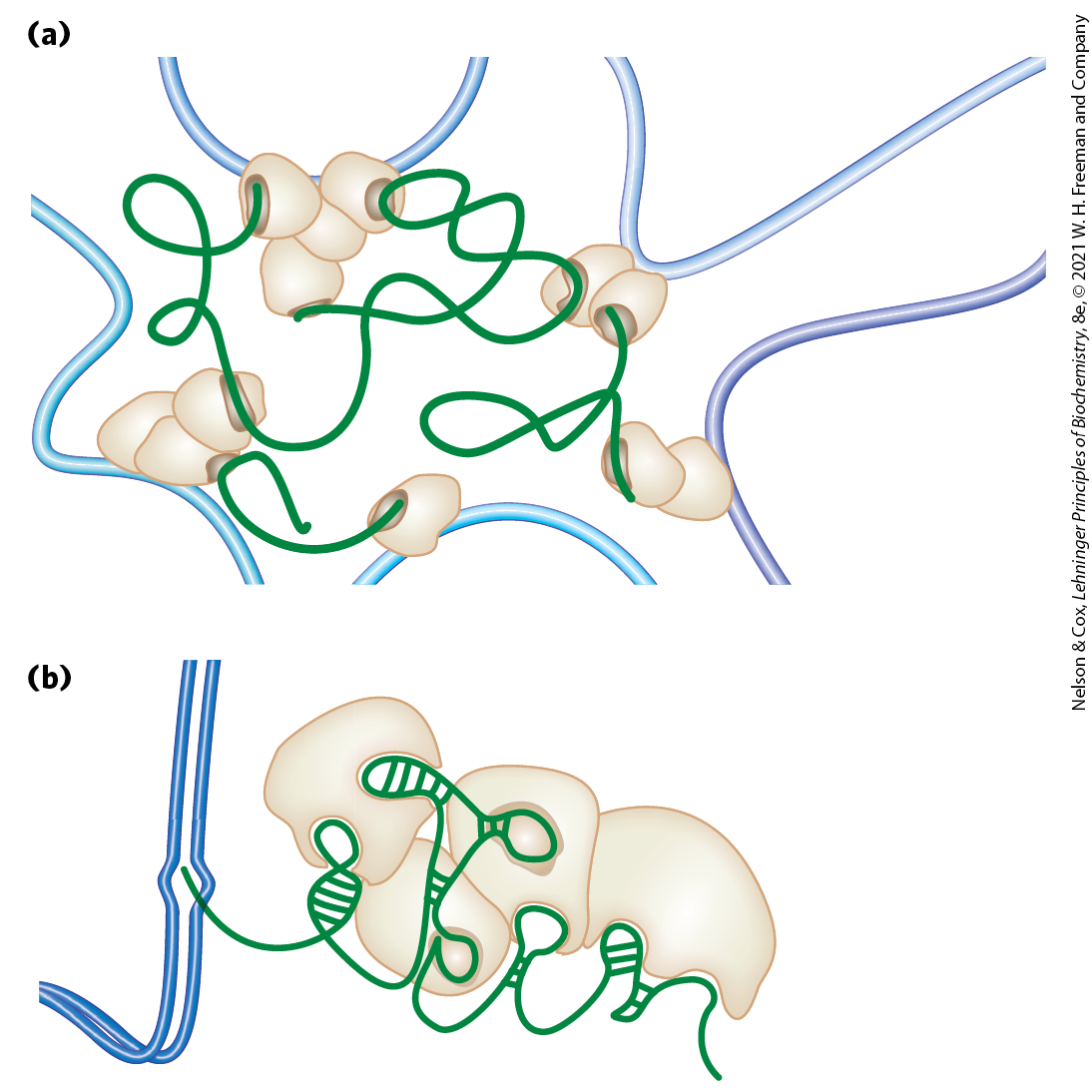
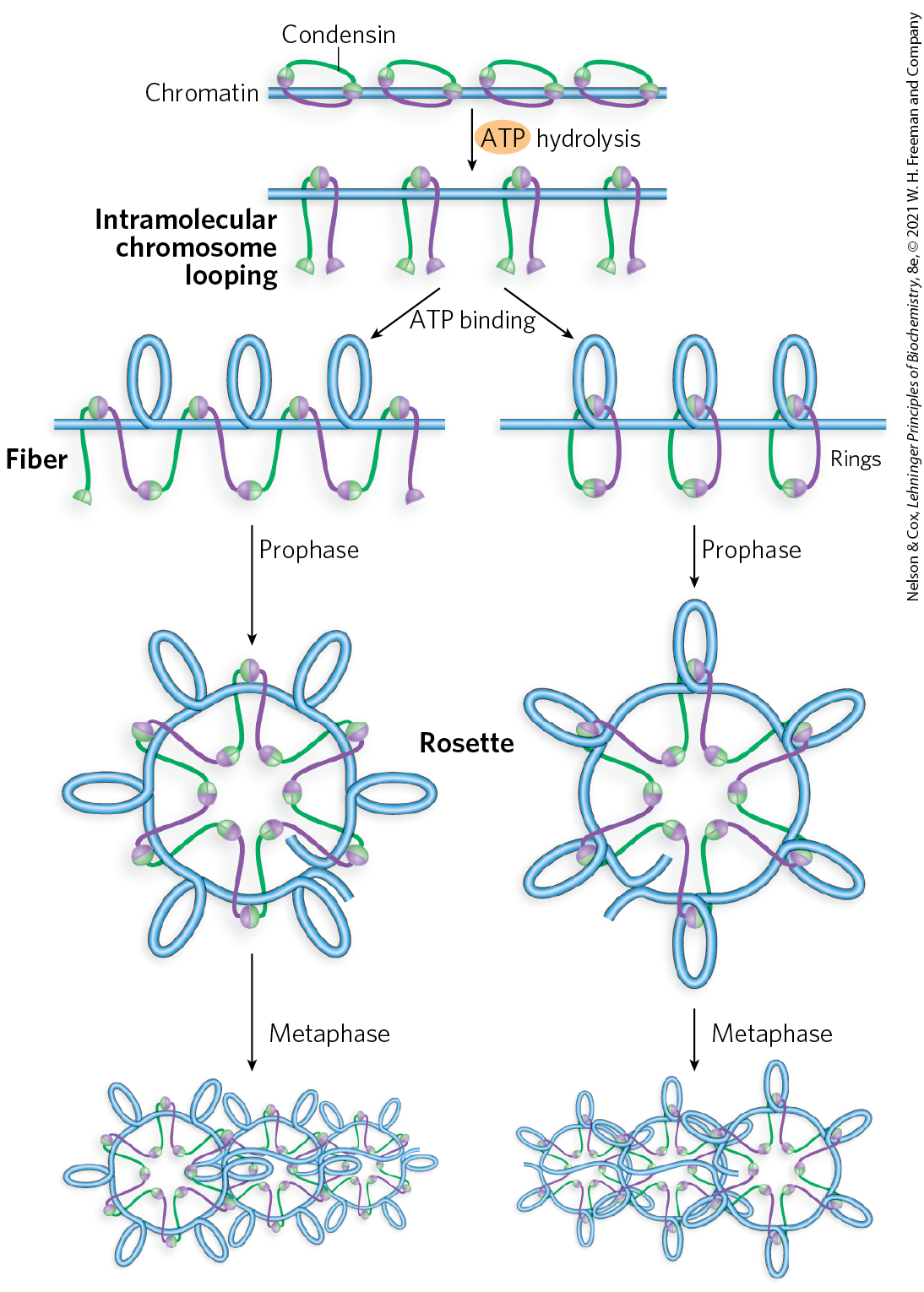
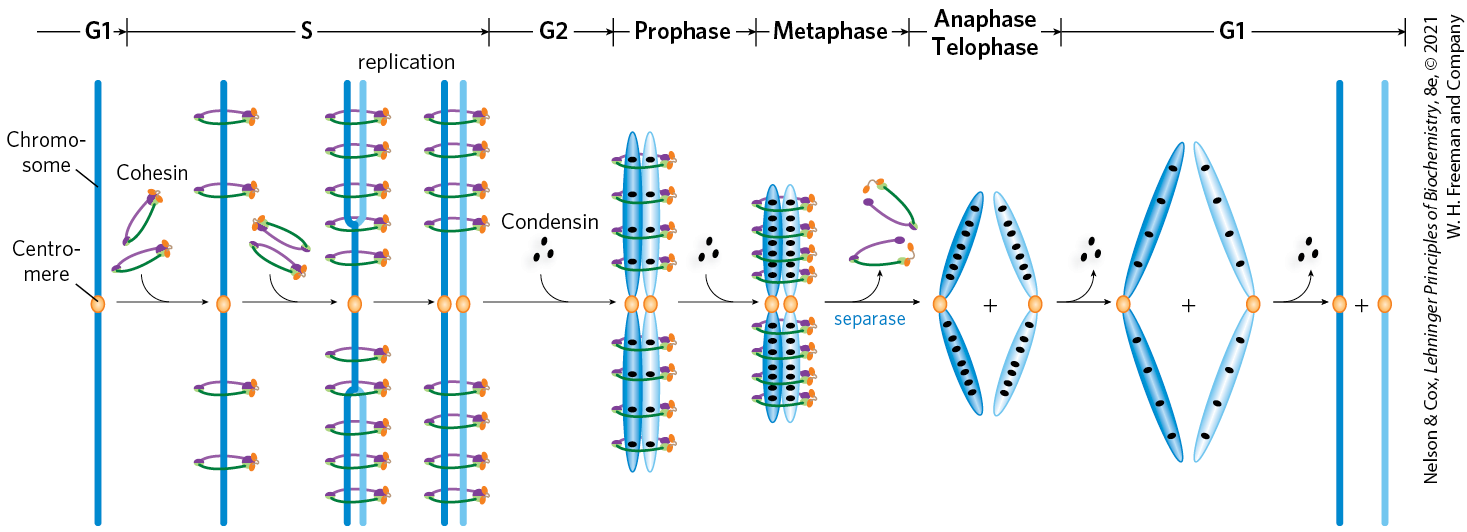
Proteins in the SMC family are found in all types of organisms, from bacteria to humans. Eukaryotes have two major types, cohesins and condensins, both of which are bound by regulatory and accessory proteins (Fig. 24-31c, d). Cohesins play a substantial role in linking together sister chromatids immediately after replication and keeping them together as the chromosomes condense to metaphase. This linkage is essential if chromosomes are to segregate properly at cell division. Cohesins, along with a third protein, kleisin, are thought to form a ring around the replicated chromosomes that ties them together until separation is required. The ring may expand and contract in response to ATP hydrolysis. Condensins are essential to the condensation of chromosomes as cells enter mitosis. In the laboratory, condensins bind to DNA in a manner that creates positive supercoils; that is, condensin binding causes the DNA to become overwound, in contrast to the underwinding induced by the binding of nucleosomes. A model for the role of condensins in chromatin compaction is presented in Figure 24-32. In brief, as DNA is compacted to form tighter and tighter loops, the condensins stabilize the loops by binding at the base of each one. Cohesins and condensins are essential in orchestrating the many changes in chromosome structure during the eukaryotic cell cycle (Fig. 24-33).
FIGURE 24-32 Two current models of the possible role of condensins in chromatin condensation. Initially, the DNA is bound at the hinge region of the SMC protein, in the interior of what can become an intramolecular SMC ring. ATP binding leads to head-to-head association, forming supercoiled loops in the bound DNA. Subsequent rearrangement of the head-to-head interactions to form rosettes condenses the DNA. Condensins may organize the looping of the chromosome segments in several ways. [Information from T. Hirano, Nat. Rev. Mol. Cell Biol. 7:311, 2006, Fig. 6.]
FIGURE 24-33 The roles of cohesins and condensins in the eukaryotic cell cycle. Cohesins are loaded onto the chromosomes during G1 (see Fig. 24-22), tying the sister chromatids together during replication. At the onset of mitosis, condensins bind and maintain the chromatids in a condensed state. During anaphase, the enzyme separase removes the cohesin links. Once the chromatids separate, condensins begin to unload and the daughter chromosomes return to the uncondensed state. [Information from D. P. Bazett-Jones et al., Mol. Cell 9:1183, 2002, Fig. 5.]
Bacterial DNA Is Also Highly Organized
We now turn briefly to the structure of bacterial chromosomes. Bacterial DNA is compacted in a structure called the nucleoid, which can occupy a significant fraction of the cell volume (Fig. 24-34). The DNA seems to be attached at one or more points to the inner surface of the plasma membrane. Much less is known about the structure of the nucleoid than of eukaryotic chromatin, but a complex organization is slowly being revealed. In E. coli, a scaffoldlike structure seems to organize the circular chromosome into a series of about 500 looped domains, each encompassing, on average, 10,000 bp (Fig. 24-35), as described above for chromatin. The domains are topologically constrained; for example, if the DNA is cleaved in one domain, only the DNA within that domain will be relaxed. The domains do not have fixed end points. Instead, the boundaries are most likely in constant motion along the DNA, coordinated with DNA replication.
FIGURE 24-34 E. coli nucleoids. The DNA of these cells is stained with a dye that fluoresces blue when exposed to UV light. The blue areas define the nucleoids. Notice that some cells have replicated their DNA but have not yet undergone cell division and hence have multiple nucleoids.
FIGURE 24-35 Looped domains of the E. coli chromosome. Each domain is about 10,000 bp long. The domains are not static but move along the DNA as replication proceeds. Barriers at the boundaries of the domains, of unknown composition, prevent the relaxation of DNA beyond the boundaries of the domain where a strand break occurs. The putative boundary complexes are shown as gray-shaded ovoids. The arrows denote movement of DNA through the boundary complexes.
Bacterial DNA does not seem to have any structure comparable to the local organization provided by nucleosomes in eukaryotes. Histonelike proteins are abundant in E. coli — the best-characterized example is a two-subunit protein called HU — but these proteins bind and dissociate within minutes, and no regular, stable DNA-histone structure has been found. The dynamic structural changes in the bacterial chromosome may reflect a requirement for more ready access to its genetic information. The bacterial cell division cycle can be as short as 15 min, whereas a typical eukaryotic cell may not divide for hours or even months. In addition, a much greater fraction of bacterial DNA is used to encode RNA and/or protein products. Higher rates of cellular metabolism in bacteria mean that a much higher proportion of the DNA is being transcribed or replicated at a given time than in most eukaryotic cells.
SUMMARY 24.3 The Structure of Chromosomes
A eukaryotic chromosome is made of DNA, protein, and RNA, forming a structure called chromatin.
Histones are small, basic DNA-binding proteins. Complexes of histones form nucleosomes, the fundamental structural unit of chromatin.
The nucleosome consists of histones and a 200 bp segment of DNA. A core protein particle containing eight histone molecules (two copies each of histones H2A, H2B, H3, and H4) is encircled by a segment of DNA (about 146 bp) in the form of a left-handed solenoidal supercoil.
Higher-order folding of chromosomes involves attachment to a chromosomal scaffold. Transcriptionally active and inactive regions of chromosomes are separated into compartments, each featuring large loops of DNA, each loop constrained at its base by proteins and lncRNAs. Individual chromosomes are constrained within nuclear subdomains called territories. Histone H1, topoisomerase II, and SMC proteins play organizational roles in chromosomes.
The SMC proteins, principally cohesins and condensins, have important roles in keeping the chromosomes organized during each stage of the cell cycle.
The bacterial chromosome is extensively compacted into the nucleoid, but the chromosome seems to be much more dynamic and irregular in structure than eukaryotic chromatin, reflecting the shorter cell cycle and very active metabolism of a bacterial cell.
 Chromatin consists of fibers containing protein and DNA in approximately equal proportions (by mass), along with a significant amount of associated RNA. The DNA in the chromatin is very tightly associated with proteins called
Chromatin consists of fibers containing protein and DNA in approximately equal proportions (by mass), along with a significant amount of associated RNA. The DNA in the chromatin is very tightly associated with proteins called 
 Topoisomerase II is so important to the maintenance of chromatin structure that inhibitors of this enzyme can kill rapidly dividing cells. Several drugs used in cancer chemotherapy are topoisomerase II inhibitors that allow the enzyme to promote strand breakage but not the resealing of the breaks (
Topoisomerase II is so important to the maintenance of chromatin structure that inhibitors of this enzyme can kill rapidly dividing cells. Several drugs used in cancer chemotherapy are topoisomerase II inhibitors that allow the enzyme to promote strand breakage but not the resealing of the breaks (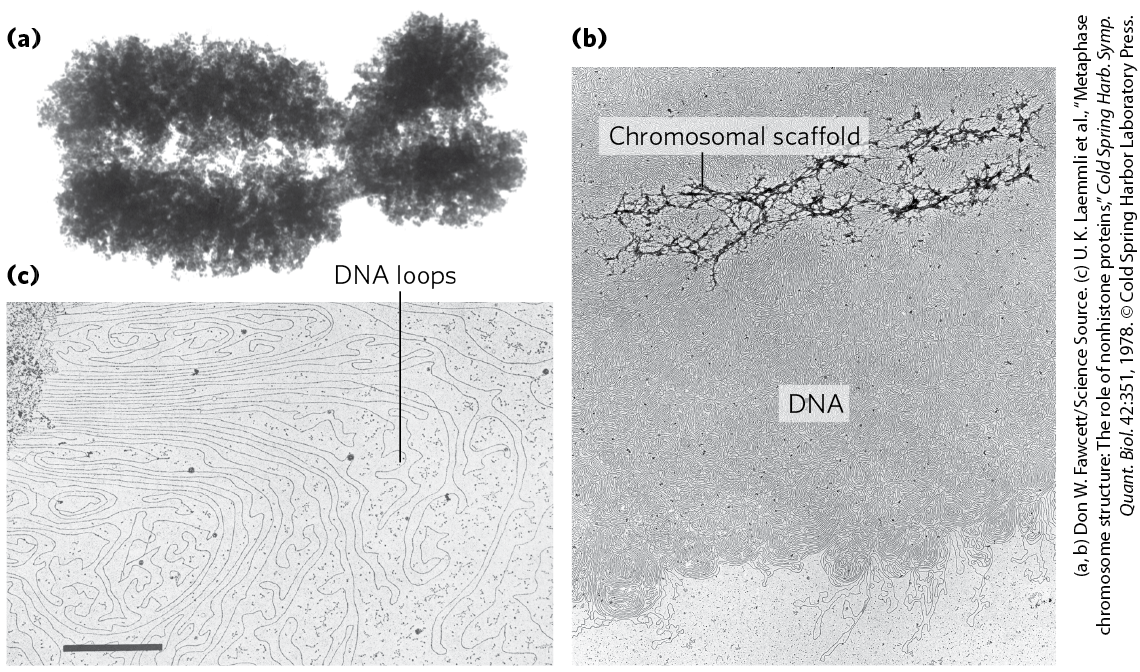
 Bacterial DNA is compacted in a structure called the
Bacterial DNA is compacted in a structure called the 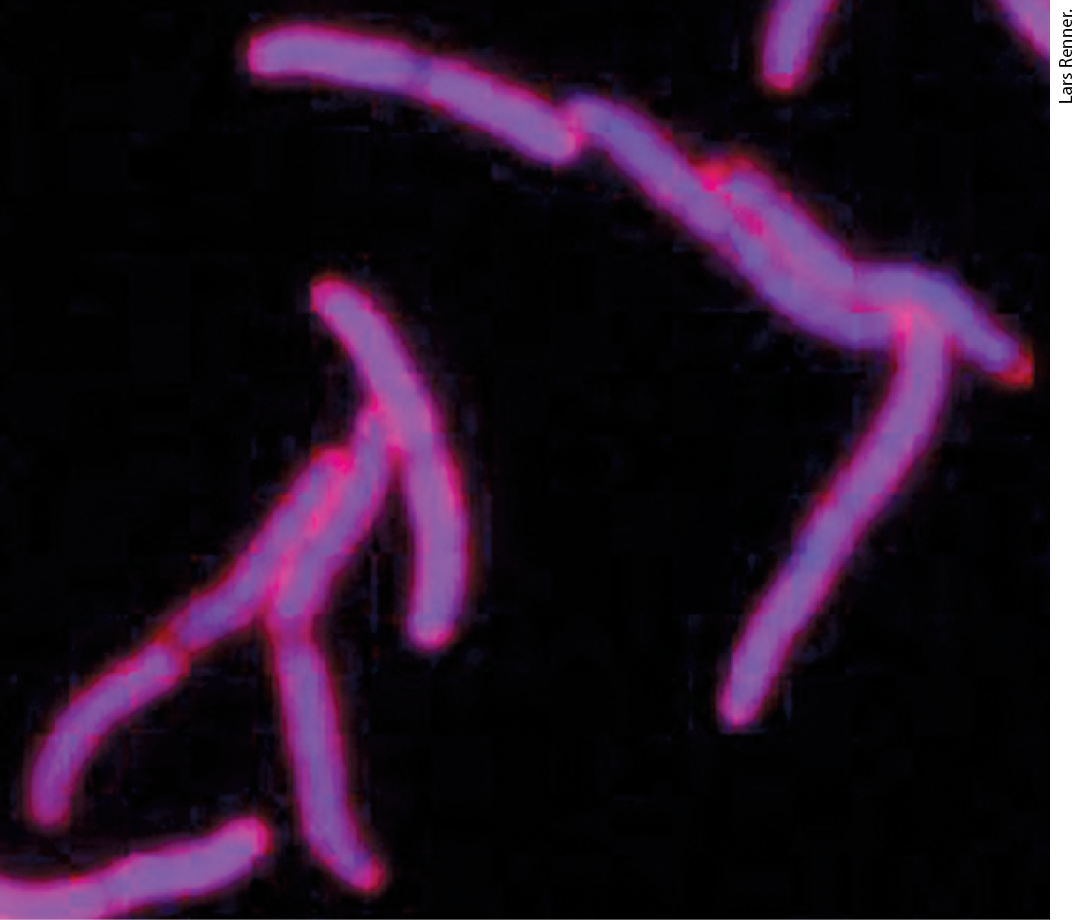
 A eukaryotic chromosome is made of DNA, protein, and RNA, forming a structure called chromatin.
A eukaryotic chromosome is made of DNA, protein, and RNA, forming a structure called chromatin.