Biochemistry aims to explain biological form and function in chemical terms. During the first half of the twentieth century, parallel biochemical investigations of glucose breakdown in yeast and in animal muscle cells revealed remarkable chemical similarities between these two apparently very different cell types; for example, the breakdown of glucose in yeast and in muscle cells involved the same 10 chemical intermediates and the same 10 enzymes. Subsequent studies of many other biochemical processes in many different organisms have confirmed the generality of this observation, neatly summarized in 1954 by the biochemist Jacques Monod: “What is true of E. coli is true of the elephant.” The current understanding that all organisms share a common evolutionary origin is based in part on this observed universality of chemical intermediates and transformations, often termed “biochemical unity.”
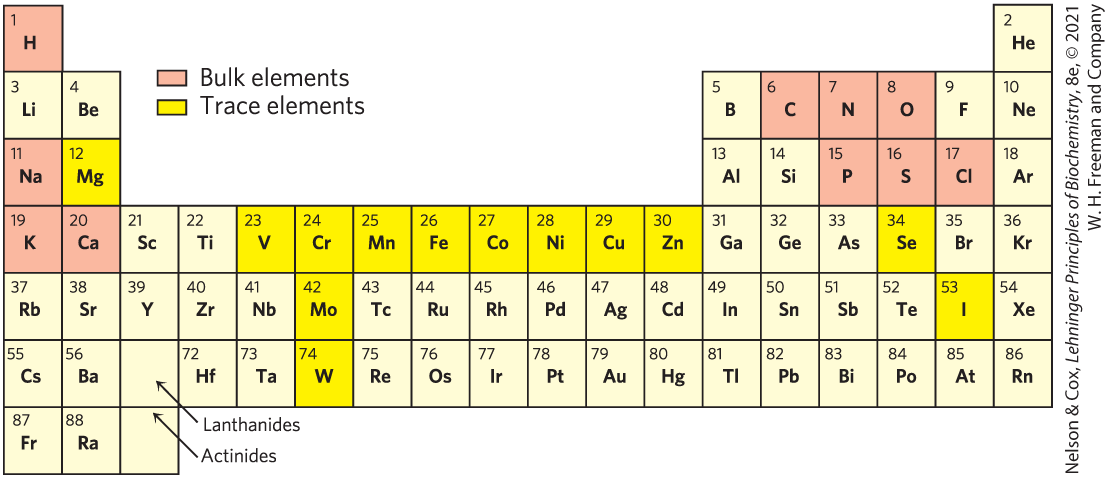
Fewer than 30 of the more than 90 naturally occurring chemical elements are known to be essential to organisms. Most of the elements in living matter have a relatively low atomic number; only three have an atomic number above that of selenium, 34 (Fig. 1-11). The four most abundant elements in living organisms, in terms of percentage of total number of atoms, are hydrogen, oxygen, nitrogen, and carbon, which together make up more than 99% of the mass of most cells. They are the lightest elements capable of efficiently forming one, two, three, and four bonds, respectively; in general, the lightest elements form the strongest bonds. The trace elements represent a miniscule fraction of the weight of the human body, but all are essential to life, usually because they are essential to the function of specific proteins, including many enzymes. The oxygen-transporting capacity of the hemoglobin molecule, for example, is absolutely dependent on four iron ions that make up only 0.3% of the molecule’s mass.
FIGURE 1-11 Elements essential to animal life and health. Bulk elements (shaded light red) are structural components of cells and tissues and are required in the diet in gram quantities daily. For trace elements (shaded yellow), the requirements are much smaller: for humans, a few milligrams per day of Fe, Cu, and Zn, and even less of the others. The elemental requirements for plants and microorganisms are similar to those shown here; the ways in which they acquire these elements vary.
Biomolecules Are Compounds of Carbon with a Variety of Functional Groups
The chemistry of living organisms is organized around carbon, which accounts for more than half of the dry weight of cells. Carbon can form single bonds with hydrogen atoms and can form both single bonds and double bonds with oxygen and nitrogen atoms (Fig. 1-12). Of greatest significance in biology is the ability of carbon atoms to form very stable single bonds with up to four other carbon atoms. Two carbon atoms also can share two (or three) electron pairs, thus forming double (or triple) bonds.
FIGURE 1-12 Versatility of carbon bonding. Carbon can form covalent single, double, and triple bonds (all bonds in red), particularly with other carbon atoms. Triple bonds are rare in biomolecules.
The four single bonds that can be formed by a carbon atom project from the nucleus to the four apices of a tetrahedron (Fig. 1-13), with an angle of about between any two bonds and an average bond length of 0.154 nm. There is free rotation around each single bond, unless very large or highly charged groups are attached to both carbon atoms, in which case rotation may be restricted. A double bond is shorter (about 0.134 nm) and rigid, and it allows only limited rotation about its axis.
FIGURE 1-13 Geometry of carbon bonding. (a) Carbon atoms have a characteristic tetrahedral arrangement of their four single bonds. (b) Carbon–carbon single bonds have freedom of rotation, as shown for the compound ethane (c) Double bonds are shorter and do not allow free rotation. The two doubly bonded carbons and the atoms designated A, B, X, and Y all lie in the same rigid plane.
Covalently linked carbon atoms in biomolecules can form linear chains, branched chains, and cyclic structures. It seems likely that the bonding versatility of carbon, with itself and with other elements, was a major factor in the selection of carbon compounds for the molecular machinery of cells during the origin and evolution of living organisms. No other chemical element can form molecules of such widely different sizes, shapes, and composition.
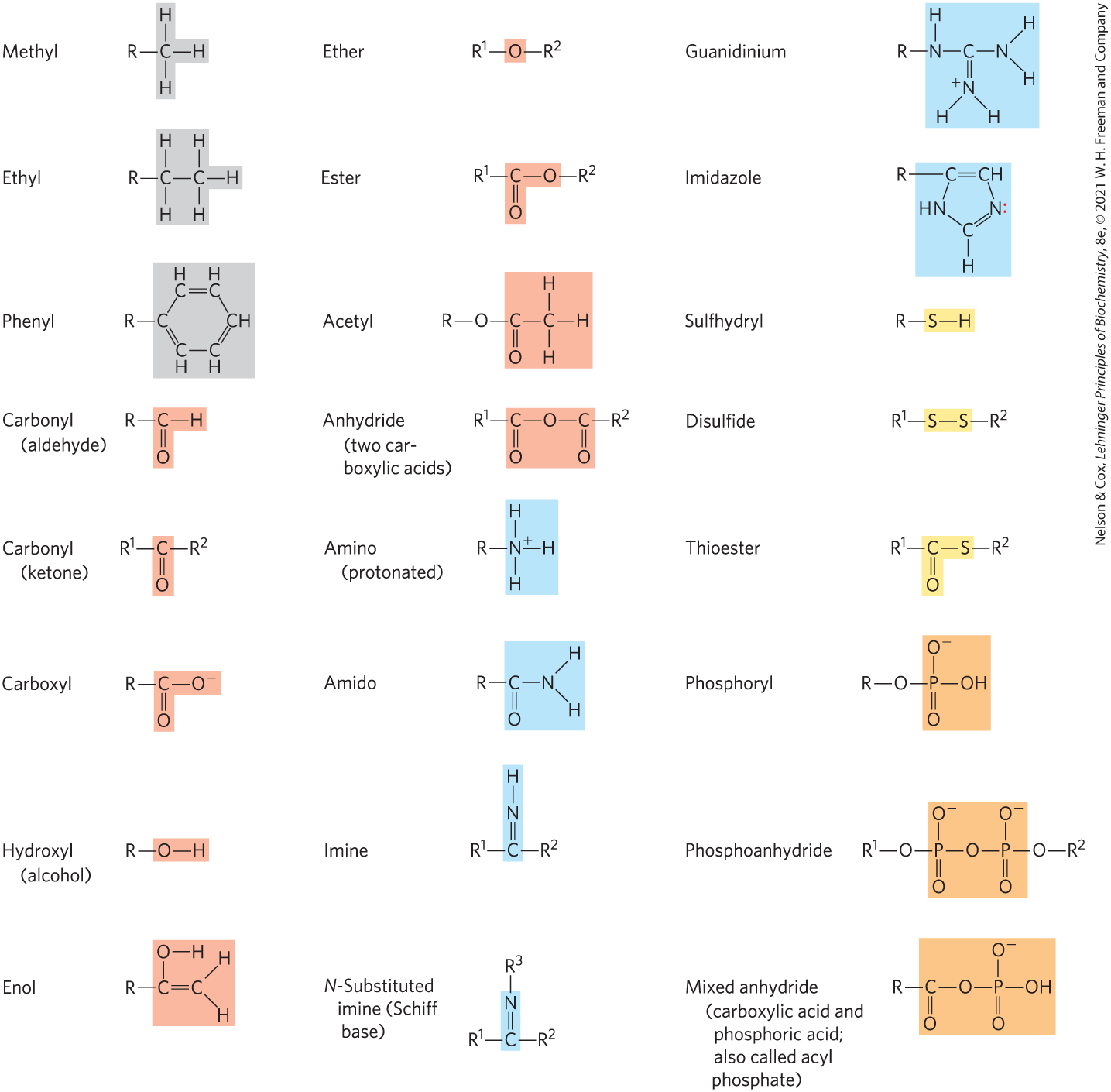
Most biomolecules can be regarded as derivatives of hydrocarbons, with hydrogen atoms replaced by a variety of functional groups that confer specific chemical properties on the molecule, forming various families of organic compounds. Typical of these are alcohols, which have one or more hydroxyl groups; amines, with amino groups; aldehydes and ketones, with carbonyl groups; and carboxylic acids, with carboxyl groups (Fig. 1-14). Many biomolecules are polyfunctional, containing two or more types of functional groups (Fig. 1-15), each with its own chemical characteristics and reactions. The chemical “personality” of a compound is determined by the chemistry of its functional groups and their disposition in three-dimensional space.
FIGURE 1-14 Some common functional groups of biomolecules. Functional groups are screened with a color typically used to represent the element that characterizes the group: gray for C, red for O, blue for N, yellow for S, and orange for P. In this figure and throughout the book, we use R to represent “any substituent.” It may be as simple as a hydrogen atom, but typically it is a carbon-containing group. When two or more substituents are shown in a molecule, we designate them and so forth.
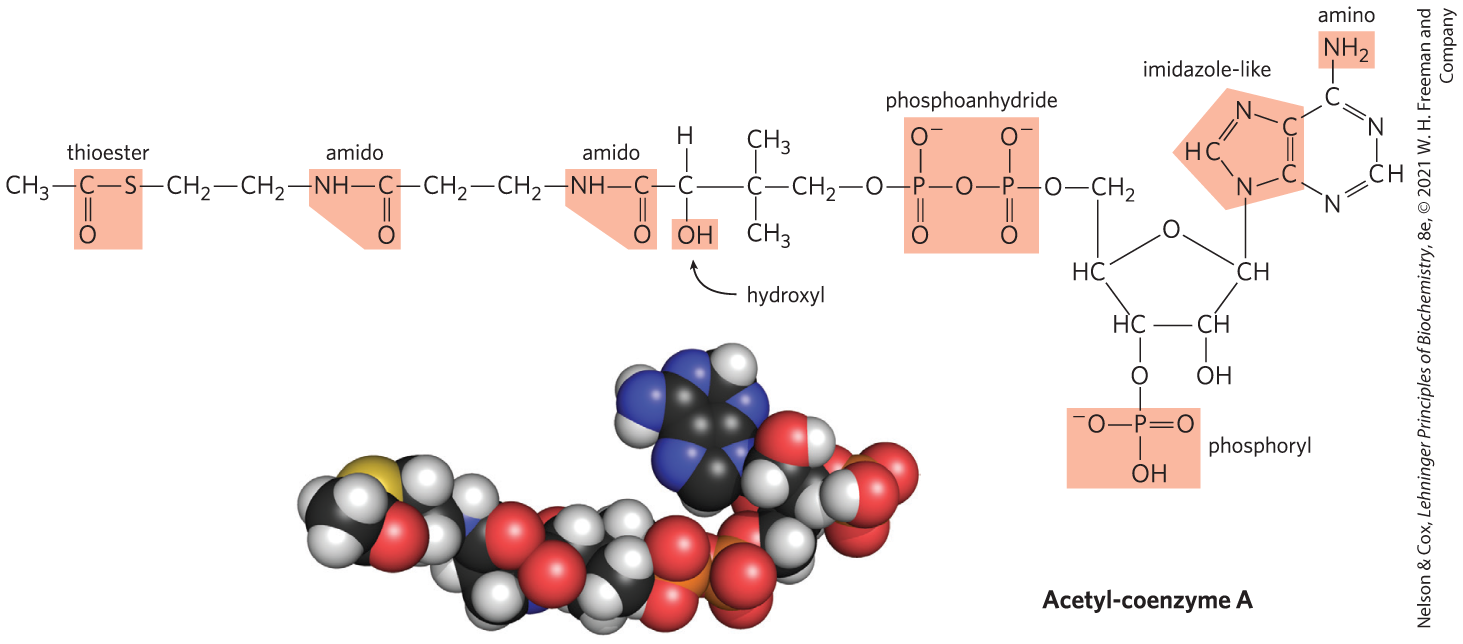
FIGURE 1-15 Several common functional groups in a single biomolecule. Acetyl-coenzyme A (often abbreviated as acetyl-CoA) is a carrier of acetyl groups in some enzymatic reactions. Its functional groups are screened in the structural formula. In the space-filling model, N is blue, C is black, P is orange, O is red, and H is white. The yellow atom at the left is the sulfur of the critical thioester bond between the acetyl moiety and coenzyme A. [Acetyl-CoA structure data from PDB ID 1DM3, Y. Modis and R. K. Wierenga, J. Mol. Biol. 297:1171, 2000.]
Cells Contain a Universal Set of Small Molecules
Dissolved in the aqueous phase (cytosol) of all cells is a collection of perhaps several thousand different small organic molecules with intracellular concentrations ranging from nanomolar to > 10 mm (see Fig. 13-31). (See Box 1-1 for an explanation of the various ways of referring to molecular weight.) These are the central metabolites in the major pathways occurring in nearly every cell — the metabolites and pathways that have been conserved throughout the course of evolution. This collection of molecules includes the common amino acids, nucleotides, sugars and their phosphorylated derivatives, and mono-, di-, and tricarboxylic acids. The molecules may be polar or charged and most are water-soluble. They are trapped in the cell because the plasma membrane is impermeable to them, although specific membrane transporters can catalyze the movement of some molecules into and out of the cell or between compartments in eukaryotic cells. The universal occurrence of the same set of compounds in living cells reflects the evolutionary conservation of metabolic pathways that developed in the earliest cells.
There are other small biomolecules, specific to certain types of cells or organisms. For example, vascular plants contain, in addition to the universal set, small molecules called secondary metabolites, which play roles specific to plant life. These metabolites include compounds that give plants their characteristic scents and colors, and compounds such as morphine, quinine, nicotine, and caffeine that are valued for their physiological effects on humans but have other purposes in plants.
The entire collection of small molecules in a given cell under a specific set of conditions has been called the metabolome, in parallel with the term “genome.” Metabolomics is the systematic characterization of the metabolome under very specific conditions (such as following administration of a drug, or a biological signal such as insulin).
Macromolecules Are the Major Constituents of Cells
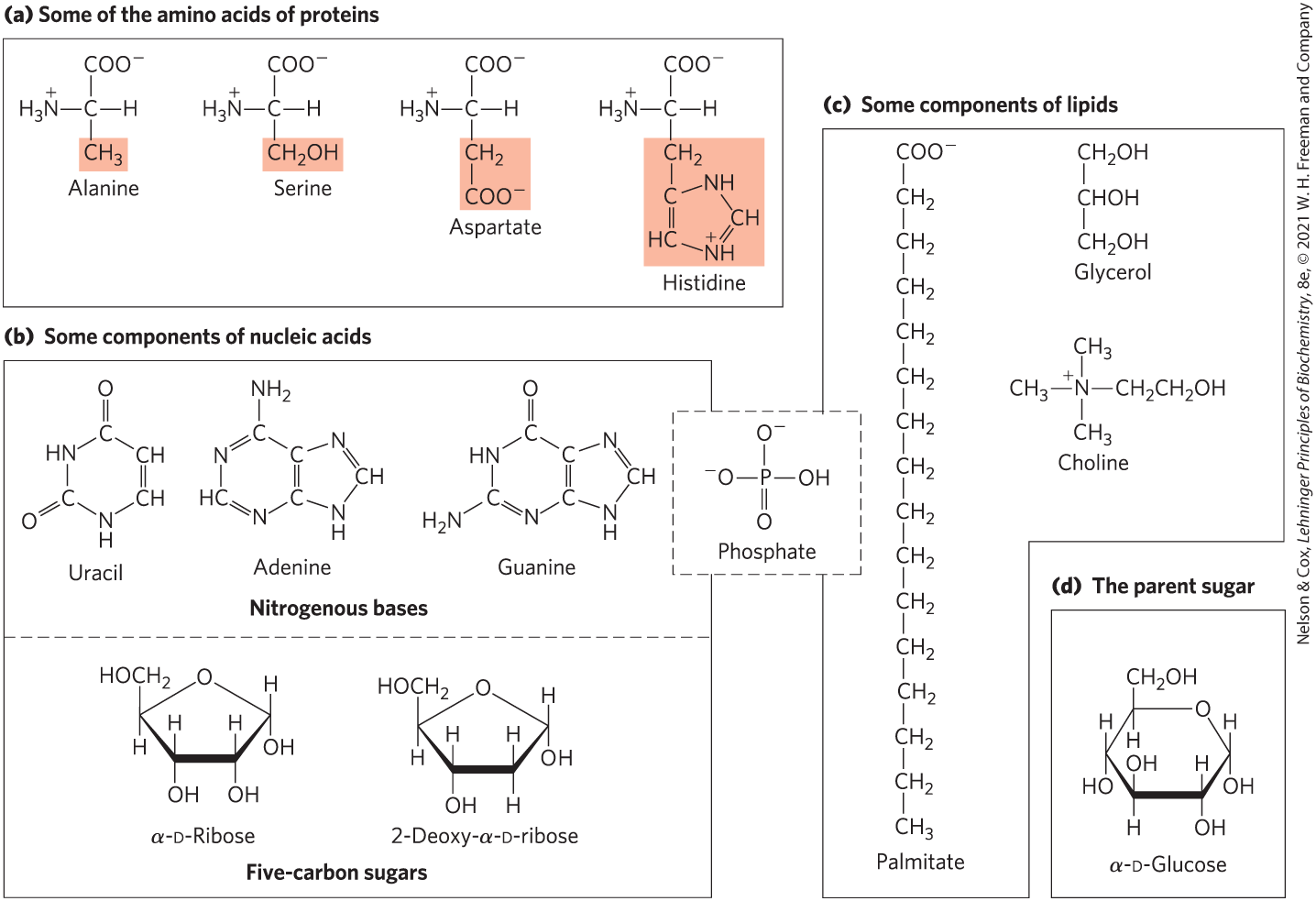
Many biological molecules are macromolecules, polymers with molecular weights above ~5,000 that are assembled from relatively simple precursors (Fig. 1-16). Shorter polymers are called oligomers (Greek oligos, “few”). Proteins, nucleic acids, and polysaccharides are macromolecules composed of monomers with molecular weights of 500 or less. Synthesis of macromolecules is a major energy-consuming activity of cells. Macromolecules themselves may be further assembled into supramolecular complexes, forming functional units such as ribosomes. Table 1-1 shows the major classes of biomolecules in an E. coli cell.
FIGURE 1-16 The organic compounds from which most cellular materials are constructed: the ABCs of biochemistry. Shown here are (a) 4 of the 20 amino acids from which all proteins are built (the side chains are shaded light red); (b) 3 of the 5 nitrogenous bases, the two 5-carbon sugars, and the phosphate ion from which all nucleic acids are built; (c) 4 components of membrane lipids (including phosphate); and (d) d-glucose, the simple sugar from which most carbohydrates are derived.
Source: A. C. Guo et al., Nucleic Acids Res. 41:D625, 2013.
aIf all permutations and combinations of fatty acid substituents are considered, this number is much larger.
Proteins, long polymers of amino acids, constitute the largest mass fraction (besides water) of a cell. Some proteins have catalytic activity and function as enzymes; others serve as structural elements, signal receptors, or transporters that carry specific substances into or out of cells. Proteins are perhaps the most versatile of all biomolecules; a catalog of their many functions would be very long. The sum of all the proteins functioning in a given cell is the cell’s proteome, and proteomics is the systematic characterization of this protein complement under a specific set of conditions. The nucleic acids, DNA and RNA, are polymers of nucleotides. They store and transmit genetic information, and some RNA molecules have structural and catalytic roles in supramolecular complexes. The genome is the entire sequence of a cell’s DNA (or in the case of RNA viruses, its RNA), and genomics is the characterization of the structure, function, evolution, and mapping of genomes.
The polysaccharides, polymers of simple sugars such as glucose, have three major functions: as energy-rich fuel stores, as rigid structural components of cell walls (in plants and bacteria), and as extracellular recognition elements that bind to proteins on other cells. Shorter polymers of sugars (oligosaccharides) attached to proteins or lipids at the cell surface serve as specific cellular signals. A cell’s glycome is its entire complement of carbohydrate-containing molecules. The lipids, water-insoluble hydrocarbon derivatives, serve as structural components of membranes, energy-rich fuel stores, pigments, and intracellular signals. The lipid-containing molecules in a cell constitute its lipidome.
Proteins, polynucleotides, and polysaccharides have large numbers of monomeric subunits and thus high molecular weights — in the range of 5,000 to more than 1 million for proteins, up to several billion for DNA, and in the millions for polysaccharides such as starch. Individual lipid molecules are much smaller ( 750 to 1,500) and are not classified as macromolecules, but they can associate noncovalently into very large structures. Cellular membranes are built of enormous noncovalent aggregates of lipid and protein molecules.
Given their characteristic information-rich subunit sequences, proteins and nucleic acids are often referred to as informational macromolecules. Some oligosaccharides, as noted above, also serve as informational molecules.
Three-Dimensional Structure Is Described by Configuration and Conformation
The covalent bonds and functional groups of a biomolecule are, of course, central to its function, but so also is the arrangement of the molecule’s constituent atoms in three-dimensional space — its stereochemistry. Carbon-containing compounds commonly exist as stereoisomers, molecules with the same chemical bonds and same chemical formula but different configuration, the fixed spatial arrangement of atoms. Interactions between biomolecules are typically stereospecific, requiring specific configurations in the interacting molecules.
Figure 1-17 shows three ways to illustrate the stereochemistry, or configuration, of simple molecules. The perspective diagram specifies stereochemistry unambiguously, but bond angles and center-to-center bond lengths are better represented with ball-and-stick models. In space-filling models, the radius of each “atom” is proportional to its van der Waals radius, and the contours of the model define the space occupied by the molecule (the volume of space from which atoms of other molecules are excluded).
FIGURE 1-17 Representations of molecules. Three ways to represent the structure of the amino acid alanine (shown here in the ionic form found at neutral pH). (a) Structural formula in perspective form: a solid wedge represents a bond in which the atom at the wide end projects out of the plane of the paper, toward the reader; a dashed wedge represents a bond extending behind the plane of the paper. (b) Ball-and-stick model, showing bond angles and relative bond lengths. (c) Space-filling model, in which each atom is shown with its correct relative van der Waals radius.
Configuration is conferred by the presence of either (1) double bonds, around which there is little or no freedom of rotation, or (2) chiral centers, around which substituent groups are arranged in a specific orientation. The identifying characteristic of stereoisomers is that they cannot be interconverted without the temporary breaking of one or more covalent bonds. Figure 1-18a shows the configurations of maleic acid and its isomer, fumaric acid. These compounds are geometric isomers, or cis-trans isomers; they differ in the arrangement of their substituent groups with respect to the nonrotating double bond (Latin cis, “on this side” — groups on the same side of the double bond; trans, “across” — groups on opposite sides). Maleic acid (maleate at the neutral pH of cytoplasm) is the cis isomer, and fumaric acid (fumarate) is the trans isomer; each is a well-defined compound that can be separated from the other, and each has its own unique chemical properties. A binding site (on an enzyme, for example) that is complementary to one of these molecules would not be complementary to the other, which explains why the two compounds have distinct biological roles despite their similar chemical makeup. The visual pigment in the vertebrate eye, rhodopsin, contains retinal, a vitamin A–derived lipid (Fig. 1-18b). In the primary event of vision, light converts one isomer of retinal to another, triggering a neuronal signal to the brain (see Fig. 12-19).
FIGURE 1-18 Configurations of geometric isomers. (a) Isomers such as maleic acid (maleate at pH 7) and fumaric acid (fumarate) cannot be interconverted without breaking covalent bonds, which requires the input of much more energy than the average kinetic energy of molecules at physiological temperatures. (b) In the vertebrate retina, the initial event in light detection is the absorption of visible light by 11-cis-retinal. The energy of the absorbed light (about 250 kJ/mol) converts 11-cis-retinal to all-trans-retinal, triggering electrical changes in the retinal cell that lead to a nerve impulse. (Note that the hydrogen atoms are omitted from the ball-and-stick models of the retinals.)
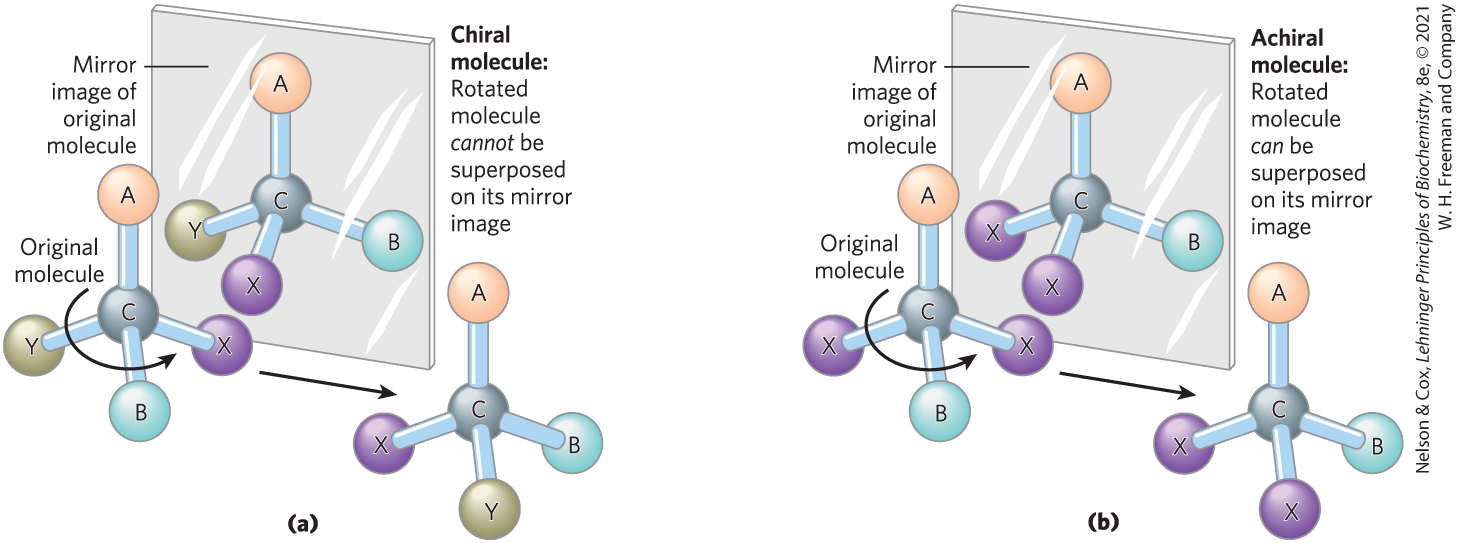
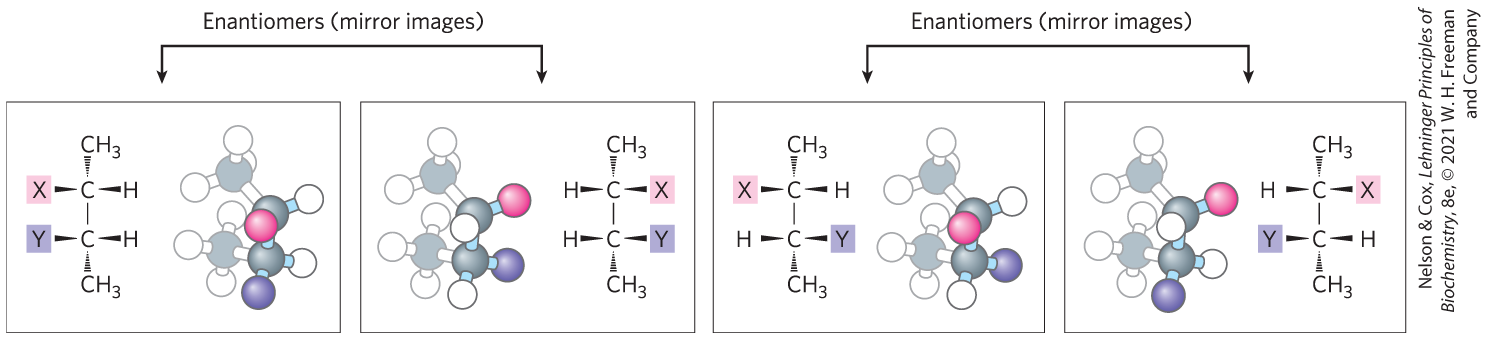
In the second type of stereoisomer, four different substituents bonded to a tetrahedral carbon atom may be arranged in two different ways in space — that is, have two configurations — yielding two stereoisomers that have similar or identical chemical properties but differ in certain physical and biological properties. A carbon atom with four different substituents is said to be asymmetric, and asymmetric carbons are called chiral centers (Greek chiros, “hand”; some stereoisomers are related structurally as the right hand is to the left hand). A molecule with only one chiral carbon can have two stereoisomers; when two or more (n) chiral carbons are present, there can be stereoisomers. Stereoisomers that are mirror images of each other are called enantiomers (Fig. 1-19). Pairs of stereoisomers that are not mirror images of each other are called diastereomers (Fig. 1-20).
FIGURE 1-19 Molecular asymmetry: chiral and achiral molecules. (a) When a carbon atom has four different substituent groups (A, B, X, Y), they can be arranged in two ways that represent nonsuperposable mirror images of each other (enantiomers). This asymmetric carbon atom is called a chiral atom or chiral center. (b) When a tetrahedral carbon has only three dissimilar groups (that is, the same group occurs twice), only one configuration is possible and the molecule is symmetric, or achiral. In this case, the molecule is superposable on its mirror image: the molecule on the left can be rotated counterclockwise (when looking down the vertical bond from A to C) to create the molecule in the mirror.
FIGURE 1-20 Enantiomers and diastereomers. There are four different stereoisomers of 2,3-disubstituted butane (n = 2 asymmetric carbons, hence stereoisomers). Each is shown in a box as a perspective formula and a ball-and-stick model, which has been rotated to show all of the groups. Two pairs of stereoisomers are mirror images of each other, or enantiomers. All other possible pairs are not mirror images, and so are diastereomers. [Information from F. Carroll, Perspectives on Structure and Mechanism in Organic Chemistry, p. 63, Brooks/Cole Publishing Co., 1998.]
As the biologist, microbiologist, and chemist Louis Pasteur first observed in 1843 (Box 1-2), enantiomers have nearly identical chemical reactivities but differ in a characteristic physical property: optical activity. In separate solutions, two enantiomers rotate the plane of plane-polarized light in opposite directions, but an equimolar solution of the two enantiomers (a racemic mixture) shows no optical rotation. Compounds without chiral centers do not rotate the plane of plane-polarized light.
Key convention
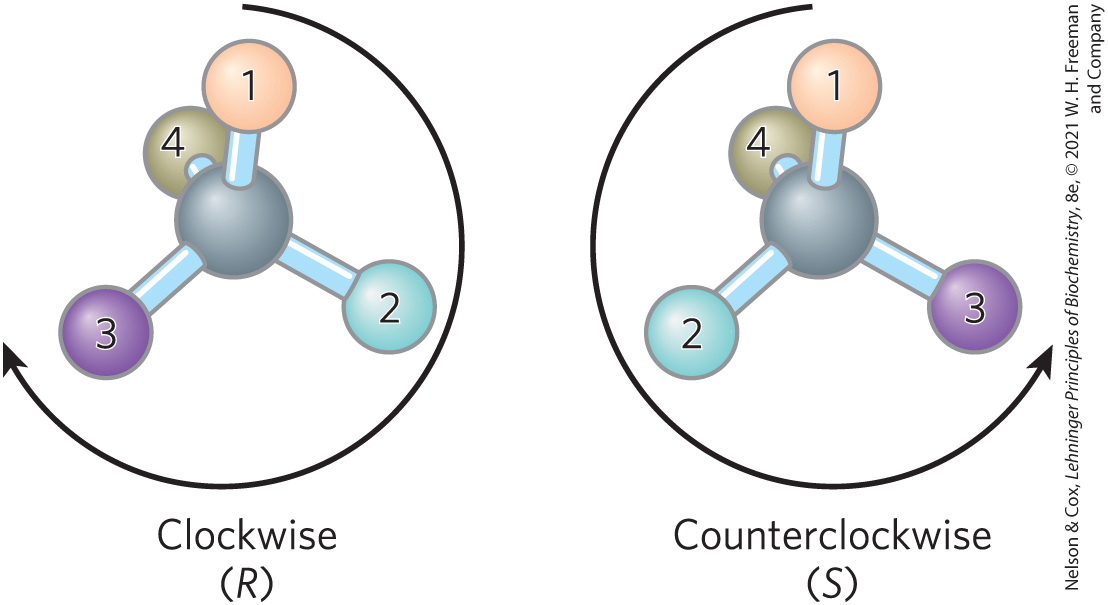
Given the importance of stereochemistry in reactions between biomolecules (see below), biochemists must name and represent the structure of each biomolecule so that its stereochemistry is unambiguous. For compounds with more than one chiral center, the most useful system of nomenclature is the RS system. In this system, each group attached to a chiral carbon is assigned a priority. The priorities of some common substituents are
For naming in the RS system, the chiral atom is viewed with the group of lowest priority (4 in the following diagram) pointing away from the viewer. If the priority of the other three groups (1 to 3) decreases in clockwise order, the configuration is (R) (Latin rectus, “right”); if counterclockwise, the configuration is (S) (Latin sinister, “left”). In this way, each chiral carbon is designated either (R) or (S), and the inclusion of these designations in the name of the compound provides an unambiguous description of the stereochemistry at each chiral center.
Another naming system for stereoisomers, the d and l system, is described in Chapter 3. A molecule with a single chiral center can be named unambiguously by either system, as shown here. The two naming systems are based on different criteria, so no general correlation can be made between, say, the l isomer and the (S) isomer seen in this example.
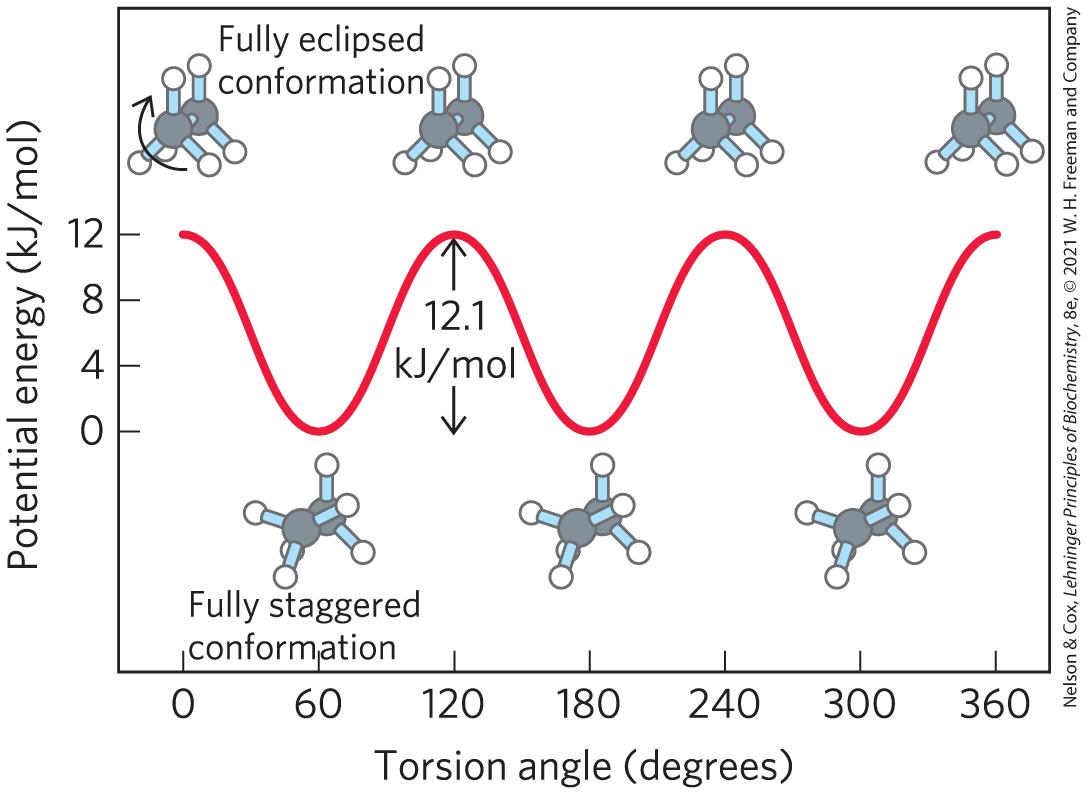
Distinct from configuration is molecular conformation, the spatial arrangement of substituent groups that, without breaking any bonds, are free to assume different positions in space because of the freedom of rotation about single bonds. In the simple hydrocarbon ethane, for example, there is nearly complete freedom of rotation around the bond. Many different, interconvertible conformations of ethane are possible, depending on the degree of rotation (Fig. 1-21). Two conformations are of special interest: the staggered, which is more stable than all others and thus predominates, and the eclipsed, which is the least stable. We cannot isolate either of these conformational forms, because they are freely interconvertible. However, when one or more of the hydrogen atoms on each carbon is replaced by a functional group that is either very large or electrically charged, freedom of rotation around the bond is hindered. This limits the number of stable conformations of the ethane derivative.
FIGURE 1-21 Conformations. Many conformations of ethane are possible because of freedom of rotation around the bond. In the ball-and-stick model, when the front carbon atom (as viewed by the reader) with its three attached hydrogens is rotated relative to the rear carbon atom, the potential energy of the molecule rises to a maximum in the fully eclipsed conformation (torsion angle and so on), then falls to a minimum in the fully staggered conformation (torsion angle and so on). Because the energy differences are small enough to allow rapid interconversion of the two forms (millions of times per second), the eclipsed and staggered forms cannot be separately isolated.
Interactions between Biomolecules Are Stereospecific
When biomolecules interact, the “fit” between them is often stereochemically correct; they are complementary. The three-dimensional structure of biomolecules large and small — the combination of configuration and conformation — is of the utmost importance in their biological interactions: reactant with its enzyme, hormone with its receptor, antigen with its specific antibody, for example (Fig. 1-22). The study of biomolecular stereochemistry, with precise physical methods, is an important part of modern research on cell structure and biochemical function.
FIGURE 1-22 Complementary fit between a macromolecule and a small molecule. A glucose molecule fits into a pocket on the surface of the enzyme hexokinase and is held in this orientation by several noncovalent interactions between the protein and the sugar. This representation of the hexokinase molecule is produced with software that can calculate the shape of the outer surface of a macromolecule, defined either by the van der Waals radii of all the atoms in the molecule or by the “solvent exclusion volume,” the volume that a water molecule cannot penetrate. [Data from PDB ID 3B8A, P. Kuser et al., Proteins 72:731, 2008.]
In living organisms, chiral molecules are usually present in only one of their chiral forms. For example, the amino acids in proteins occur only as their l isomers; glucose occurs only as its d isomer. (The conventions for naming stereoisomers of the amino acids are described in Chapter 3; those for sugars, in Chapter 7. The RS system, described above, is the most useful for some biomolecules.) In contrast, when a compound with an asymmetric carbon atom is chemically synthesized in the laboratory, the reaction usually produces both possible chiral forms: a mixture of the d and l forms, for example. Living cells produce only one chiral form of a biomolecule because the enzymes that synthesize that molecule are also chiral.
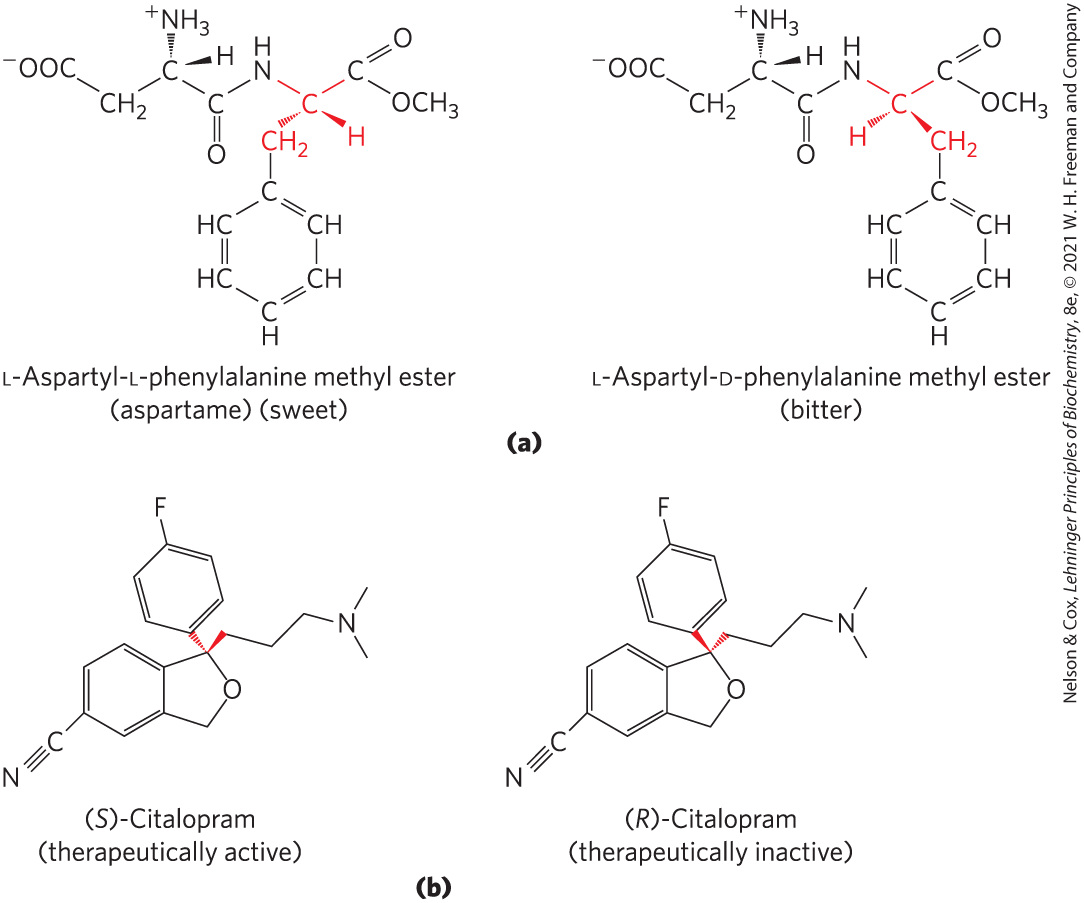
Stereospecificity, the ability to distinguish between stereoisomers, is a property of enzymes and other proteins and a characteristic feature of biochemical interactions. If the binding site on a protein is complementary to one isomer of a chiral compound, it will not be complementary to the other isomer, for the same reason that a left-handed glove does not fit a right hand. Two striking examples of the ability of biological systems to distinguish stereoisomers are shown in Figure 1-23.
FIGURE 1-23 Stereoisomers have different effects in humans. (a) Aspartame, the artificial sweetener sold under the trade name Nutra-Sweet, is easily distinguishable by taste receptors from its bitter-tasting stereoisomer, although the two differ only in the configuration at one of the two chiral carbon atoms. (b) The antidepressant medication citalopram (trade name Celexa), a selective serotonin reuptake inhibitor, is a racemic mixture of these two stereoisomers, but only (S)-citalopram has the therapeutic effect. A stereochemically pure preparation of (S)-citalopram (escitalopram oxalate) is sold under the trade name Lexapro. As you might predict, the effective dose of Lexapro is one-half the effective dose of Celexa.
The common classes of chemical reactions encountered in biochemistry are described in Chapter 13, as an introduction to the reactions of metabolism.
SUMMARY 1.2 Chemical Foundations
Because of its bonding versatility, carbon can produce a broad array of carbon–carbon skeletons with a variety of functional groups; these groups give biomolecules their biological and chemical personalities.
A nearly universal set of several thousand small molecules is found in living cells; the interconversions of these molecules in the central metabolic pathways have been conserved in evolution.
Proteins and nucleic acids are macromolecules — long, linear polymers of simple monomeric subunits; their sequences contain the information that gives each molecule its three-dimensional structure and its biological functions.
Molecular configuration can be changed only by breaking and re-forming covalent bonds. For a carbon atom with four different substituents (a chiral carbon), the substituent groups can be arranged in two different ways, generating stereoisomers with distinct properties. Only one stereoisomer is biologically active. Molecular conformation is the position of atoms in space that can be changed by rotation about single bonds, without covalent bonds being broken.
Interactions between biological molecules are often stereospecific: there is a close fit between complementary structures in the interacting molecules.



 represents a bond in which the atom at the wide end projects out of the plane of the paper, toward the reader; a dashed wedge
represents a bond in which the atom at the wide end projects out of the plane of the paper, toward the reader; a dashed wedge  represents a bond extending behind the plane of the paper. (b) Ball-and-stick model, showing bond angles and relative bond lengths. (c) Space-filling model, in which each atom is shown with its correct relative van der Waals radius.
represents a bond extending behind the plane of the paper. (b) Ball-and-stick model, showing bond angles and relative bond lengths. (c) Space-filling model, in which each atom is shown with its correct relative van der Waals radius.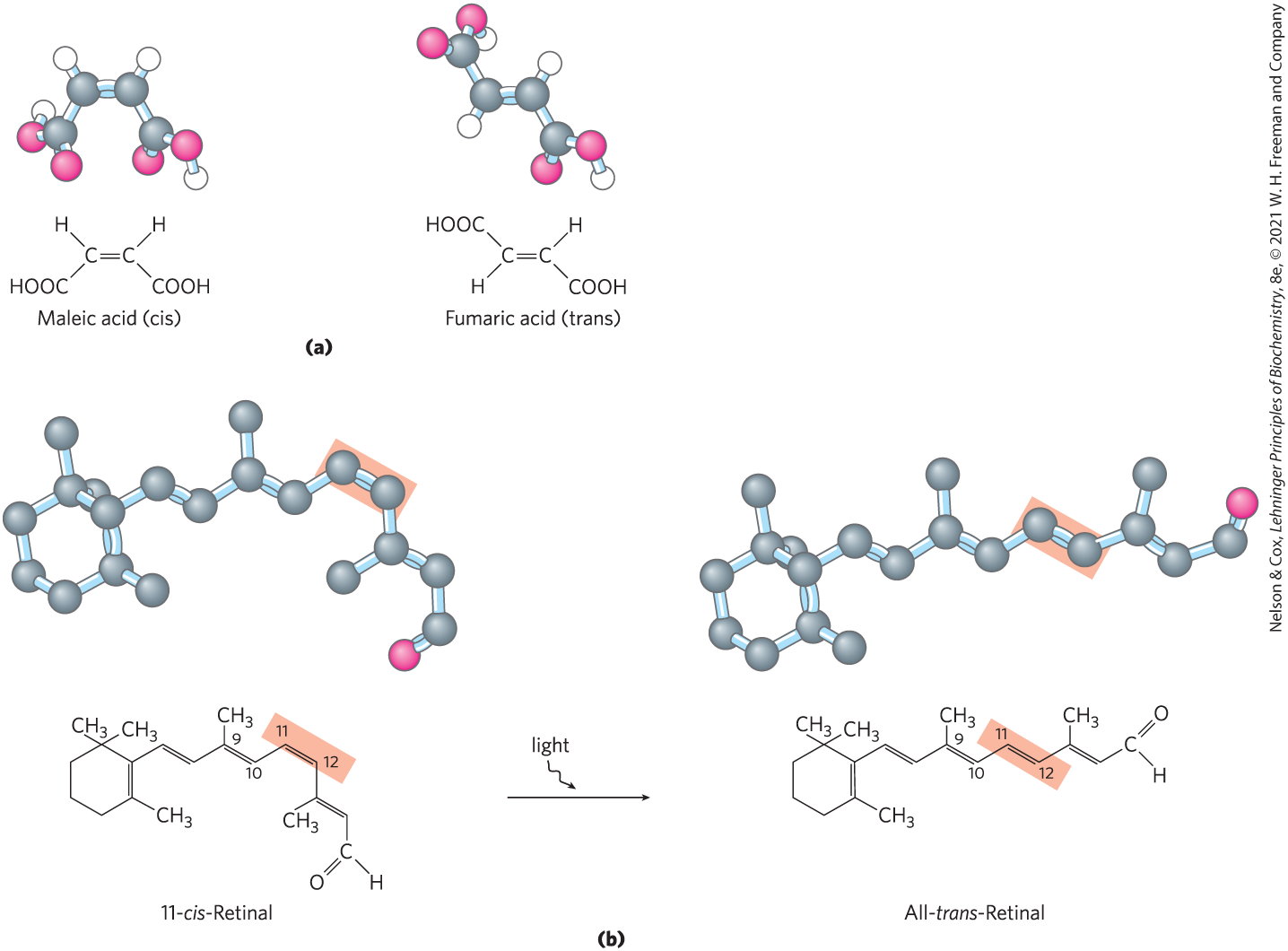
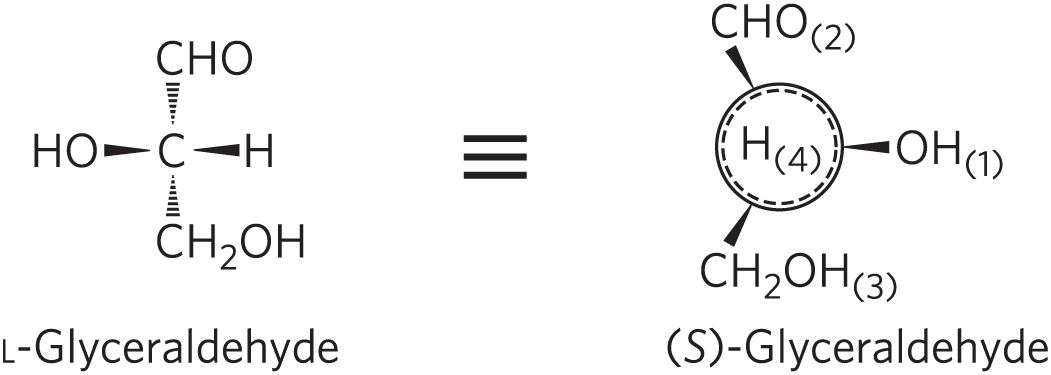

 When biomolecules interact, the “fit” between them is often stereochemically correct; they are complementary. The three-dimensional structure of biomolecules large and small — the combination of configuration and conformation — is of the utmost importance in their biological interactions: reactant with its enzyme, hormone with its receptor, antigen with its specific antibody, for example (
When biomolecules interact, the “fit” between them is often stereochemically correct; they are complementary. The three-dimensional structure of biomolecules large and small — the combination of configuration and conformation — is of the utmost importance in their biological interactions: reactant with its enzyme, hormone with its receptor, antigen with its specific antibody, for example (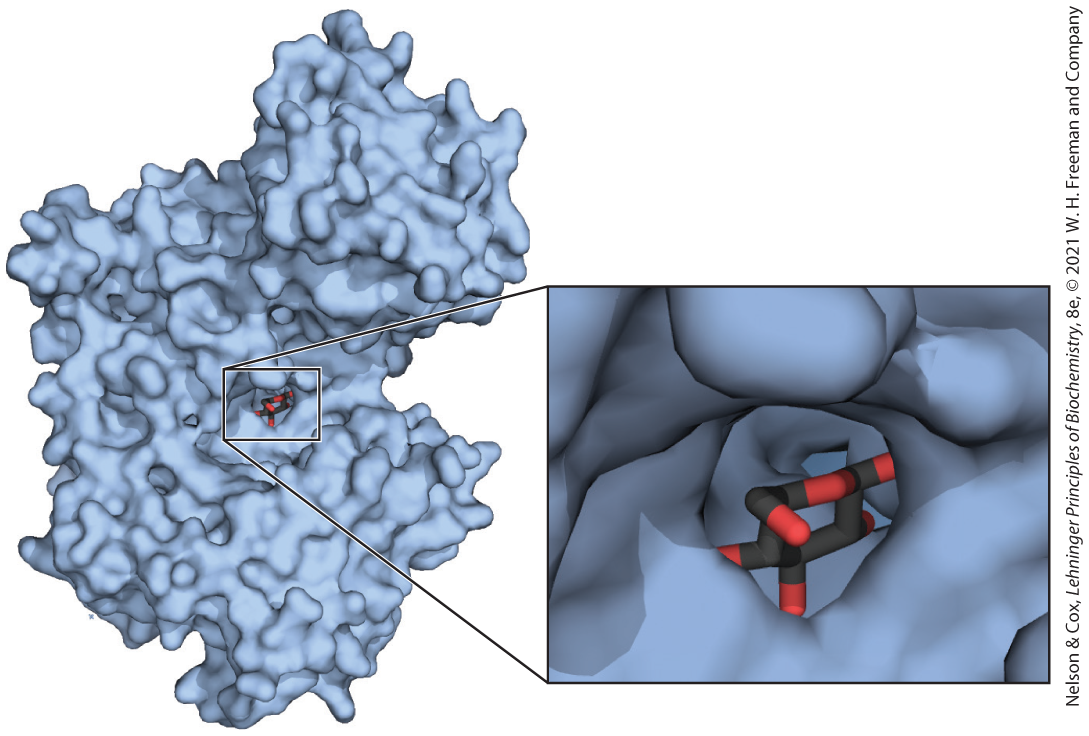
 Because of its bonding versatility, carbon can produce a broad array of carbon–carbon skeletons with a variety of functional groups; these groups give biomolecules their biological and chemical personalities.
Because of its bonding versatility, carbon can produce a broad array of carbon–carbon skeletons with a variety of functional groups; these groups give biomolecules their biological and chemical personalities.