1.4 Genetic Foundations
Perhaps the most remarkable property of living cells and organisms is their ability to reproduce themselves for countless generations with nearly perfect fidelity. This continuity of inherited traits implies constancy, over millions of years, in the structure of the molecules that contain the genetic information. Very few historical records of civilization, even those etched in copper or carved in stone (Fig. 1-29), have survived for a thousand years. But there is good evidence that the genetic instructions in living organisms have remained nearly unchanged over very much longer periods; many bacteria have nearly the same size, shape, and internal structure as bacteria that lived almost four billion years ago. This continuity of structure and composition is the result of continuity in the structure of the genetic material.
 Perhaps the most remarkable property of living cells and organisms is their ability to reproduce themselves for countless generations with nearly perfect fidelity. This continuity of inherited traits implies constancy, over millions of years, in the structure of the molecules that contain the genetic information. Very few historical records of civilization, even those etched in copper or carved in stone (
Perhaps the most remarkable property of living cells and organisms is their ability to reproduce themselves for countless generations with nearly perfect fidelity. This continuity of inherited traits implies constancy, over millions of years, in the structure of the molecules that contain the genetic information. Very few historical records of civilization, even those etched in copper or carved in stone (
FIGURE 1-29 Two ancient scripts. (a) The Prism of Sennacherib, inscribed in about 700 bce, describes in characters of the Assyrian language some historical events during the reign of King Sennacherib. The Prism contains about 20,000 characters, weighs about 50 kg, and has survived almost intact for about 2,700 years. (b) The single DNA molecule of the bacterium E. coli, leaking out of a disrupted cell, is hundreds of times longer than the cell itself and contains all the encoded information necessary to specify the cell’s structure and functions. The bacterial DNA contains about 4.6 million characters (nucleotides), weighs less than and has undergone only relatively minor changes during the past several million years. (The yellow spots and dark specks in this colorized electron micrograph are artifacts of the preparation.)
Among the seminal discoveries in biology in the twentieth century were the chemical nature and the three-dimensional structure of the genetic material, deoxyribonucleic acid, DNA. The sequence of the monomeric subunits, the nucleotides (strictly, deoxyribonucleotides, as discussed below), in this linear polymer encodes the instructions for forming all other cellular components and provides a template for the production of identical DNA molecules to be distributed to progeny when a cell divides.
 The sequence of the monomeric subunits, the nucleotides (strictly, deoxyribonucleotides, as discussed below), in this linear polymer encodes the instructions for forming all other cellular components and provides a template for the production of identical DNA molecules to be distributed to progeny when a cell divides.
The sequence of the monomeric subunits, the nucleotides (strictly, deoxyribonucleotides, as discussed below), in this linear polymer encodes the instructions for forming all other cellular components and provides a template for the production of identical DNA molecules to be distributed to progeny when a cell divides.Genetic Continuity Is Vested in Single DNA Molecules
DNA is a long, thin, organic polymer, the rare molecule that is constructed on the atomic scale in one dimension (width) and the human scale in another (length: a molecule of DNA can be many centimeters long). A human sperm or egg, carrying the accumulated hereditary information of billions of years of evolution, transmits this inheritance in the form of DNA molecules, in which the linear sequence of covalently linked nucleotide subunits encodes the genetic message.
Usually when we describe the properties of a chemical species, we describe the average behavior of a very large number of identical molecules. While it is difficult to predict the behavior of any single molecule in a collection of, say, a picomole (about ) of a compound, the average behavior of the molecules is predictable because so many molecules enter into the average. Cellular DNA is a remarkable exception. The DNA that is the entire genetic material of an E. coli cell is a single molecule containing 4.64 million nucleotide pairs. That single molecule must be replicated perfectly in every detail if an E. coli cell is to give rise to identical progeny by cell division; there is no room for averaging in this process! The same is true for all cells. A human sperm brings to the egg that it fertilizes just one molecule of DNA in each of its 23 different chromosomes, to combine with just one DNA molecule in each corresponding chromosome in the egg. The result of this union is highly predictable: an embryo with all of its ~20,000 genes, constructed of 3 billion nucleotide pairs, intact. An amazing chemical feat!
WORKED EXAMPLE 1-4 Fidelity of DNA Replication
Calculate the number of times the DNA of a modern E. coli cell has been copied accurately since its earliest bacterial precursor cell arose about 3.5 billion years ago. Assume for simplicity that over this time period, E. coli has undergone, on average, one cell division every 12 hours (this is an overestimate for modern bacteria, but probably an underestimate for ancient bacteria).
SOLUTION:
A single page of this book contains about 5,000 characters, so the entire book contains about 5 million characters. The chromosome of E. coli also contains about 5 million characters (nucleotide pairs). Imagine making a handwritten copy of this book and passing on the copy to a classmate, who copies it by hand and passes this second copy to a third classmate, who makes a third copy, and so on. How closely would each successive copy of the book resemble the original? Now, imagine the textbook that would result from hand-copying this one a few trillion times!
The Structure of DNA Allows Its Replication and Repair with Near-Perfect Fidelity
The capacity of living cells to preserve their genetic material and to duplicate it for the next generation results from the structural complementarity between the two strands of the DNA molecule (Fig. 1-30). The basic unit of DNA is a linear polymer of four different monomeric subunits, deoxyribonucleotides, arranged in a precise linear sequence. It is this linear sequence that encodes the genetic information. Two of these polymeric strands are twisted about each other to form the DNA double helix, in which each deoxyribonucleotide in one strand pairs specifically with a complementary deoxyribonucleotide in the opposite strand. Before a cell divides, the two DNA strands separate locally and each serves as a template for the synthesis of a new, complementary strand, generating two identical double-helical molecules, one for each daughter cell. If either strand is damaged at any time, continuity of information is assured by the information present in the other strand, which can act as a template for repair of the damage.
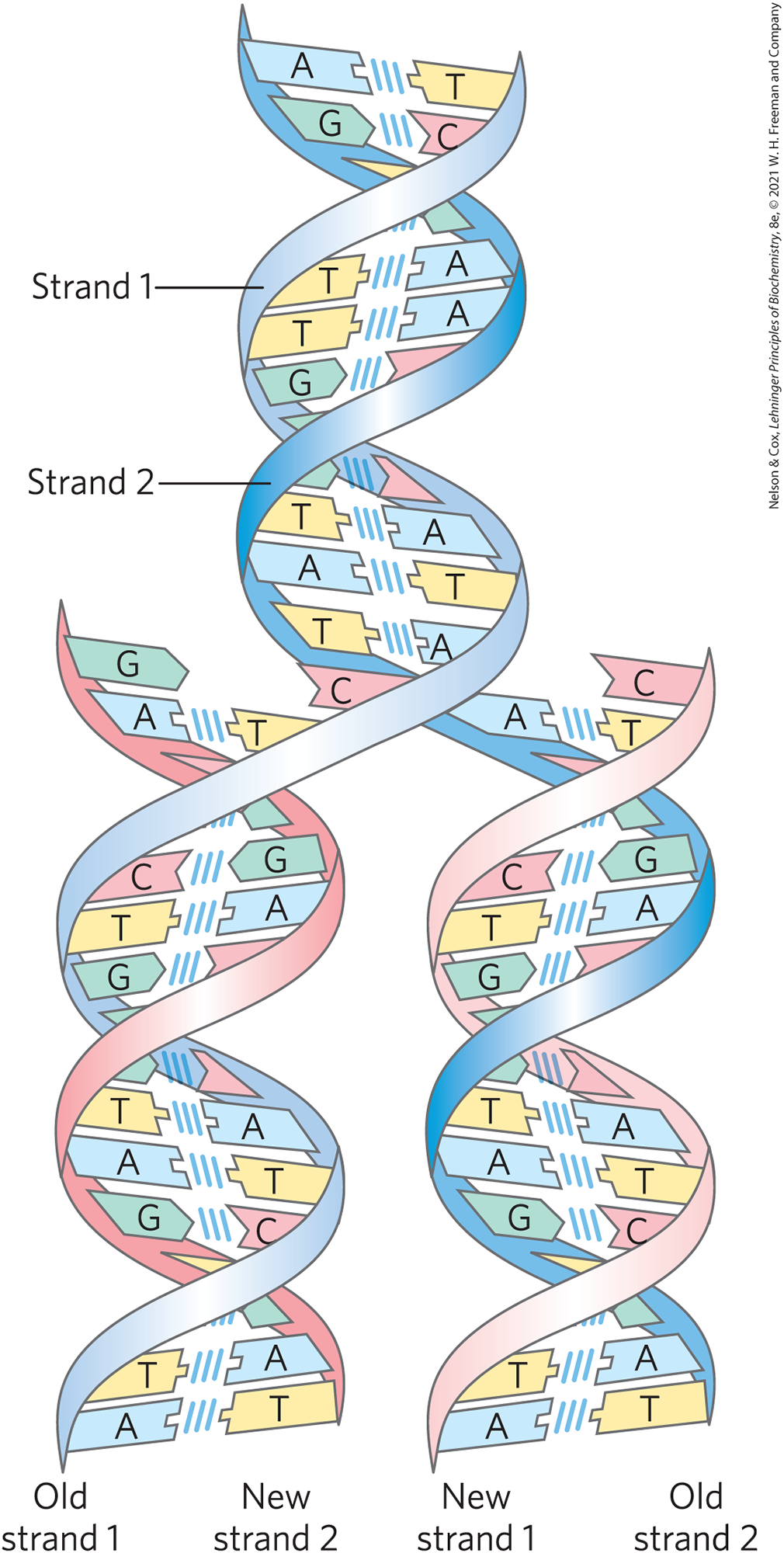
FIGURE 1-30 Complementarity between the two strands of DNA. DNA is a linear polymer of covalently joined deoxyribonucleotides of four types: deoxyadenylate (A), deoxyguanylate (G), deoxycytidylate (C), and deoxythymidylate (T). Each nucleotide, with its unique three-dimensional structure, can associate very specifically but noncovalently with one other nucleotide in the complementary chain: A always associates with T, and G with C. Thus, in the double-stranded DNA molecule, the entire sequence of nucleotides in one strand is complementary to the sequence in the other. The two strands, held together by hydrogen bonds (represented here by vertical light blue lines) between each pair of complementary nucleotides, twist about each other to form the DNA double helix. In DNA replication, the two strands (blue) separate and two new strands (pink) are synthesized, each with a sequence complementary to one of the original strands. The result is two double-helical molecules, each identical to the original DNA.
The Linear Sequence in DNA Encodes Proteins with Three-Dimensional Structures
The information in DNA is encoded in its linear (one-dimensional) sequence of deoxyribonucleotide subunits, but the expression of this information results in a three-dimensional cell. This change from one to three dimensions occurs in two phases. A linear sequence of deoxyribonucleotides in DNA codes (through an intermediary, RNA) for the production of a protein with a corresponding linear sequence of amino acids (Fig. 1-31). The protein folds into a particular three-dimensional shape, determined by its amino acid sequence and stabilized primarily by noncovalent interactions. Although the final shape of the folded protein is dictated by its amino acid sequence, the folding of many proteins is aided by “molecular chaperones” (see Fig. 4-28). The precise three-dimensional structure, or native conformation, of the protein is crucial to its function.
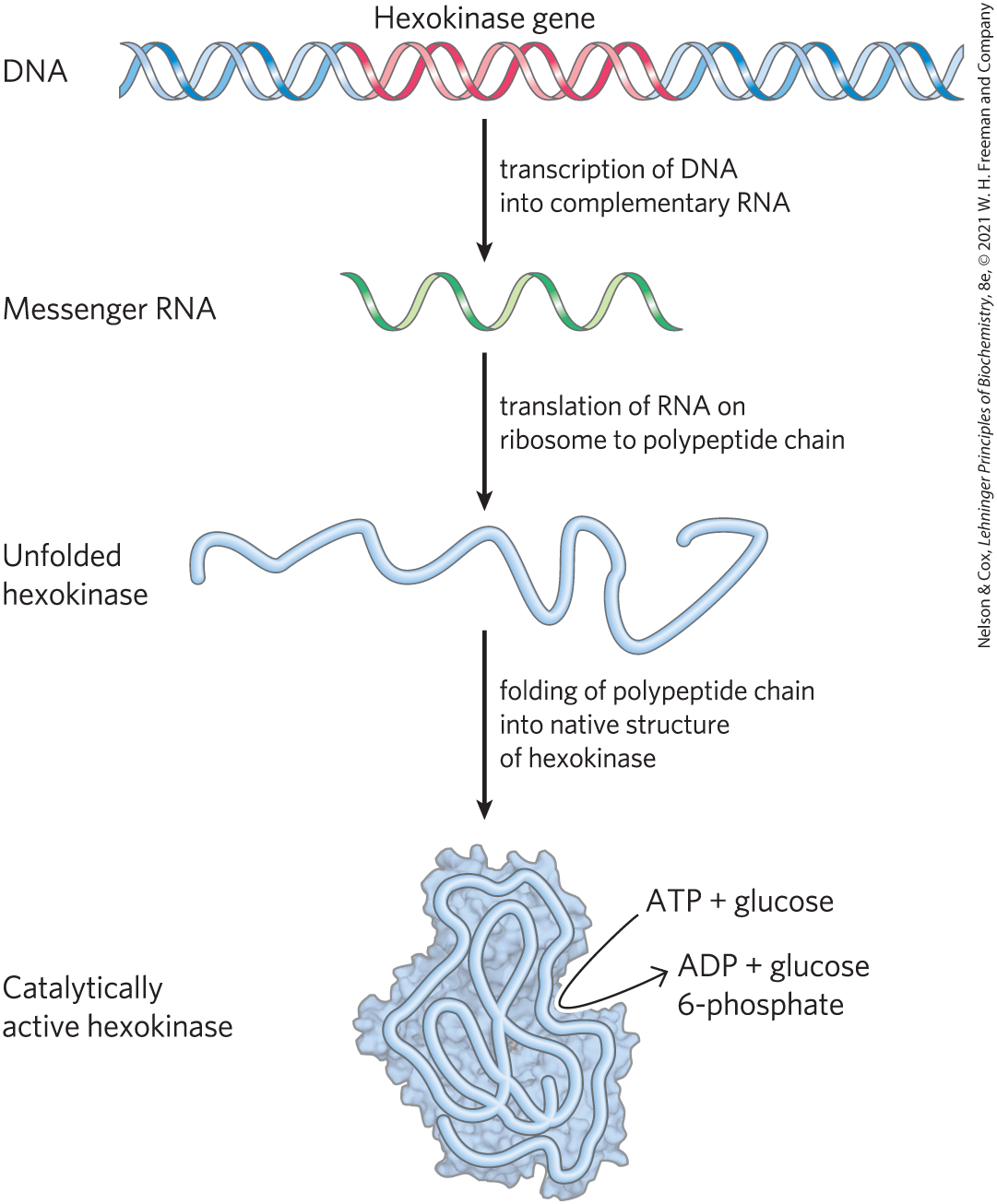
FIGURE 1-31 DNA to RNA to protein to enzyme (hexokinase). The linear sequence of deoxyribonucleotides in the DNA (the gene) that encodes the protein hexokinase is first transcribed into a ribonucleic acid (RNA) molecule with the complementary ribonucleotide sequence. The RNA sequence (messenger RNA) is then translated into the linear protein chain of hexokinase, which folds into its native three-dimensional shape, most likely aided by molecular chaperones. Once in its native form, hexokinase acquires its catalytic activity: it can catalyze the phosphorylation of glucose, using ATP as the phosphoryl group donor.
Once in its native conformation, a protein may associate noncovalently with other macromolecules (other proteins, nucleic acids, or lipids) to form supramolecular complexes such as chromosomes, ribosomes, and membranes. The individual molecules of these complexes have specific, high-affinity binding sites for each other, and within the cell they spontaneously self-assemble into functional complexes.
Although the amino acid sequences of proteins carry all necessary information for achieving the proteins’ native conformation, accurate folding and self-assembly also require the right cellular environment — pH, ionic strength, metal ion concentrations, and so forth. Thus, DNA sequence alone is not enough to form and maintain a fully functioning cell.
SUMMARY 1.4 Genetic Foundations
- Genetic information is encoded in the linear sequence of four types of deoxyribonucleotides in DNA.
- Despite the enormous size of DNA, the sequence of its nucleotides is very precise, and the maintenance of this precise sequence over very long times is the basis for genetic continuity in organisms.
- The double-helical DNA molecule contains an internal template for its own replication and repair.
- The linear sequence of amino acids in a protein, which is encoded in the DNA of the gene for that protein, produces a protein’s unique three-dimensional structure — a process that is also dependent on environmental conditions.
- Individual macromolecules with specific affinity for other macromolecules self-assemble into supramolecular complexes.
 Genetic information is encoded in the linear sequence of four types of deoxyribonucleotides in DNA.
Genetic information is encoded in the linear sequence of four types of deoxyribonucleotides in DNA.